 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
May 05, 2025Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4\%$ improvement on the VL Reward-Bench and a $14.3\%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward's performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.
VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
Apr 21, 2025Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, particularly for minors. The dissemination of such content on SVPs can lead to catastrophic societal consequences. Although substantial efforts have been dedicated to moderating such content, existing methods suffer from critical limitations: (1) Manual review is prone to human bias and incurs high operational costs. (2) Automated methods, though efficient, lack nuanced content understanding, resulting in lower accuracy. (3) Industrial moderation regulations struggle to adapt to rapidly evolving trends due to long update cycles. In this paper, we annotate the first SVP content moderation benchmark with authentic user/reviewer feedback to fill the absence of benchmark in this field. Then we evaluate various methods on the benchmark to verify the existence of the aforementioned limitations. We further propose our common-law content moderation framework named KuaiMod to address these challenges. KuaiMod consists of three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging large vision language model (VLM) and Chain-of-Thought (CoT) reasoning, KuaiMod adequately models video toxicity based on sparse user feedback and fosters dynamic moderation policy with rapid update speed and high accuracy. Offline experiments and large-scale online A/B test demonstrates the superiority of KuaiMod: KuaiMod achieves the best moderation performance on our benchmark. The deployment of KuaiMod reduces the user reporting rate by 20% and its application in video recommendation increases both Daily Active User (DAU) and APP Usage Time (AUT) on several Kuaishou scenarios. We have open-sourced our benchmark at https://kuaimod.github.io.
InstructEngine: Instruction-driven Text-to-Image Alignment
Apr 14, 2025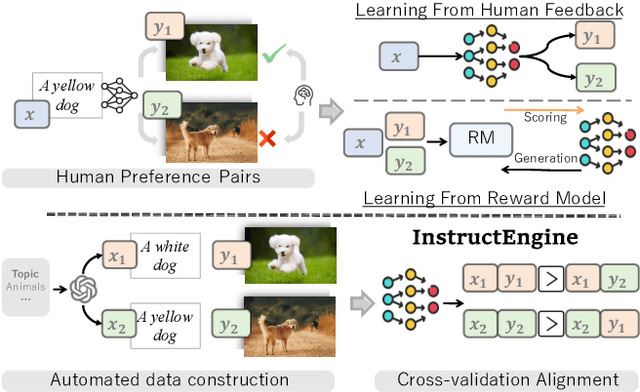
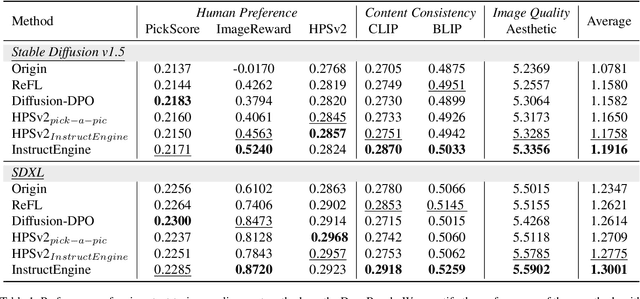

Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.
FABG : End-to-end Imitation Learning for Embodied Affective Human-Robot Interaction
Mar 04, 2025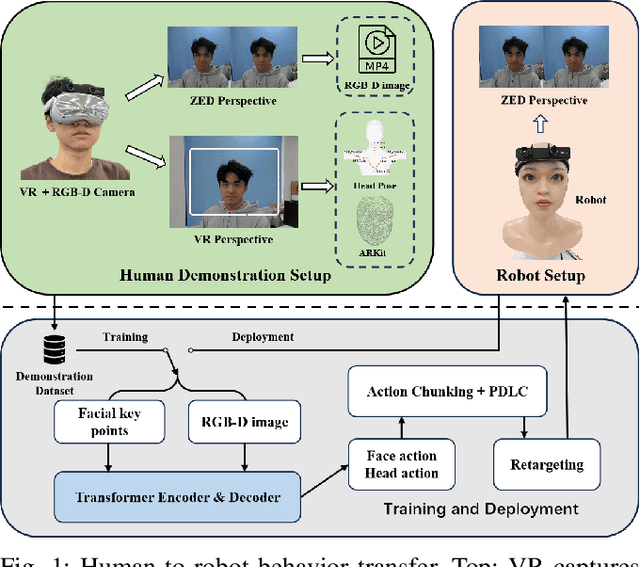
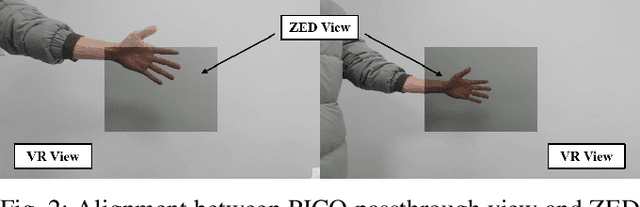
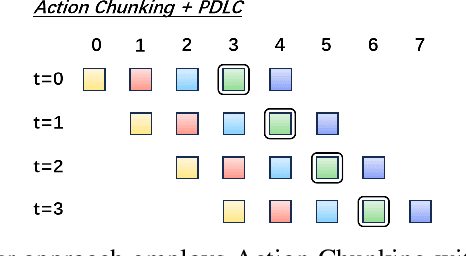

