 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022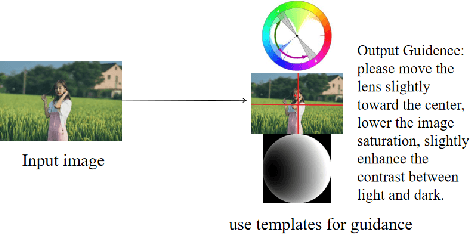
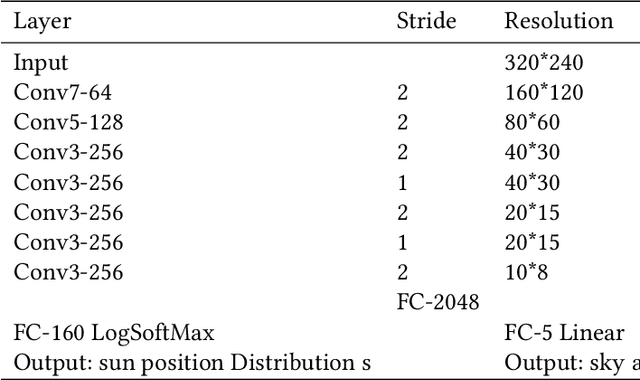

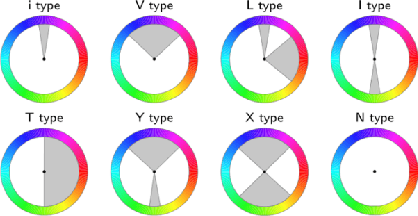
With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
Attribute Controllable Beautiful Caucasian Face Generation by Aesthetics Driven Reinforcement Learning
Aug 09, 2022



In recent years, image generation has made great strides in improving the quality of images, producing high-fidelity ones. Also, quite recently, there are architecture designs, which enable GAN to unsupervisedly learn the semantic attributes represented in different layers. However, there is still a lack of research on generating face images more consistent with human aesthetics. Based on EigenGAN [He et al., ICCV 2021], we build the techniques of reinforcement learning into the generator of EigenGAN. The agent tries to figure out how to alter the semantic attributes of the generated human faces towards more preferable ones. To accomplish this, we trained an aesthetics scoring model that can conduct facial beauty prediction. We also can utilize this scoring model to analyze the correlation between face attributes and aesthetics scores. Empirically, using off-the-shelf techniques from reinforcement learning would not work well. So instead, we present a new variant incorporating the ingredients emerging in the reinforcement learning communities in recent years. Compared to the original generated images, the adjusted ones show clear distinctions concerning various attributes. Experimental results using the MindSpore, show the effectiveness of the proposed method. Altered facial images are commonly more attractive, with significantly improved aesthetic levels.
Aesthetic Attribute Assessment of Images Numerically on Mixed Multi-attribute Datasets
Jul 05, 2022

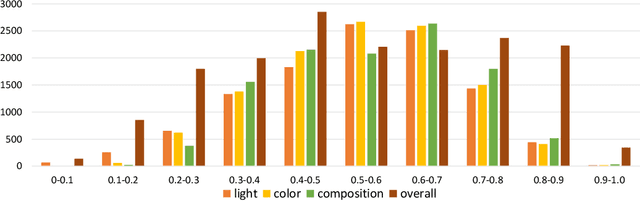

With the continuous development of social software and multimedia technology, images have become a kind of important carrier for spreading information and socializing. How to evaluate an image comprehensively has become the focus of recent researches. The traditional image aesthetic assessment methods often adopt single numerical overall assessment scores, which has certain subjectivity and can no longer meet the higher aesthetic requirements. In this paper, we construct an new image attribute dataset called aesthetic mixed dataset with attributes(AMD-A) and design external attribute features for fusion. Besides, we propose a efficient method for image aesthetic attribute assessment on mixed multi-attribute dataset and construct a multitasking network architecture by using the EfficientNet-B0 as the backbone network. Our model can achieve aesthetic classification, overall scoring and attribute scoring. In each sub-network, we improve the feature extraction through ECA channel attention module. As for the final overall scoring, we adopt the idea of the teacher-student network and use the classification sub-network to guide the aesthetic overall fine-grain regression. Experimental results, using the MindSpore, show that our proposed method can effectively improve the performance of the aesthetic overall and attribute assessment.
Cognitive Representation Learning of Self-Media Online Article Quality
Aug 13, 2020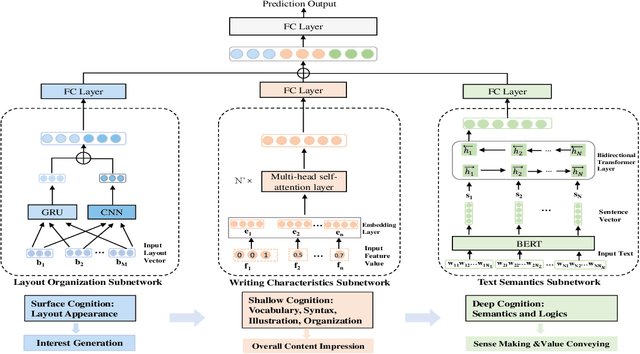
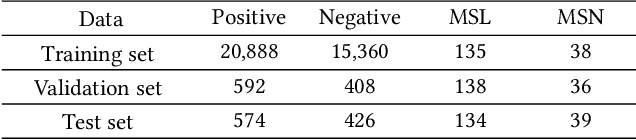
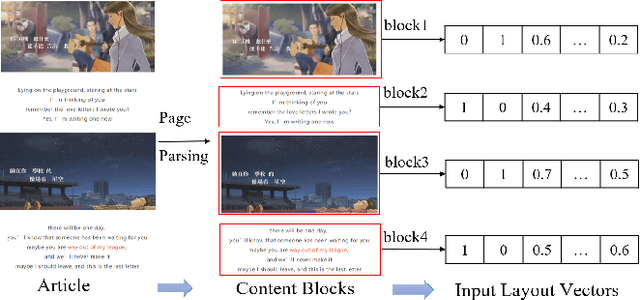

