 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025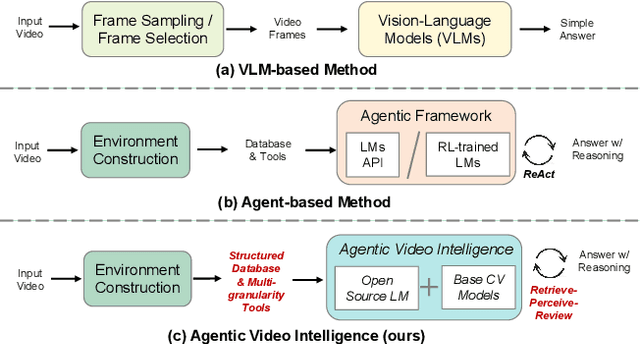
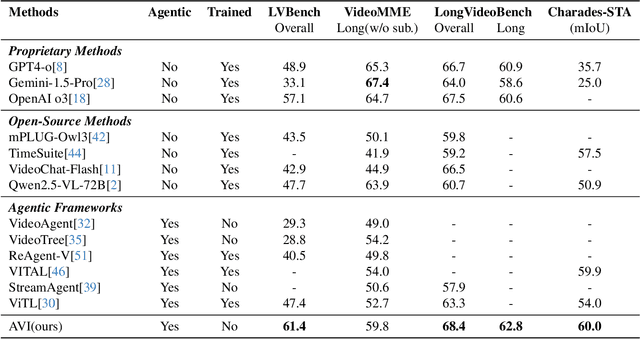
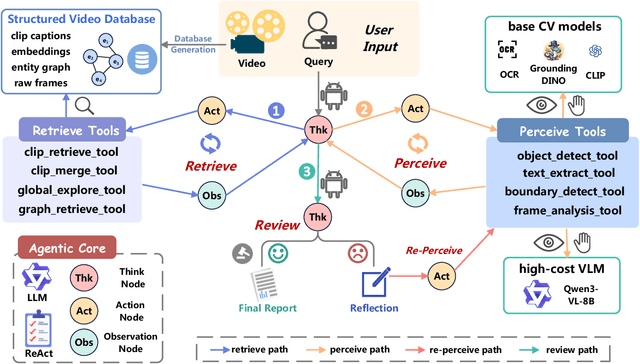
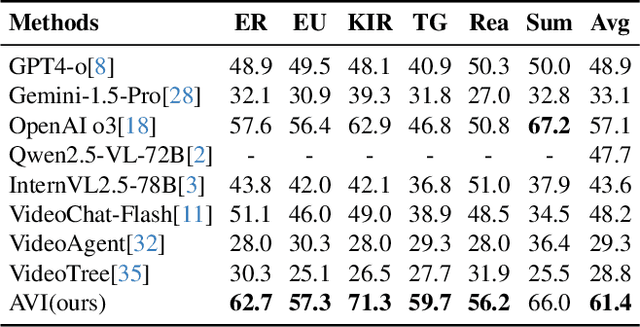
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval
Jun 05, 2025Current video-based multimodal large language models struggle with hour-level video understanding due to computational constraints and inefficient information extraction from extensive temporal sequences. We propose APVR (Adaptive Pivot Visual information Retrieval), a training-free framework that addresses the memory wall limitation through hierarchical visual information retrieval. APVR operates via two complementary components: Pivot Frame Retrieval employs semantic expansion and multi-modal confidence scoring to identify semantically relevant video frames, while Pivot Token Retrieval performs query-aware attention-driven token selection within the pivot frames. This dual granularity approach enables processing of hour-long videos while maintaining semantic fidelity. Experimental validation on LongVideoBench and VideoMME demonstrates significant performance improvements, establishing state-of-the-art results for not only training-free but also training-based approaches while providing plug-and-play integration capability with existing MLLM architectures.
CLS: Cross Labeling Supervision for Semi-Supervised Learning
Feb 17, 2022
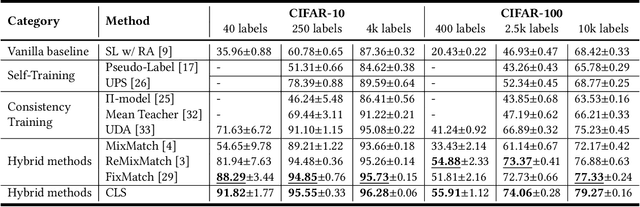

