 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
May 07, 2026In recent years, open-source efforts like Senorita-2M have propelled video editing toward natural language instruction. However, current publicly available datasets predominantly focus on local editing or style transfer, which largely preserve the original scene structure and are easier to scale. In contrast, Background Replacement, a task central to creative applications such as film production and advertising, requires synthesizing entirely new, temporally consistent scenes while maintaining accurate foreground-background interactions, making large-scale data generation significantly more challenging. Consequently, this complex task remains largely underexplored due to a scarcity of high-quality training data. This gap is evident in poorly performing state-of-the-art models, e.g., Kiwi-Edit, because the primary open-source dataset that contains this task, i.e., OpenVE-3M, frequently produces static, unnatural backgrounds. In this paper, we trace this quality degradation to a lack of precise background guidance during data synthesis. Accordingly, we design a scalable pipeline that generates foreground and background guidance in a decoupled manner with strict quality filtering. Building on this pipeline, we introduce Sparkle, a dataset of ~140K video pairs spanning five common background-change themes, alongside Sparkle-Bench, the largest evaluation benchmark tailored for background replacement to date. Experiments demonstrate that our dataset and the model trained on it achieve substantially better performance than all existing baselines on both OpenVE-Bench and Sparkle-Bench. Our proposed dataset, benchmark, and model are fully open-sourced at https://showlab.github.io/Sparkle/.
Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Mar 05, 2026Instruction-based video editing has witnessed rapid progress, yet current methods often struggle with precise visual control, as natural language is inherently limited in describing complex visual nuances. Although reference-guided editing offers a robust solution, its potential is currently bottlenecked by the scarcity of high-quality paired training data. To bridge this gap, we introduce a scalable data generation pipeline that transforms existing video editing pairs into high-fidelity training quadruplets, leveraging image generative models to create synthesized reference scaffolds. Using this pipeline, we construct