 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTMFN: Two-stream Transformer-based Multimodal Fusion Network for Survival Prediction
Nov 13, 2023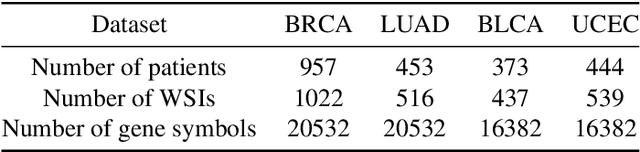
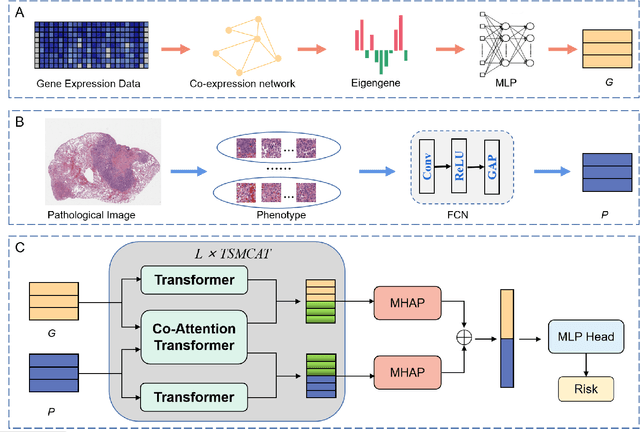
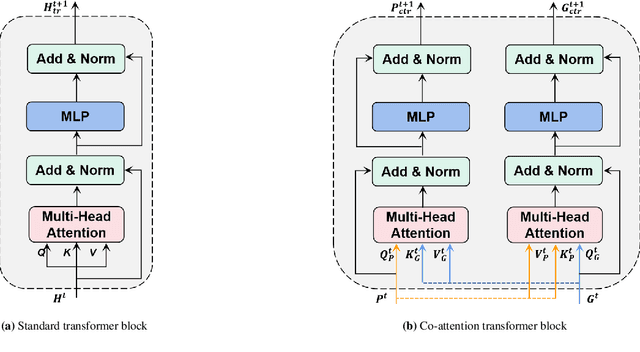
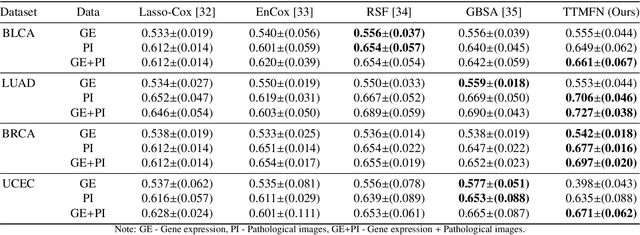
Survival prediction plays a crucial role in assisting clinicians with the development of cancer treatment protocols. Recent evidence shows that multimodal data can help in the diagnosis of cancer disease and improve survival prediction. Currently, deep learning-based approaches have experienced increasing success in survival prediction by integrating pathological images and gene expression data. However, most existing approaches overlook the intra-modality latent information and the complex inter-modality correlations. Furthermore, existing modalities do not fully exploit the immense representational capabilities of neural networks for feature aggregation and disregard the importance of relationships between features. Therefore, it is highly recommended to address these issues in order to enhance the prediction performance by proposing a novel deep learning-based method. We propose a novel framework named Two-stream Transformer-based Multimodal Fusion Network for survival prediction (TTMFN), which integrates pathological images and gene expression data. In TTMFN, we present a two-stream multimodal co-attention transformer module to take full advantage of the complex relationships between different modalities and the potential connections within the modalities. Additionally, we develop a multi-head attention pooling approach to effectively aggregate the feature representations of the two modalities. The experiment results on four datasets from The Cancer Genome Atlas demonstrate that TTMFN can achieve the best performance or competitive results compared to the state-of-the-art methods in predicting the overall survival of patients.
