 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Temporal Difference Transformer for Video-Text Retrieval
Jun 23, 2024

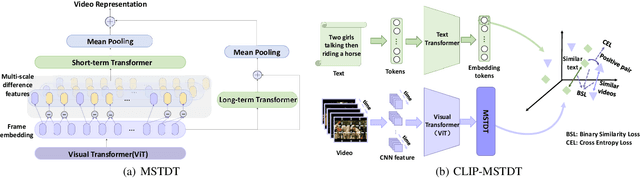
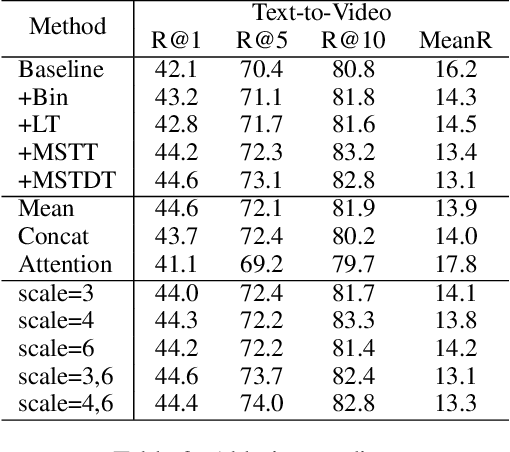
Currently, in the field of video-text retrieval, there are many transformer-based methods. Most of them usually stack frame features and regrade frames as tokens, then use transformers for video temporal modeling. However, they commonly neglect the inferior ability of the transformer modeling local temporal information. To tackle this problem, we propose a transformer variant named Multi-Scale Temporal Difference Transformer (MSTDT). MSTDT mainly addresses the defects of the traditional transformer which has limited ability to capture local temporal information. Besides, in order to better model the detailed dynamic information, we make use of the difference feature between frames, which practically reflects the dynamic movement of a video. We extract the inter-frame difference feature and integrate the difference and frame feature by the multi-scale temporal transformer. In general, our proposed MSTDT consists of a short-term multi-scale temporal difference transformer and a long-term temporal transformer. The former focuses on modeling local temporal information, the latter aims at modeling global temporal information. At last, we propose a new loss to narrow the distance of similar samples. Extensive experiments show that backbone, such as CLIP, with MSTDT has attained a new state-of-the-art result.
Keyword-Based Diverse Image Retrieval by Semantics-aware Contrastive Learning and Transformer
May 06, 2023



In addition to relevance, diversity is an important yet less studied performance metric of cross-modal image retrieval systems, which is critical to user experience. Existing solutions for diversity-aware image retrieval either explicitly post-process the raw retrieval results from standard retrieval systems or try to learn multi-vector representations of images to represent their diverse semantics. However, neither of them is good enough to balance relevance and diversity. On the one hand, standard retrieval systems are usually biased to common semantics and seldom exploit diversity-aware regularization in training, which makes it difficult to promote diversity by post-processing. On the other hand, multi-vector representation methods are not guaranteed to learn robust multiple projections. As a result, irrelevant images and images of rare or unique semantics may be projected inappropriately, which degrades the relevance and diversity of the results generated by some typical algorithms like top-k. To cope with these problems, this paper presents a new method called CoLT that tries to generate much more representative and robust representations for accurately classifying images. Specifically, CoLT first extracts semantics-aware image features by enhancing the preliminary representations of an existing one-to-one cross-modal system with semantics-aware contrastive learning. Then, a transformer-based token classifier is developed to subsume all the features into their corresponding categories. Finally, a post-processing algorithm is designed to retrieve images from each category to form the final retrieval result. Extensive experiments on two real-world datasets Div400 and Div150Cred show that CoLT can effectively boost diversity, and outperforms the existing methods as a whole (with a higher F1 score).
Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
Feb 10, 2022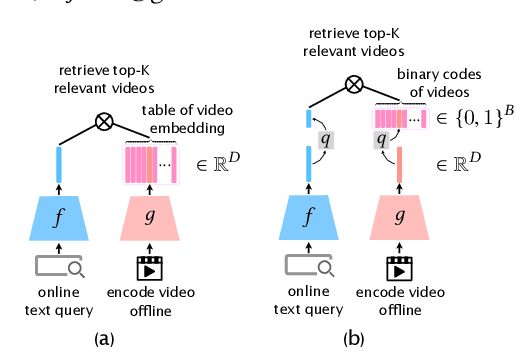
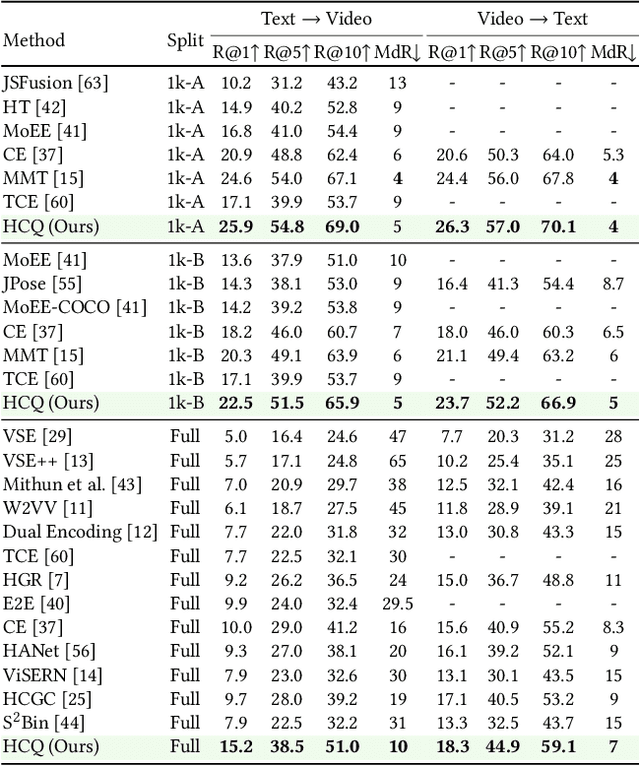
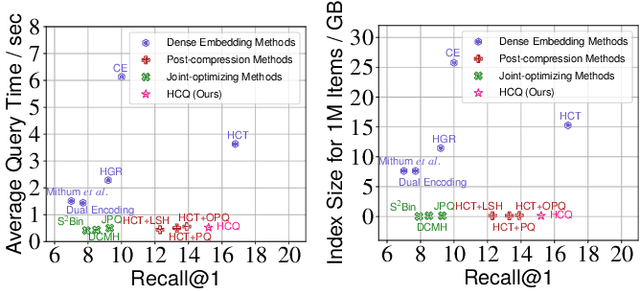