RefVIE, a large-scale dataset tailored for instruction-reference-following tasks, and establish RefVIE-Bench for comprehensive evaluation. Furthermore, we propose a unified editing architecture, Kiwi-Edit, that synergizes learnable queries and latent visual features for reference semantic guidance. Our model achieves significant gains in instruction following and reference fidelity via a progressive multi-stage training curriculum. Extensive experiments demonstrate that our data and architecture establish a new state-of-the-art in controllable video editing. All datasets, models, and code is released at https://github.com/showlab/Kiwi-Edit.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025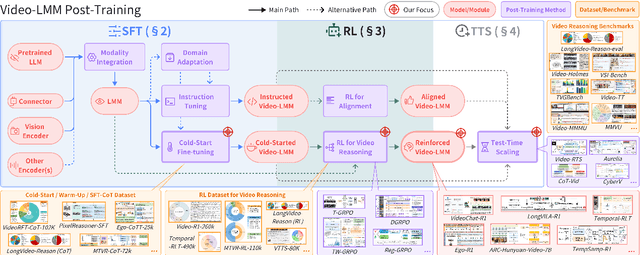
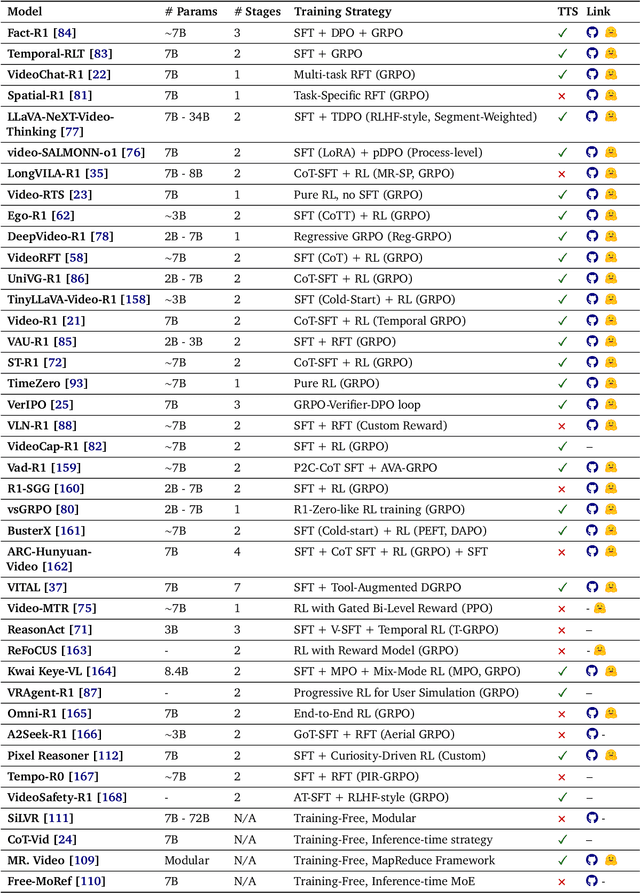
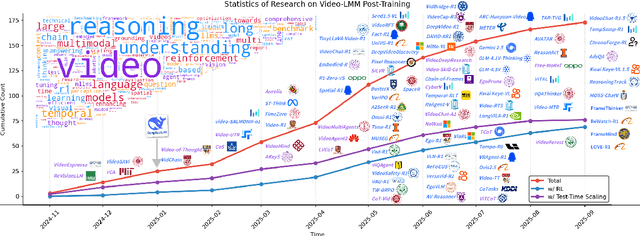
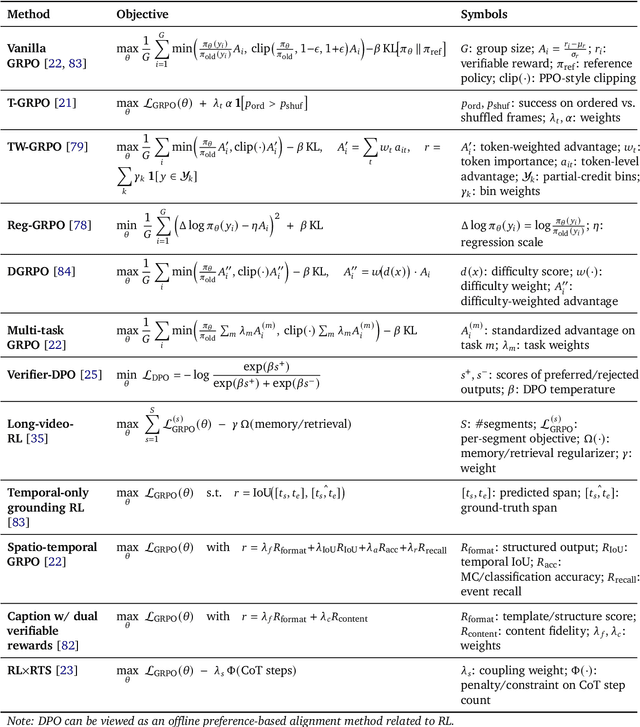
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
Apr 22, 2025
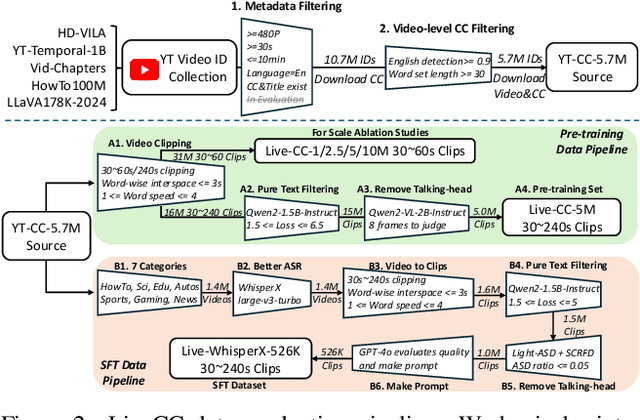
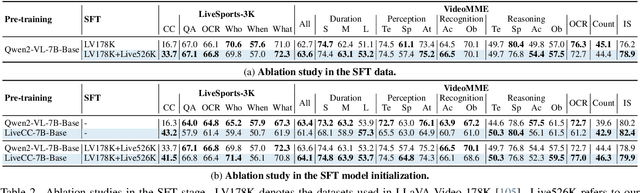
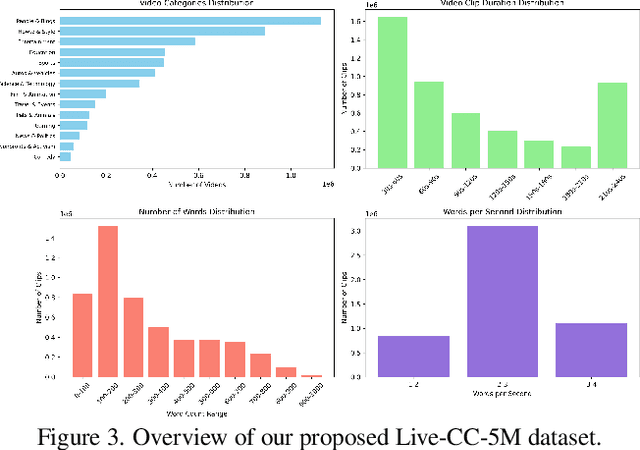
Recent video large language models (Video LLMs) often depend on costly human annotations or proprietary model APIs (e.g., GPT-4o) to produce training data, which limits their training at scale. In this paper, we explore large-scale training for Video LLM with cheap automatic speech recognition (ASR) transcripts. Specifically, we propose a novel streaming training approach that densely interleaves the ASR words and video frames according to their timestamps. Compared to previous studies in vision-language representation with ASR, our method naturally fits the streaming characteristics of ASR, thus enabling the model to learn temporally-aligned, fine-grained vision-language modeling. To support the training algorithm, we introduce a data production pipeline to process YouTube videos and their closed captions (CC, same as ASR), resulting in Live-CC-5M dataset for pre-training and Live-WhisperX-526K dataset for high-quality supervised fine-tuning (SFT). Remarkably, even without SFT, the ASR-only pre-trained LiveCC-7B-Base model demonstrates competitive general video QA performance and exhibits a new capability in real-time video commentary. To evaluate this, we carefully design a new LiveSports-3K benchmark, using LLM-as-a-judge to measure the free-form commentary. Experiments show our final LiveCC-7B-Instruct model can surpass advanced 72B models (Qwen2.5-VL-72B-Instruct, LLaVA-Video-72B) in commentary quality even working in a real-time mode. Meanwhile, it achieves state-of-the-art results at the 7B/8B scale on popular video QA benchmarks such as VideoMME and OVOBench, demonstrating the broad generalizability of our approach. All resources of this paper have been released at https://showlab.github.io/livecc.
