 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled LLM Training on Spectral Sphere
Jan 13, 2026Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
Joint Knowledge and Power Management for Secure Semantic Communication Networks
Apr 21, 2025Recently, semantic communication (SemCom) has shown its great superiorities in resource savings and information exchanges. However, while its unique background knowledge guarantees accurate semantic reasoning and recovery, semantic information security-related concerns are introduced at the same time. Since the potential eavesdroppers may have the same background knowledge to accurately decrypt the private semantic information transmitted between legal SemCom users, this makes the knowledge management in SemCom networks rather challenging in joint consideration with the power control. To this end, this paper focuses on jointly addressing three core issues of power allocation, knowledge base caching (KBC), and device-to-device (D2D) user pairing (DUP) in secure SemCom networks. We first develop a novel performance metric, namely semantic secrecy throughput (SST), to quantify the information security level that can be achieved at each pair of D2D SemCom users. Next, an SST maximization problem is formulated subject to secure SemCom-related delay and reliability constraints. Afterward, we propose a security-aware resource management solution using the Lagrange primal-dual method and a two-stage method. Simulation results demonstrate our proposed solution nearly doubles the SST performance and realizes less than half of the queuing delay performance compared to different benchmarks.
Uncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
Learn while Unlearn: An Iterative Unlearning Framework for Generative Language Models
Jul 25, 2024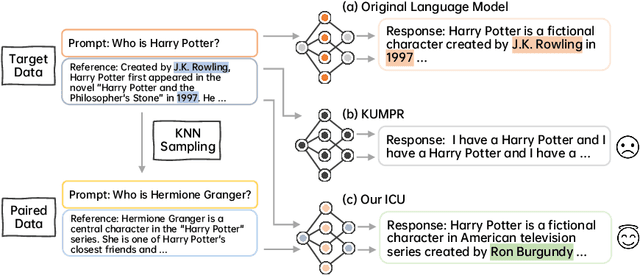
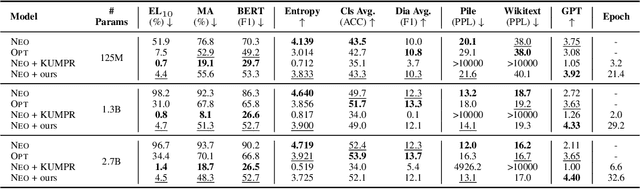
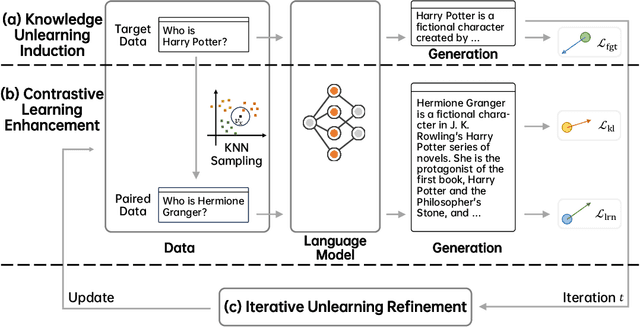
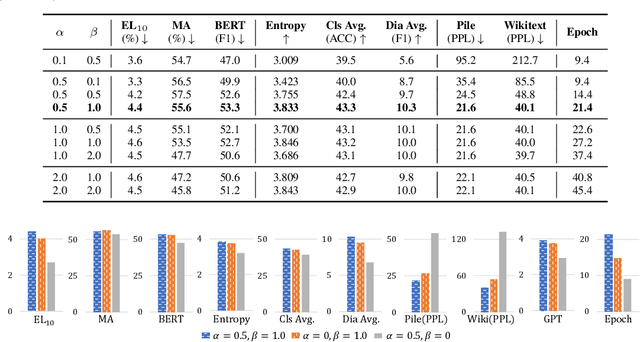
Recent advancements in machine learning, especially in Natural Language Processing (NLP), have led to the development of sophisticated models trained on vast datasets, but this progress has raised concerns about potential sensitive information leakage. In response, regulatory measures like the EU General Data Protection Regulation (GDPR) have driven the exploration of Machine Unlearning techniques, which aim to enable models to selectively forget certain data entries. While early approaches focused on pre-processing methods, recent research has shifted towards training-based machine unlearning methods. However, many existing methods require access to original training data, posing challenges in scenarios where such data is unavailable. Besides, directly facilitating unlearning may undermine the language model's general expressive ability. To this end, in this paper, we introduce the Iterative Contrastive Unlearning (ICU) framework, which addresses these challenges by incorporating three key components. We propose a Knowledge Unlearning Induction module for unlearning specific target sequences and a Contrastive Learning Enhancement module to prevent degrading in generation capacity. Additionally, an Iterative Unlearning Refinement module is integrated to make the process more adaptive to each target sample respectively. Experimental results demonstrate the efficacy of ICU in maintaining performance while efficiently unlearning sensitive information, offering a promising avenue for privacy-conscious machine learning applications.
