 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Zero-Shot Composed Image Retrieval with Complementary Visual-Semantic Integration
Jan 20, 2026Zero-shot composed image retrieval (ZS-CIR) is a rapidly growing area with significant practical applications, allowing users to retrieve a target image by providing a reference image and a relative caption describing the desired modifications. Existing ZS-CIR methods often struggle to capture fine-grained changes and integrate visual and semantic information effectively. They primarily rely on either transforming the multimodal query into a single text using image-to-text models or employing large language models for target image description generation, approaches that often fail to capture complementary visual information and complete semantic context. To address these limitations, we propose a novel Fine-Grained Zero-Shot Composed Image Retrieval method with Complementary Visual-Semantic Integration (CVSI). Specifically, CVSI leverages three key components: (1) Visual Information Extraction, which not only extracts global image features but also uses a pre-trained mapping network to convert the image into a pseudo token, combining it with the modification text and the objects most likely to be added. (2) Semantic Information Extraction, which involves using a pre-trained captioning model to generate multiple captions for the reference image, followed by leveraging an LLM to generate the modified captions and the objects most likely to be added. (3) Complementary Information Retrieval, which integrates information extracted from both the query and database images to retrieve the target image, enabling the system to efficiently handle retrieval queries in a variety of situations. Extensive experiments on three public datasets (e.g., CIRR, CIRCO, and FashionIQ) demonstrate that CVSI significantly outperforms existing state-of-the-art methods. Our code is available at https://github.com/yyc6631/CVSI.
Layer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models
Jan 07, 2026Large language models (LLMs) perform well on multi-hop reasoning, yet how they internally compose multiple facts remains unclear. Recent work proposes \emph{hop-aligned circuit hypothesis}, suggesting that bridge entities are computed sequentially across layers before later-hop answers. Through systematic analyses on real-world multi-hop queries, we show that this hop-aligned assumption does not generalize: later-hop answer entities can become decodable earlier than bridge entities, a phenomenon we call \emph{layer-order inversion}, which strengthens with total hops. To explain this behavior, we propose a \emph{probabilistic recall-and-extract} framework that models multi-hop reasoning as broad probabilistic recall in shallow MLP layers followed by selective extraction in deeper attention layers. This framework is empirically validated through systematic probing analyses, reinterpreting prior layer-wise decoding evidence, explaining chain-of-thought gains, and providing a mechanistic diagnosis of multi-hop failures despite correct single-hop knowledge. Code is available at https://github.com/laquabe/Layer-Order-Inversion.
Self-Reflective Planning with Knowledge Graphs: Enhancing LLM Reasoning Reliability for Question Answering
May 26, 2025Recently, large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks, yet they remain prone to hallucinations when reasoning with insufficient internal knowledge. While integrating LLMs with knowledge graphs (KGs) provides access to structured, verifiable information, existing approaches often generate incomplete or factually inconsistent reasoning paths. To this end, we propose Self-Reflective Planning (SRP), a framework that synergizes LLMs with KGs through iterative, reference-guided reasoning. Specifically, given a question and topic entities, SRP first searches for references to guide planning and reflection. In the planning process, it checks initial relations and generates a reasoning path. After retrieving knowledge from KGs through a reasoning path, it implements iterative reflection by judging the retrieval result and editing the reasoning path until the answer is correctly retrieved. Extensive experiments on three public datasets demonstrate that SRP surpasses various strong baselines and further underscore its reliable reasoning ability.
Know3-RAG: A Knowledge-aware RAG Framework with Adaptive Retrieval, Generation, and Filtering
May 19, 2025Recent advances in large language models (LLMs) have led to impressive progress in natural language generation, yet their tendency to produce hallucinated or unsubstantiated content remains a critical concern. To improve factual reliability, Retrieval-Augmented Generation (RAG) integrates external knowledge during inference. However, existing RAG systems face two major limitations: (1) unreliable adaptive control due to limited external knowledge supervision, and (2) hallucinations caused by inaccurate or irrelevant references. To address these issues, we propose Know3-RAG, a knowledge-aware RAG framework that leverages structured knowledge from knowledge graphs (KGs) to guide three core stages of the RAG process, including retrieval, generation, and filtering. Specifically, we introduce a knowledge-aware adaptive retrieval module that employs KG embedding to assess the confidence of the generated answer and determine retrieval necessity, a knowledge-enhanced reference generation strategy that enriches queries with KG-derived entities to improve generated reference relevance, and a knowledge-driven reference filtering mechanism that ensures semantic alignment and factual accuracy of references. Experiments on multiple open-domain QA benchmarks demonstrate that Know3-RAG consistently outperforms strong baselines, significantly reducing hallucinations and enhancing answer reliability.