OmniPaint: Mastering Object-Oriented Editing via Disentangled Insertion-Removal Inpainting
Mar 12, 2025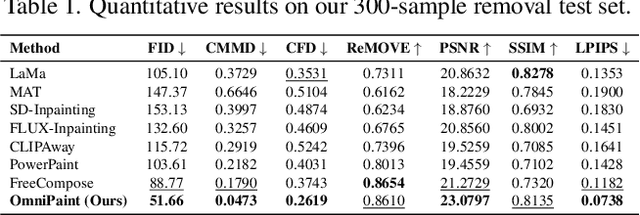

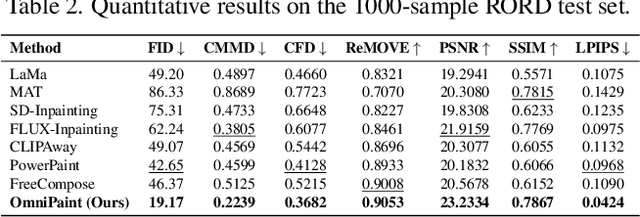

Diffusion-based generative models have revolutionized object-oriented image editing, yet their deployment in realistic object removal and insertion remains hampered by challenges such as the intricate interplay of physical effects and insufficient paired training data. In this work, we introduce OmniPaint, a unified framework that re-conceptualizes object removal and insertion as interdependent processes rather than isolated tasks. Leveraging a pre-trained diffusion prior along with a progressive training pipeline comprising initial paired sample optimization and subsequent large-scale unpaired refinement via CycleFlow, OmniPaint achieves precise foreground elimination and seamless object insertion while faithfully preserving scene geometry and intrinsic properties. Furthermore, our novel CFD metric offers a robust, reference-free evaluation of context consistency and object hallucination, establishing a new benchmark for high-fidelity image editing. Project page: https://yeates.github.io/OmniPaint-Page/
MMCOMPOSITION: Revisiting the Compositionality of Pre-trained Vision-Language Models
Oct 13, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal understanding, enabling more sophisticated and accurate integration of visual and textual information across various tasks, including image and video captioning, visual question answering, and cross-modal retrieval. Despite VLMs' superior capabilities, researchers lack a comprehensive understanding of their compositionality -- the ability to understand and produce novel combinations of known visual and textual components. Prior benchmarks provide only a relatively rough compositionality evaluation from the perspectives of objects, relations, and attributes while neglecting deeper reasoning about object interactions, counting, and complex compositions. However, compositionality is a critical ability that facilitates coherent reasoning and understanding across modalities for VLMs. To