This paper proposes FABG (Facial Affective Behavior Generation), an end-to-end imitation learning system for human-robot interaction, designed to generate natural and fluid facial affective behaviors. In interaction, effectively obtaining high-quality demonstrations remains a challenge. In this work, we develop an immersive virtual reality (VR) demonstration system that allows operators to perceive stereoscopic environments. This system ensures "the operator's visual perception matches the robot's sensory input" and "the operator's actions directly determine the robot's behaviors" - as if the operator replaces the robot in human interaction engagements. We propose a prediction-driven latency compensation strategy to reduce robotic reaction delays and enhance interaction fluency. FABG naturally acquires human interactive behaviors and subconscious motions driven by intuition, eliminating manual behavior scripting. We deploy FABG on a real-world 25-degree-of-freedom (DoF) humanoid robot, validating its effectiveness through four fundamental interaction tasks: expression response, dynamic gaze, foveated attention, and gesture recognition, supported by data collection and policy training. Project website: https://cybergenies.github.io
Kwai-STaR: Transform LLMs into State-Transition Reasoners
Nov 07, 2024



Mathematical reasoning presents a significant challenge to the cognitive capabilities of LLMs. Various methods have been proposed to enhance the mathematical ability of LLMs. However, few recognize the value of state transition for LLM reasoning. In this work, we define mathematical problem-solving as a process of transiting from an initial unsolved state to the final resolved state, and propose Kwai-STaR framework, which transforms LLMs into State-Transition Reasoners to improve their intuitive reasoning capabilities. Our approach comprises three main steps: (1) Define the state space tailored to the mathematical reasoning. (2) Generate state-transition data based on the state space. (3) Convert original LLMs into State-Transition Reasoners via a curricular training strategy. Our experiments validate the effectiveness of Kwai-STaR in enhancing mathematical reasoning: After training on the small-scale Kwai-STaR dataset, general LLMs, including Mistral-7B and LLaMA-3, achieve considerable performance gain on the GSM8K and GSM-Hard dataset. Additionally, the state transition-based design endows Kwai-STaR with remarkable training and inference efficiency. Further experiments are underway to establish the generality of Kwai-STaR.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024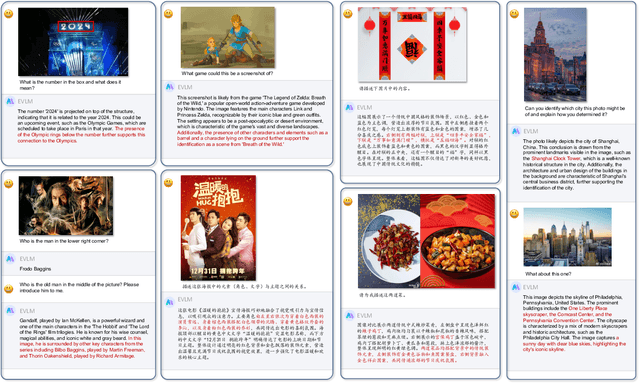
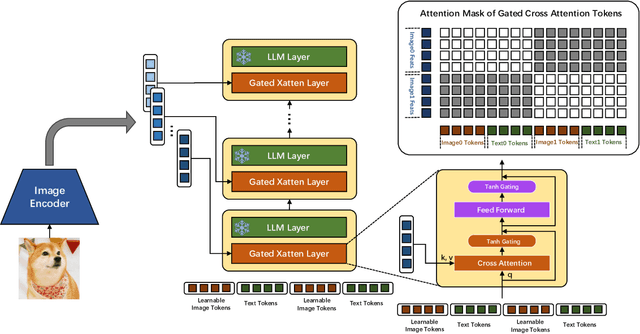

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.