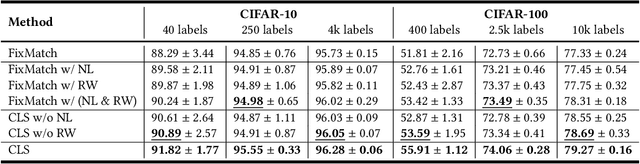
It is well known that the success of deep neural networks is greatly attributed to large-scale labeled datasets. However, it can be extremely time-consuming and laborious to collect sufficient high-quality labeled data in most practical applications. Semi-supervised learning (SSL) provides an effective solution to reduce the cost of labeling by simultaneously leveraging both labeled and unlabeled data. In this work, we present Cross Labeling Supervision (CLS), a framework that generalizes the typical pseudo-labeling process. Based on FixMatch, where a pseudo label is generated from a weakly-augmented sample to teach the prediction on a strong augmentation of the same input sample, CLS allows the creation of both pseudo and complementary labels to support both positive and negative learning. To mitigate the confirmation bias of self-labeling and boost the tolerance to false labels, two different initialized networks with the same structure are trained simultaneously. Each network utilizes high-confidence labels from the other network as additional supervision signals. During the label generation phase, adaptive sample weights are assigned to artificial labels according to their prediction confidence. The sample weight plays two roles: quantify the generated labels' quality and reduce the disruption of inaccurate labels on network training. Experimental results on the semi-supervised classification task show that our framework outperforms existing approaches by large margins on the CIFAR-10 and CIFAR-100 datasets.
Weak Supervision for Fake News Detection via Reinforcement Learning
Jan 20, 2020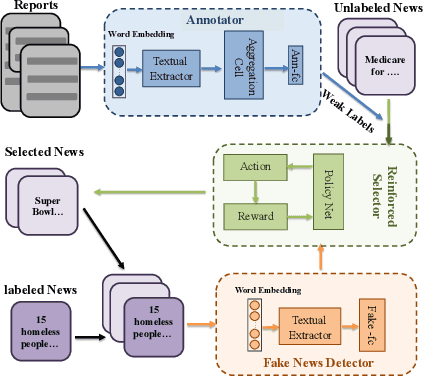
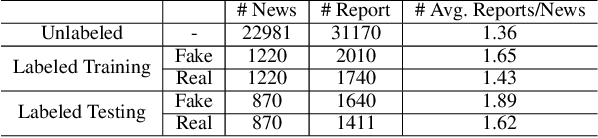
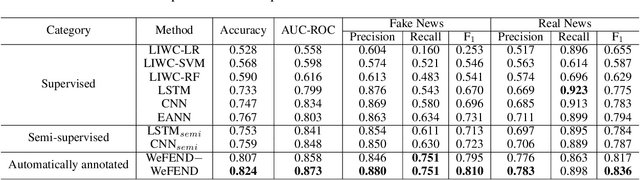
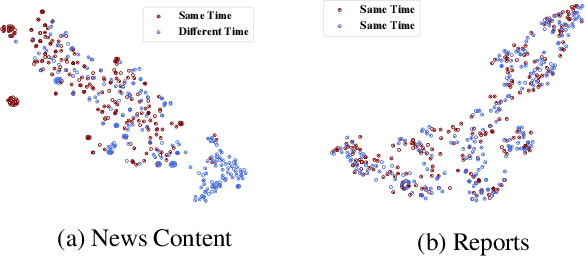
Today social media has become the primary source for news. Via social media platforms, fake news travel at unprecedented speeds, reach global audiences and put users and communities at great risk. Therefore, it is extremely important to detect fake news as early as possible. Recently, deep learning based approaches have shown improved performance in fake news detection. However, the training of such models requires a large amount of labeled data, but manual annotation is time-consuming and expensive. Moreover, due to the dynamic nature of news, annotated samples may become outdated quickly and cannot represent the news articles on newly emerged events. Therefore, how to obtain fresh and high-quality labeled samples is the major challenge in employing deep learning models for fake news detection. In order to tackle this challenge, we propose a reinforced weakly-supervised fake news detection framework, i.e., WeFEND, which can leverage users' reports as weak supervision to enlarge the amount of training data for fake news detection. The proposed framework consists of three main components: the annotator, the reinforced selector and the fake news detector. The annotator can automatically assign weak labels for unlabeled news based on users' reports. The reinforced selector using reinforcement learning techniques chooses high-quality samples from the weakly labeled data and filters out those low-quality ones that may degrade the detector's prediction performance. The fake news detector aims to identify fake news based on the news content. We tested the proposed framework on a large collection of news articles published via WeChat official accounts and associated user reports. Extensive experiments on this dataset show that the proposed WeFEND model achieves the best performance compared with the state-of-the-art methods.
Transfer Value Iteration Networks
Nov 27, 2019

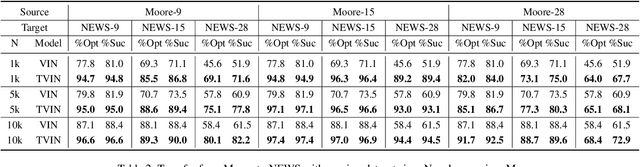

Value iteration networks (VINs) have been demonstrated to have a good generalization ability for reinforcement learning tasks across similar domains. However, based on our experiments, a policy learned by VINs still fail to generalize well on the domain whose action space and feature space are not identical to those in the domain where it is trained. In this paper, we propose a transfer learning approach on top of VINs, termed Transfer VINs (TVINs), such that a learned policy from a source domain can be generalized to a target domain with only limited training data, even if the source domain and the target domain have domain-specific actions and features. We empirically verify that our proposed TVINs outperform VINs when the source and the target domains have similar but not identical action and feature spaces. Furthermore, we show that the performance improvement is consistent across different environments, maze sizes, dataset sizes as well as different values of hyperparameters such as number of iteration and kernel size.