address this limitation, we propose MMCOMPOSITION, a novel human-annotated benchmark for comprehensively and accurately evaluating VLMs' compositionality. Our proposed benchmark serves as a complement to these earlier works. With MMCOMPOSITION, we can quantify and explore the compositionality of the mainstream VLMs. Surprisingly, we find GPT-4o's compositionality inferior to the best open-source model, and we analyze the underlying reasons. Our experimental analysis reveals the limitations of VLMs in fine-grained compositional perception and reasoning, and points to areas for improvement in VLM design and training. Resources available at: https://hanghuacs.github.io/MMComposition/
PromptFix: You Prompt and We Fix the Photo
May 27, 2024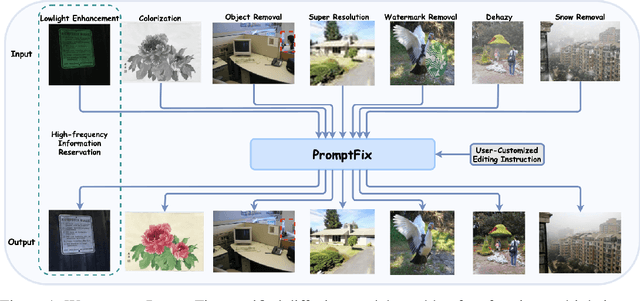
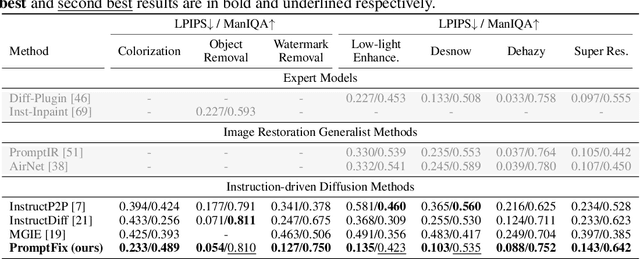
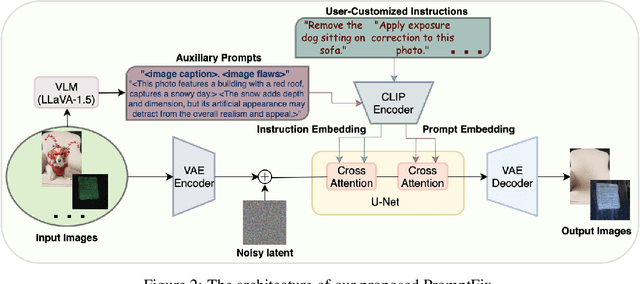

Diffusion models equipped with language models demonstrate excellent controllability in image generation tasks, allowing image processing to adhere to human instructions. However, the lack of diverse instruction-following data hampers the development of models that effectively recognize and execute user-customized instructions, particularly in low-level tasks. Moreover, the stochastic nature of the diffusion process leads to deficiencies in image generation or editing tasks that require the detailed preservation of the generated images. To address these limitations, we propose PromptFix, a comprehensive framework that enables diffusion models to follow human instructions to perform a wide variety of image-processing tasks. First, we construct a large-scale instruction-following dataset that covers comprehensive image-processing tasks, including low-level tasks, image editing, and object creation. Next, we propose a high-frequency guidance sampling method to explicitly control the denoising process and preserve high-frequency details in unprocessed areas. Finally, we design an auxiliary prompting adapter, utilizing Vision-Language Models (VLMs) to enhance text prompts and improve the model's task generalization. Experimental results show that PromptFix outperforms previous methods in various image-processing tasks. Our proposed model also achieves comparable inference efficiency with these baseline models and exhibits superior zero-shot capabilities in blind restoration and combination tasks. The dataset and code will be aviliable at https://github.com/yeates/PromptFix.
