 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhostShell: Streaming LLM Function Calls for Concurrent Embodied Programming
Aug 07, 2025



We present GhostShell, a novel approach that leverages Large Language Models (LLMs) to enable streaming and concurrent behavioral programming for embodied systems. In contrast to conventional methods that rely on pre-scheduled action sequences or behavior trees, GhostShell drives embodied systems to act on-the-fly by issuing function calls incrementally as tokens are streamed from the LLM. GhostShell features a streaming XML function token parser, a dynamic function interface mapper, and a multi-channel scheduler that orchestrates intra-channel synchronous and inter-channel asynchronous function calls, thereby coordinating serial-parallel embodied actions across multiple robotic components as directed by the LLM. We evaluate GhostShell on our robot prototype COCO through comprehensive grounded experiments across 34 real-world interaction tasks and multiple LLMs. The results demonstrate that our approach achieves state-of-the-art Behavioral Correctness Metric of 0.85 with Claude-4 Sonnet and up to 66X faster response times compared to LLM native function calling APIs. GhostShell also proves effective in long-horizon multimodal tasks, demonstrating strong robustness and generalization.
Precise Representation Model of SAR Saturated Interference: Mechanism and Verification
Jul 09, 2025Synthetic Aperture Radar (SAR) is highly susceptible to Radio Frequency Interference (RFI). Due to the performance limitations of components such as gain controllers and analog-to-digital converters in SAR receivers, high-power interference can easily cause saturation of the SAR receiver, resulting in nonlinear distortion of the interfered echoes, which are distorted in both the time domain and frequency domain. Some scholars have analyzed the impact of SAR receiver saturation on target echoes through simulations. However, the saturation function has non-smooth characteristics, making it difficult to conduct accurate analysis using traditional analytical methods. Current related studies have approximated and analyzed the saturation function based on the hyperbolic tangent function, but there are approximation errors. Therefore, this paper proposes a saturation interference analysis model based on Bessel functions, and verifies the accuracy of the proposed saturation interference analysis model by simulating and comparing it with the traditional saturation model based on smooth function approximation. This model can provide certain guidance for further work such as saturation interference suppression.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Why Distillation can Outperform Zero-RL: The Role of Flexible Reasoning
May 27, 2025



Reinforcement learning (RL) has played an important role in improving the reasoning ability of large language models (LLMs). Some studies apply RL directly to \textit{smaller} base models (known as zero-RL) and also achieve notable progress. However, in this paper, we show that using only 920 examples, a simple distillation method based on the base model can clearly outperform zero-RL, which typically requires much more data and computational cost. By analyzing the token frequency in model outputs, we find that the distilled model shows more flexible reasoning. It uses anthropomorphic tokens and logical connectors much more often than the zero-RL model. Further analysis reveals that distillation enhances the presence of two advanced cognitive behaviors: Multi-Perspective Thinking or Attempting and Metacognitive Awareness. Frequent occurrences of these two advanced cognitive behaviors give rise to flexible reasoning, which is essential for solving complex reasoning problems, while zero-RL fails to significantly boost the frequency of these behaviors.
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
May 05, 2025Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4\%$ improvement on the VL Reward-Bench and a $14.3\%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward's performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.
VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
Apr 21, 2025Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, particularly for minors. The dissemination of such content on SVPs can lead to catastrophic societal consequences. Although substantial efforts have been dedicated to moderating such content, existing methods suffer from critical limitations: (1) Manual review is prone to human bias and incurs high operational costs. (2) Automated methods, though efficient, lack nuanced content understanding, resulting in lower accuracy. (3) Industrial moderation regulations struggle to adapt to rapidly evolving trends due to long update cycles. In this paper, we annotate the first SVP content moderation benchmark with authentic user/reviewer feedback to fill the absence of benchmark in this field. Then we evaluate various methods on the benchmark to verify the existence of the aforementioned limitations. We further propose our common-law content moderation framework named KuaiMod to address these challenges. KuaiMod consists of three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging large vision language model (VLM) and Chain-of-Thought (CoT) reasoning, KuaiMod adequately models video toxicity based on sparse user feedback and fosters dynamic moderation policy with rapid update speed and high accuracy. Offline experiments and large-scale online A/B test demonstrates the superiority of KuaiMod: KuaiMod achieves the best moderation performance on our benchmark. The deployment of KuaiMod reduces the user reporting rate by 20% and its application in video recommendation increases both Daily Active User (DAU) and APP Usage Time (AUT) on several Kuaishou scenarios. We have open-sourced our benchmark at https://kuaimod.github.io.