FABG : End-to-end Imitation Learning for Embodied Affective Human-Robot Interaction
Mar 04, 2025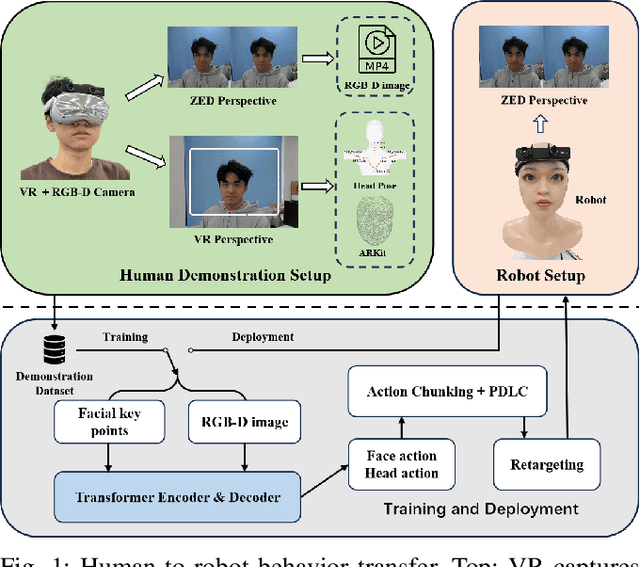
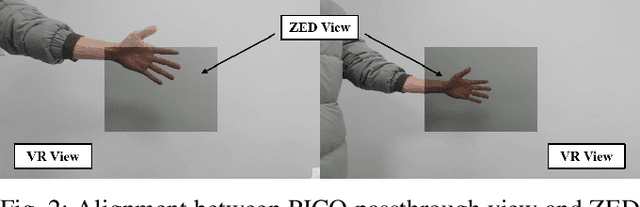
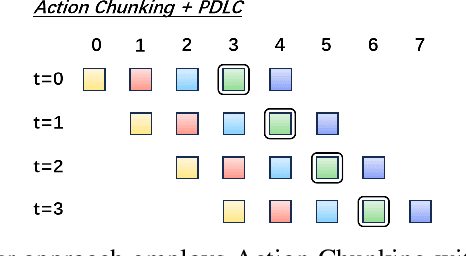

This paper proposes FABG (Facial Affective Behavior Generation), an end-to-end imitation learning system for human-robot interaction, designed to generate natural and fluid facial affective behaviors. In interaction, effectively obtaining high-quality demonstrations remains a challenge. In this work, we develop an immersive virtual reality (VR) demonstration system that allows operators to perceive stereoscopic environments. This system ensures "the operator's visual perception matches the robot's sensory input" and "the operator's actions directly determine the robot's behaviors" - as if the operator replaces the robot in human interaction engagements. We propose a prediction-driven latency compensation strategy to reduce robotic reaction delays and enhance interaction fluency. FABG naturally acquires human interactive behaviors and subconscious motions driven by intuition, eliminating manual behavior scripting. We deploy FABG on a real-world 25-degree-of-freedom (DoF) humanoid robot, validating its effectiveness through four fundamental interaction tasks: expression response, dynamic gaze, foveated attention, and gesture recognition, supported by data collection and policy training. Project website: https://cybergenies.github.io
Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization
Aug 06, 2024The rapid increase in multimedia data has spurred advancements in Multimodal Summarization with Multimodal Output (MSMO), which aims to produce a multimodal summary that integrates both text and relevant images. The inherent heterogeneity of content within multimodal inputs and outputs presents a significant challenge to the execution of MSMO. Traditional approaches typically adopt a holistic perspective on coarse image-text data or individual visual objects, overlooking the essential connections between objects and the entities they represent. To integrate the fine-grained entity knowledge, we propose an Entity-Guided Multimodal Summarization model (EGMS). Our model, building on BART, utilizes dual multimodal encoders with shared weights to process text-image and entity-image information concurrently. A gating mechanism then combines visual data for enhanced textual summary generation, while image selection is refined through knowledge distillation from a pre-trained vision-language model. Extensive experiments on public MSMO dataset validate the superiority of the EGMS method, which also prove the necessity to incorporate entity information into MSMO problem.