Self-Adaptive Transfer Learning for Multicenter Glaucoma Classification in Fundus Retina Images
May 07, 2021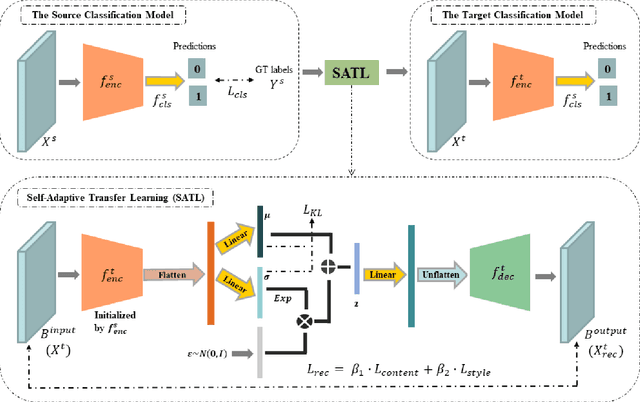
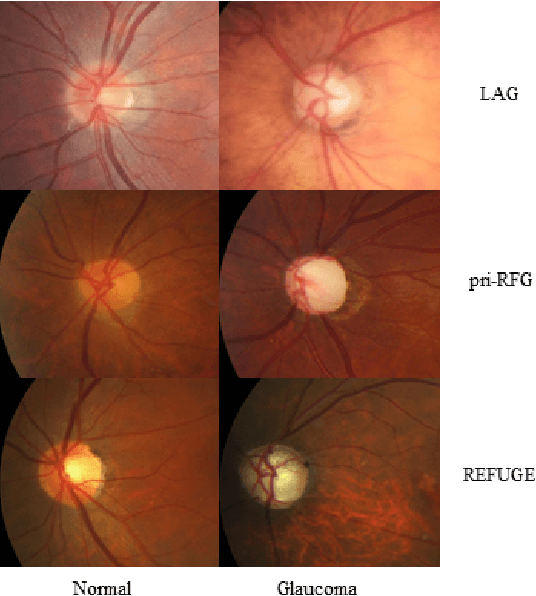
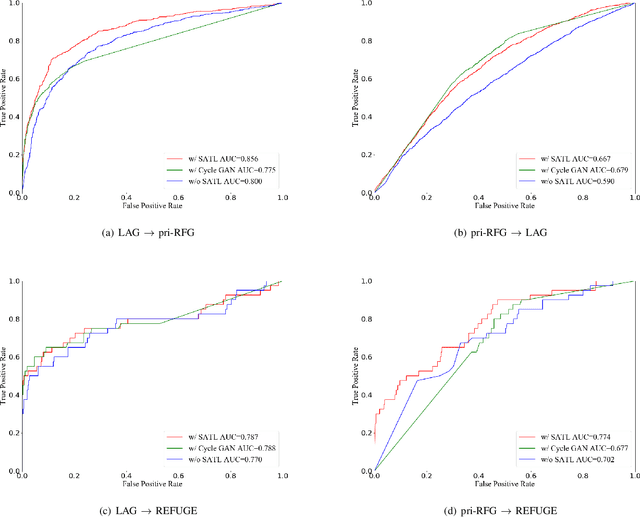
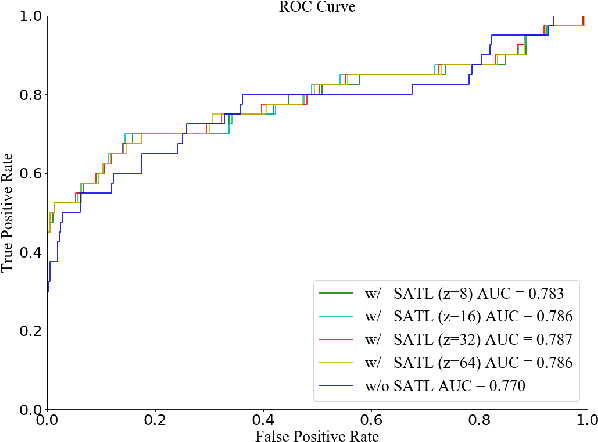
The early diagnosis and screening of glaucoma are important for patients to receive treatment in time and maintain eyesight. Nowadays, deep learning (DL) based models have been successfully used for computer-aided diagnosis (CAD) of glaucoma from retina fundus images. However, a DL model pre-trained using a dataset from one hospital center may have poor performance on a dataset from another new hospital center and therefore its applications in the real scene are limited. In this paper, we propose a self-adaptive transfer learning (SATL) strategy to fill the domain gap between multicenter datasets. Specifically, the encoder of a DL model that is pre-trained on the source domain is used to initialize the encoder of a reconstruction model. Then, the reconstruction model is trained using only unlabeled image data from the target domain, which makes the encoder in the model adapt itself to extract useful high-level features both for target domain images encoding and glaucoma classification, simultaneously. Experimental results demonstrate that the proposed SATL strategy is effective in the domain adaptation task between a private and two public glaucoma diagnosis datasets, i.e. pri-RFG, REFUGE, and LAG. Moreover, the proposed strategy is completely independent of the source domain data, which meets the real scene application and the privacy protection policy.