With the recent boom of video-based social platforms (e.g., YouTube and TikTok), video retrieval using sentence queries has become an important demand and attracts increasing research attention. Despite the decent performance, existing text-video retrieval models in vision and language communities are impractical for large-scale Web search because they adopt brute-force search based on high-dimensional embeddings. To improve efficiency, Web search engines widely apply vector compression libraries (e.g., FAISS) to post-process the learned embeddings. Unfortunately, separate compression from feature encoding degrades the robustness of representations and incurs performance decay. To pursue a better balance between performance and efficiency, we propose the first quantized representation learning method for cross-view video retrieval, namely Hybrid Contrastive Quantization (HCQ). Specifically, HCQ learns both coarse-grained and fine-grained quantizations with transformers, which provide complementary understandings for texts and videos and preserve comprehensive semantic information. By performing Asymmetric-Quantized Contrastive Learning (AQ-CL) across views, HCQ aligns texts and videos at coarse-grained and multiple fine-grained levels. This hybrid-grained learning strategy serves as strong supervision on the cross-view video quantization model, where contrastive learning at different levels can be mutually promoted. Extensive experiments on three Web video benchmark datasets demonstrate that HCQ achieves competitive performance with state-of-the-art non-compressed retrieval methods while showing high efficiency in storage and computation. Code and configurations are available at https://github.com/gimpong/WWW22-HCQ.
Cognitive Representation Learning of Self-Media Online Article Quality
Aug 13, 2020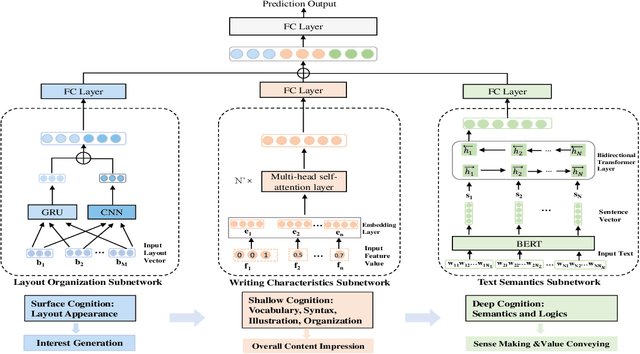
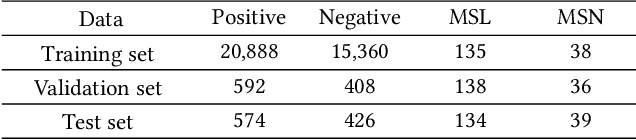
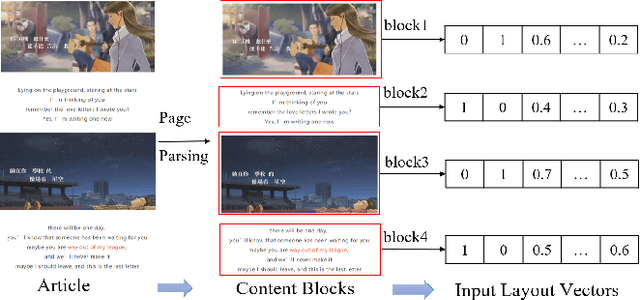

The automatic quality assessment of self-media online articles is an urgent and new issue, which is of great value to the online recommendation and search. Different from traditional and well-formed articles, self-media online articles are mainly created by users, which have the appearance characteristics of different text levels and multi-modal hybrid editing, along with the potential characteristics of diverse content, different styles, large semantic spans and good interactive experience requirements. To solve these challenges, we establish a joint model CoQAN in combination with the layout organization, writing characteristics and text semantics, designing different representation learning subnetworks, especially for the feature learning process and interactive reading habits on mobile terminals. It is more consistent with the cognitive style of expressing an expert's evaluation of articles. We have also constructed a large scale real-world assessment dataset. Extensive experimental results show that the proposed framework significantly outperforms state-of-the-art methods, and effectively learns and integrates different factors of the online article quality assessment.