 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwakening Facial Emotional Expressions in Human-Robot
Oct 27, 2025The facial expression generation capability of humanoid social robots is critical for achieving natural and human-like interactions, playing a vital role in enhancing the fluidity of human-robot interactions and the accuracy of emotional expression. Currently, facial expression generation in humanoid social robots still relies on pre-programmed behavioral patterns, which are manually coded at high human and time costs. To enable humanoid robots to autonomously acquire generalized expressive capabilities, they need to develop the ability to learn human-like expressions through self-training. To address this challenge, we have designed a highly biomimetic robotic face with physical-electronic animated facial units and developed an end-to-end learning framework based on KAN (Kolmogorov-Arnold Network) and attention mechanisms. Unlike previous humanoid social robots, we have also meticulously designed an automated data collection system based on expert strategies of facial motion primitives to construct the dataset. Notably, to the best of our knowledge, this is the first open-source facial dataset for humanoid social robots. Comprehensive evaluations indicate that our approach achieves accurate and diverse facial mimicry across different test subjects.
FABG : End-to-end Imitation Learning for Embodied Affective Human-Robot Interaction
Mar 04, 2025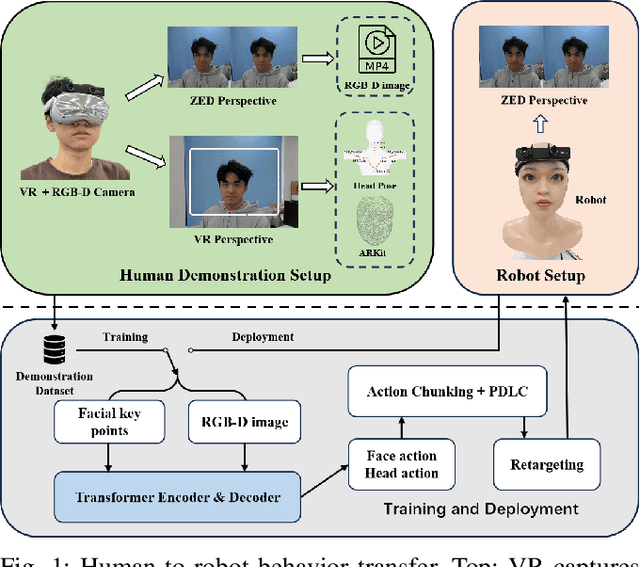
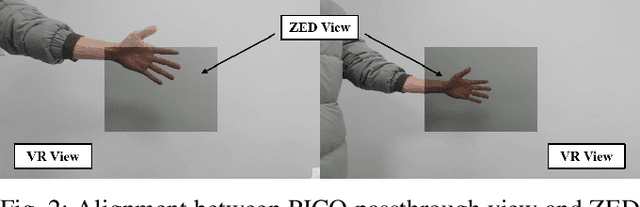
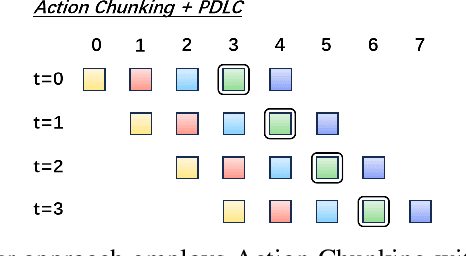

This paper proposes FABG (Facial Affective Behavior Generation), an end-to-end imitation learning system for human-robot interaction, designed to generate natural and fluid facial affective behaviors. In interaction, effectively obtaining high-quality demonstrations remains a challenge. In this work, we develop an immersive virtual reality (VR) demonstration system that allows operators to perceive stereoscopic environments. This system ensures "the operator's visual perception matches the robot's sensory input" and "the operator's actions directly determine the robot's behaviors" - as if the operator replaces the robot in human interaction engagements. We propose a prediction-driven latency compensation strategy to reduce robotic reaction delays and enhance interaction fluency. FABG naturally acquires human interactive behaviors and subconscious motions driven by intuition, eliminating manual behavior scripting. We deploy FABG on a real-world 25-degree-of-freedom (DoF) humanoid robot, validating its effectiveness through four fundamental interaction tasks: expression response, dynamic gaze, foveated attention, and gesture recognition, supported by data collection and policy training. Project website: https://cybergenies.github.io
Catching Spinning Table Tennis Balls in Simulation with End-to-End Curriculum Reinforcement Learning
Mar 03, 2025



The game of table tennis is renowned for its extremely high spin rate, but most table tennis robots today struggle to handle balls with such rapid spin. To address this issue, we have contributed a series of methods, including: 1. Curriculum Reinforcement Learning (RL): This method helps the table tennis robot learn to play table tennis progressively from easy to difficult tasks. 2. Analysis of Spinning Table Tennis Ball Collisions: We have conducted a physics-based analysis to generate more realistic trajectories of spinning table tennis balls after collision. 3. Definition of Trajectory States: The definition of trajectory states aids in setting up the reward function. 4. Selection of Valid Rally Trajectories: We have introduced a valid rally trajectory selection scheme to ensure that the robot's training is not influenced by abnormal trajectories. 5. Reality-to-Simulation (Real2Sim) Transfer: This scheme is employed to validate the trained robot's ability to handle spinning balls in real-world scenarios. With Real2Sim, the deployment costs for robotic reinforcement learning can be further reduced. Moreover, the trajectory-state-based reward function is not limited to table tennis robots; it can be generalized to a wide range of cyclical tasks. To validate our robot's ability to handle spinning balls, the Real2Sim experiments were conducted. For the specific video link of the experiment, please refer to the supplementary materials.