InstructEngine: Instruction-driven Text-to-Image Alignment
Apr 14, 2025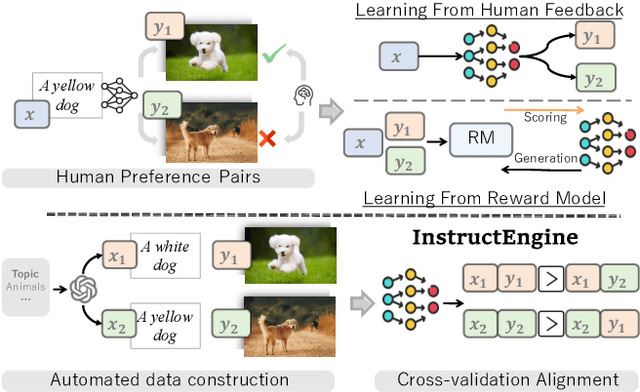
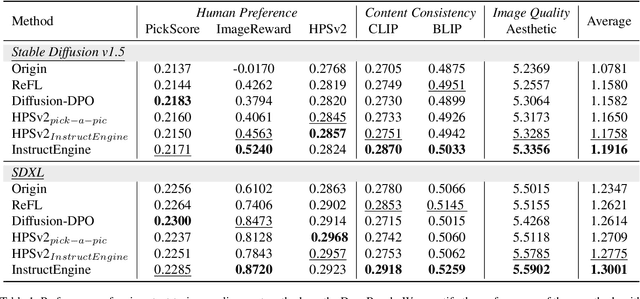

Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.
RLCAD: Reinforcement Learning Training Gym for Revolution Involved CAD Command Sequence Generation
Mar 24, 2025A CAD command sequence is a typical parametric design paradigm in 3D CAD systems where a model is constructed by overlaying 2D sketches with operations such as extrusion, revolution, and Boolean operations. Although there is growing academic interest in the automatic generation of command sequences, existing methods and datasets only support operations such as 2D sketching, extrusion,and Boolean operations. This limitation makes it challenging to represent more complex geometries. In this paper, we present a reinforcement learning (RL) training environment (gym) built on a CAD geometric engine. Given an input boundary representation (B-Rep) geometry, the policy network in the RL algorithm generates an action. This action, along with previously generated actions, is processed within the gym to produce the corresponding CAD geometry, which is then fed back into the policy network. The rewards, determined by the difference between the generated and target geometries within the gym, are used to update the RL network. Our method supports operations beyond sketches, Boolean, and extrusion, including revolution operations. With this training gym, we achieve state-of-the-art (SOTA) quality in generating command sequences from B-Rep geometries. In addition, our method can significantly improve the efficiency of command sequence generation by a factor of 39X compared with the previous training gym.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025