Learn while Unlearn: An Iterative Unlearning Framework for Generative Language Models
Jul 25, 2024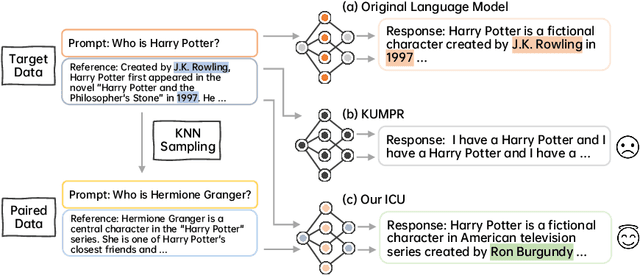
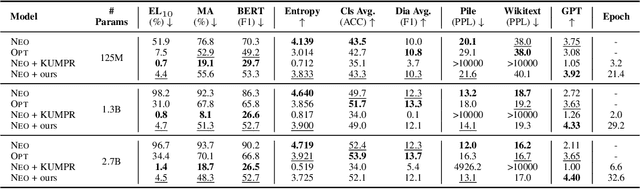
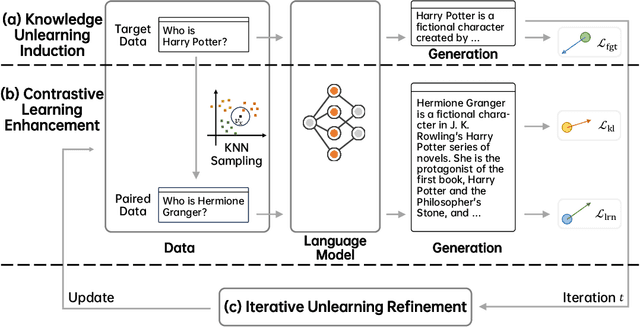
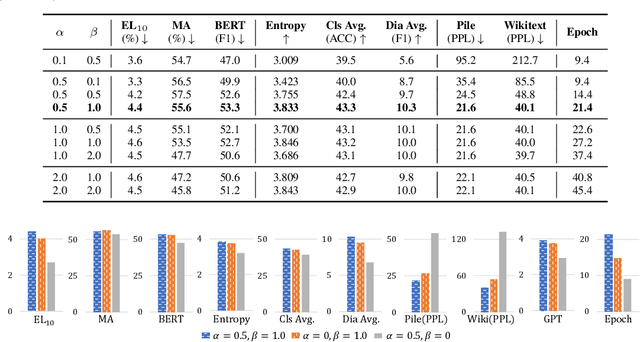
Recent advancements in machine learning, especially in Natural Language Processing (NLP), have led to the development of sophisticated models trained on vast datasets, but this progress has raised concerns about potential sensitive information leakage. In response, regulatory measures like the EU General Data Protection Regulation (GDPR) have driven the exploration of Machine Unlearning techniques, which aim to enable models to selectively forget certain data entries. While early approaches focused on pre-processing methods, recent research has shifted towards training-based machine unlearning methods. However, many existing methods require access to original training data, posing challenges in scenarios where such data is unavailable. Besides, directly facilitating unlearning may undermine the language model's general expressive ability. To this end, in this paper, we introduce the Iterative Contrastive Unlearning (ICU) framework, which addresses these challenges by incorporating three key components. We propose a Knowledge Unlearning Induction module for unlearning specific target sequences and a Contrastive Learning Enhancement module to prevent degrading in generation capacity. Additionally, an Iterative Unlearning Refinement module is integrated to make the process more adaptive to each target sample respectively. Experimental results demonstrate the efficacy of ICU in maintaining performance while efficiently unlearning sensitive information, offering a promising avenue for privacy-conscious machine learning applications.
Detect, Investigate, Judge and Determine: A Novel LLM-based Framework for Few-shot Fake News Detection
Jul 12, 2024Few-Shot Fake News Detection (FS-FND) aims to distinguish inaccurate news from real ones in extremely low-resource scenarios. This task has garnered increased attention due to the widespread dissemination and harmful impact of fake news on social media. Large Language Models (LLMs) have demonstrated competitive performance with the help of their rich prior knowledge and excellent in-context learning abilities. However, existing methods face significant limitations, such as the Understanding Ambiguity and Information Scarcity, which significantly undermine the potential of LLMs. To address these shortcomings, we propose a Dual-perspective Augmented Fake News Detection (DAFND) model, designed to enhance LLMs from both inside and outside perspectives. Specifically, DAFND first identifies the keywords of each news article through a Detection Module. Subsequently, DAFND creatively designs an Investigation Module to retrieve inside and outside valuable information concerning to the current news, followed by another Judge Module to derive its respective two prediction results. Finally, a Determination Module further integrates these two predictions and derives the final result. Extensive experiments on two publicly available datasets show the efficacy of our proposed method, particularly in low-resource settings.