GMMFormer: Gaussian-Mixture-Model based Transformer for Efficient Partially Relevant Video Retrieval
Oct 08, 2023



Given a text query, partially relevant video retrieval (PRVR) seeks to find untrimmed videos containing pertinent moments in a database. For PRVR, clip modeling is essential to capture the partial relationship between texts and videos. Current PRVR methods adopt scanning-based clip construction to achieve explicit clip modeling, which is information-redundant and requires a large storage overhead. To solve the efficiency problem of PRVR methods, this paper proposes GMMFormer, a \textbf{G}aussian-\textbf{M}ixture-\textbf{M}odel based Trans\textbf{former} which models clip representations implicitly. During frame interactions, we incorporate Gaussian-Mixture-Model constraints to focus each frame on its adjacent frames instead of the whole video. Then generated representations will contain multi-scale clip information, achieving implicit clip modeling. In addition, PRVR methods ignore semantic differences between text queries relevant to the same video, leading to a sparse embedding space. We propose a query diverse loss to distinguish these text queries, making the embedding space more intensive and contain more semantic information. Extensive experiments on three large-scale video datasets (\ie, TVR, ActivityNet Captions, and Charades-STA) demonstrate the superiority and efficiency of GMMFormer.
Making LLaMA SEE and Draw with SEED Tokenizer
Oct 02, 2023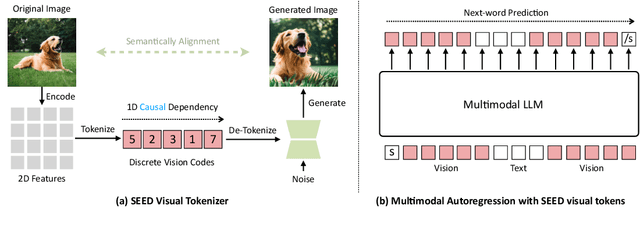
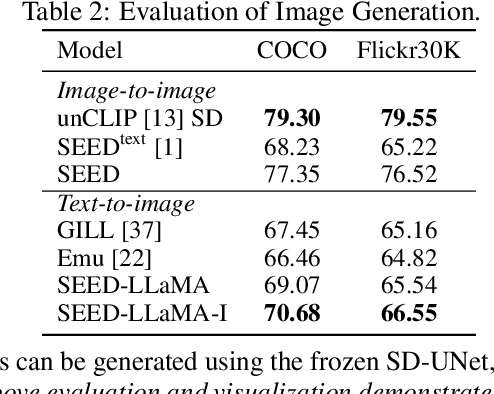

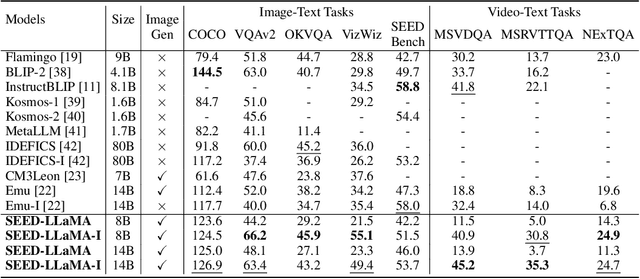
The great success of Large Language Models (LLMs) has expanded the potential of multimodality, contributing to the gradual evolution of General Artificial Intelligence (AGI). A true AGI agent should not only possess the capability to perform predefined multi-tasks but also exhibit emergent abilities in an open-world context. However, despite the considerable advancements made by recent multimodal LLMs, they still fall short in effectively unifying comprehension and generation tasks, let alone open-world emergent abilities. We contend that the key to overcoming the present impasse lies in enabling text and images to be represented and processed interchangeably within a unified autoregressive Transformer. To this end, we introduce SEED, an elaborate image tokenizer that empowers LLMs with the ability to SEE and Draw at the same time. We identify two crucial design principles: (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. With SEED tokens, LLM is able to perform scalable multimodal autoregression under its original training recipe, i.e., next-word prediction. SEED-LLaMA is therefore produced by large-scale pretraining and instruction tuning on the interleaved textual and visual data, demonstrating impressive performance on a broad range of multimodal comprehension and generation tasks. More importantly, SEED-LLaMA has exhibited compositional emergent abilities such as multi-turn in-context multimodal generation, acting like your AI assistant.