 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISSRec: Pre-training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation
Paper and Code
Aug 22, 2023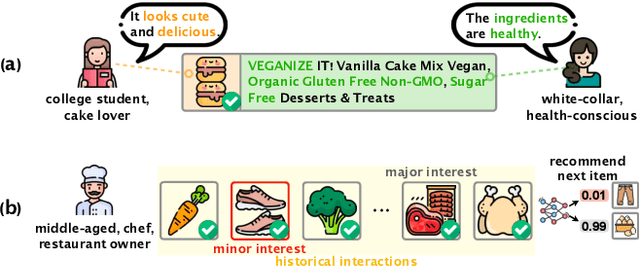

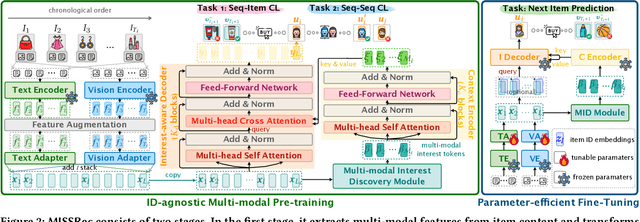

The goal of sequential recommendation (SR) is to predict a user's potential interested items based on her/his historical interaction sequences. Most existing sequential recommenders are developed based on ID features, which, despite their widespread use, often underperform with sparse IDs and struggle with the cold-start problem. Besides, inconsistent ID mappings hinder the model's transferability, isolating similar recommendation domains that could have been co-optimized. This paper aims to address these issues by exploring the potential of multi-modal information in learning robust and generalizable sequence representations. We propose MISSRec, a multi-modal pre-training and transfer learning framework for SR. On the user side, we design a Transformer-based encoder-decoder model, where the contextual encoder learns to capture the sequence-level multi-modal synergy while a novel interest-aware decoder is developed to grasp item-modality-interest relations for better sequence representation. On the candidate item side, we adopt a dynamic fusion module to produce user-adaptive item representation, providing more precise matching between users and items. We pre-train the model with contrastive learning objectives and fine-tune it in an efficient manner. Extensive experiments demonstrate the effectiveness and flexibility of MISSRec, promising an practical solution for real-world recommendation scenarios.