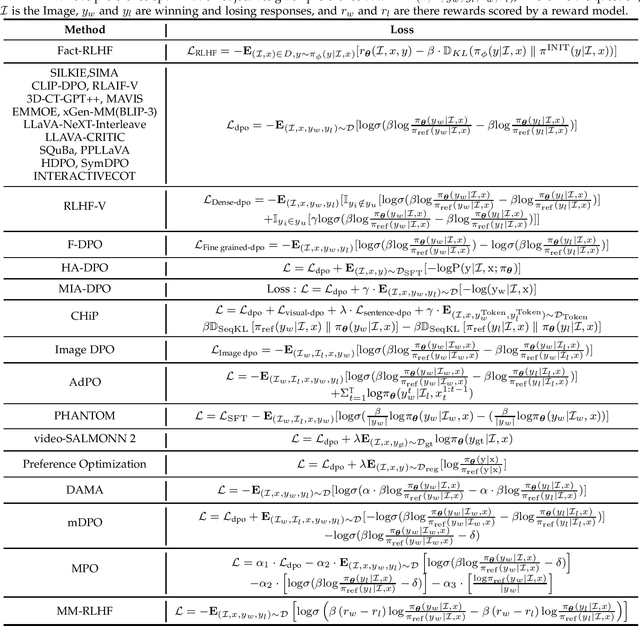
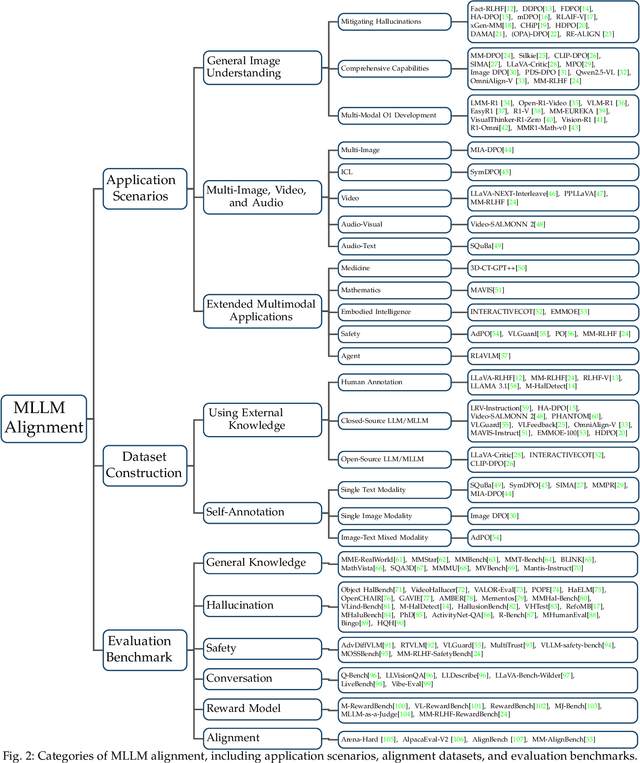
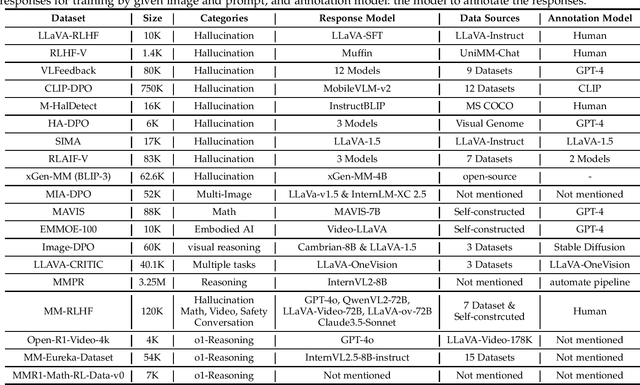
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
Kwai-STaR: Transform LLMs into State-Transition Reasoners
Nov 07, 2024



Mathematical reasoning presents a significant challenge to the cognitive capabilities of LLMs. Various methods have been proposed to enhance the mathematical ability of LLMs. However, few recognize the value of state transition for LLM reasoning. In this work, we define mathematical problem-solving as a process of transiting from an initial unsolved state to the final resolved state, and propose Kwai-STaR framework, which transforms LLMs into State-Transition Reasoners to improve their intuitive reasoning capabilities. Our approach comprises three main steps: (1) Define the state space tailored to the mathematical reasoning. (2) Generate state-transition data based on the state space. (3) Convert original LLMs into State-Transition Reasoners via a curricular training strategy. Our experiments validate the effectiveness of Kwai-STaR in enhancing mathematical reasoning: After training on the small-scale Kwai-STaR dataset, general LLMs, including Mistral-7B and LLaMA-3, achieve considerable performance gain on the GSM8K and GSM-Hard dataset. Additionally, the state transition-based design endows Kwai-STaR with remarkable training and inference efficiency. Further experiments are underway to establish the generality of Kwai-STaR.