 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusePose: IMU-Vision Sensor Fusion in Kinematic Space for Parametric Human Pose Estimation
Paper and Code
Aug 25, 2022
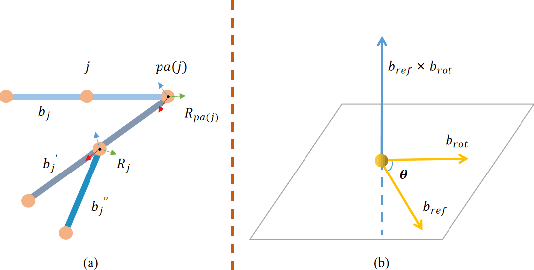


There exist challenging problems in 3D human pose estimation mission, such as poor performance caused by occlusion and self-occlusion. Recently, IMU-vision sensor fusion is regarded as valuable for solving these problems. However, previous researches on the fusion of IMU and vision data, which is heterogeneous, fail to adequately utilize either IMU raw data or reliable high-level vision features. To facilitate a more efficient sensor fusion, in this work we propose a framework called \emph{FusePose} under a parametric human kinematic model. Specifically, we aggregate different information of IMU or vision data and introduce three distinctive sensor fusion approaches: NaiveFuse, KineFuse and AdaDeepFuse. NaiveFuse servers as a basic approach that only fuses simplified IMU data and estimated 3D pose in euclidean space. While in kinematic space, KineFuse is able to integrate the calibrated and aligned IMU raw data with converted 3D pose parameters. AdaDeepFuse further develops this kinematical fusion process to an adaptive and end-to-end trainable manner. Comprehensive experiments with ablation studies demonstrate the rationality and superiority of the proposed framework. The performance of 3D human pose estimation is improved compared to the baseline result. On Total Capture dataset, KineFuse surpasses previous state-of-the-art which uses IMU only for testing by 8.6\%. AdaDeepFuse surpasses state-of-the-art which uses IMU for both training and testing by 8.5\%. Moreover, we validate the generalization capability of our framework through experiments on Human3.6M dataset.