The automatic quality assessment of self-media online articles is an urgent and new issue, which is of great value to the online recommendation and search. Different from traditional and well-formed articles, self-media online articles are mainly created by users, which have the appearance characteristics of different text levels and multi-modal hybrid editing, along with the potential characteristics of diverse content, different styles, large semantic spans and good interactive experience requirements. To solve these challenges, we establish a joint model CoQAN in combination with the layout organization, writing characteristics and text semantics, designing different representation learning subnetworks, especially for the feature learning process and interactive reading habits on mobile terminals. It is more consistent with the cognitive style of expressing an expert's evaluation of articles. We have also constructed a large scale real-world assessment dataset. Extensive experimental results show that the proposed framework significantly outperforms state-of-the-art methods, and effectively learns and integrates different factors of the online article quality assessment.
Weak Supervision for Fake News Detection via Reinforcement Learning
Jan 20, 2020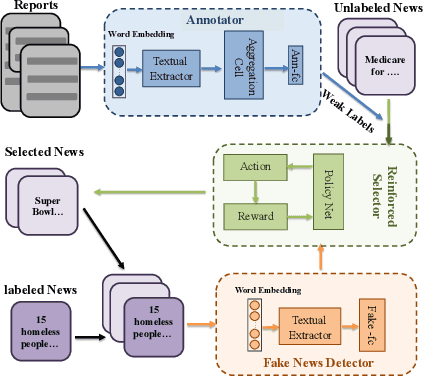
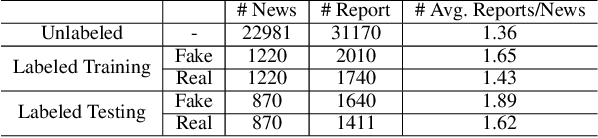
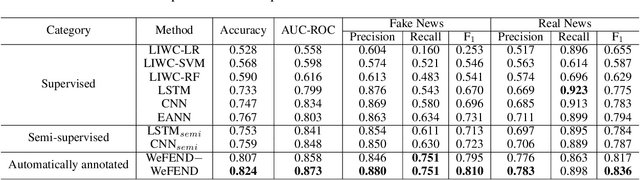
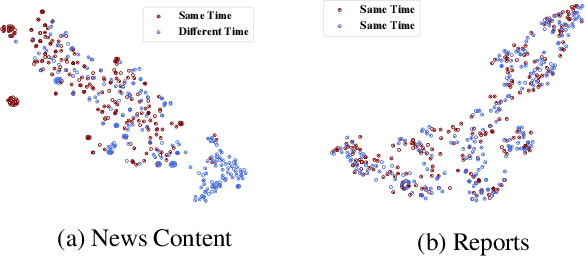
Today social media has become the primary source for news. Via social media platforms, fake news travel at unprecedented speeds, reach global audiences and put users and communities at great risk. Therefore, it is extremely important to detect fake news as early as possible. Recently, deep learning based approaches have shown improved performance in fake news detection. However, the training of such models requires a large amount of labeled data, but manual annotation is time-consuming and expensive. Moreover, due to the dynamic nature of news, annotated samples may become outdated quickly and cannot represent the news articles on newly emerged events. Therefore, how to obtain fresh and high-quality labeled samples is the major challenge in employing deep learning models for fake news detection. In order to tackle this challenge, we propose a reinforced weakly-supervised fake news detection framework, i.e., WeFEND, which can leverage users' reports as weak supervision to enlarge the amount of training data for fake news detection. The proposed framework consists of three main components: the annotator, the reinforced selector and the fake news detector. The annotator can automatically assign weak labels for unlabeled news based on users' reports. The reinforced selector using reinforcement learning techniques chooses high-quality samples from the weakly labeled data and filters out those low-quality ones that may degrade the detector's prediction performance. The fake news detector aims to identify fake news based on the news content. We tested the proposed framework on a large collection of news articles published via WeChat official accounts and associated user reports. Extensive experiments on this dataset show that the proposed WeFEND model achieves the best performance compared with the state-of-the-art methods.