Detect, Investigate, Judge and Determine: A Novel LLM-based Framework for Few-shot Fake News Detection
Jul 12, 2024Few-Shot Fake News Detection (FS-FND) aims to distinguish inaccurate news from real ones in extremely low-resource scenarios. This task has garnered increased attention due to the widespread dissemination and harmful impact of fake news on social media. Large Language Models (LLMs) have demonstrated competitive performance with the help of their rich prior knowledge and excellent in-context learning abilities. However, existing methods face significant limitations, such as the Understanding Ambiguity and Information Scarcity, which significantly undermine the potential of LLMs. To address these shortcomings, we propose a Dual-perspective Augmented Fake News Detection (DAFND) model, designed to enhance LLMs from both inside and outside perspectives. Specifically, DAFND first identifies the keywords of each news article through a Detection Module. Subsequently, DAFND creatively designs an Investigation Module to retrieve inside and outside valuable information concerning to the current news, followed by another Judge Module to derive its respective two prediction results. Finally, a Determination Module further integrates these two predictions and derives the final result. Extensive experiments on two publicly available datasets show the efficacy of our proposed method, particularly in low-resource settings.
Towards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory
Jun 28, 2024The rapid evolution of deep learning and large language models has led to an exponential growth in the demand for training data, prompting the development of Dataset Distillation methods to address the challenges of managing large datasets. Among these, Matching Training Trajectories (MTT) has been a prominent approach, which replicates the training trajectory of an expert network on real data with a synthetic dataset. However, our investigation found that this method suffers from three significant limitations: 1. Instability of expert trajectory generated by Stochastic Gradient Descent (SGD); 2. Low convergence speed of the distillation process; 3. High storage consumption of the expert trajectory. To address these issues, we offer a new perspective on understanding the essence of Dataset Distillation and MTT through a simple transformation of the objective function, and introduce a novel method called Matching Convexified Trajectory (MCT), which aims to provide better guidance for the student trajectory. MCT leverages insights from the linearized dynamics of Neural Tangent Kernel methods to create a convex combination of expert trajectories, guiding the student network to converge rapidly and stably. This trajectory is not only easier to store, but also enables a continuous sampling strategy during distillation, ensuring thorough learning and fitting of the entire expert trajectory. Comprehensive experiments across three public datasets validate the superiority of MCT over traditional MTT methods.
Graph Network Surrogate Model for Subsurface Flow Optimization
Dec 14, 2023The optimization of well locations and controls is an important step in the design of subsurface flow operations such as oil production or geological CO2 storage. These optimization problems can be computationally expensive, however, as many potential candidate solutions must be evaluated. In this study, we propose a graph network surrogate model (GNSM) for optimizing well placement and controls. The GNSM transforms the flow model into a computational graph that involves an encoding-processing-decoding architecture. Separate networks are constructed to provide global predictions for the pressure and saturation state variables. Model performance is enhanced through the inclusion of the single-phase steady-state pressure solution as a feature. A multistage multistep strategy is used for training. The trained GNSM is applied to predict flow responses in a 2D unstructured model of a channelized reservoir. Results are presented for a large set of test cases, in which five injection wells and five production wells are placed randomly throughout the model, with a random control variable (bottom-hole pressure) assigned to each well. Median relative error in pressure and saturation for 300 such test cases is 1-2%. The ability of the trained GNSM to provide accurate predictions for a new (geologically similar) permeability realization is demonstrated. Finally, the trained GNSM is used to optimize well locations and controls with a differential evolution algorithm. GNSM-based optimization results are comparable to those from simulation-based optimization, with a runtime speedup of a factor of 36. Much larger speedups are expected if the method is used for robust optimization, in which each candidate solution is evaluated on multiple geological models.
Unsupervised Temporal Action Localization via Self-paced Incremental Learning
Dec 12, 2023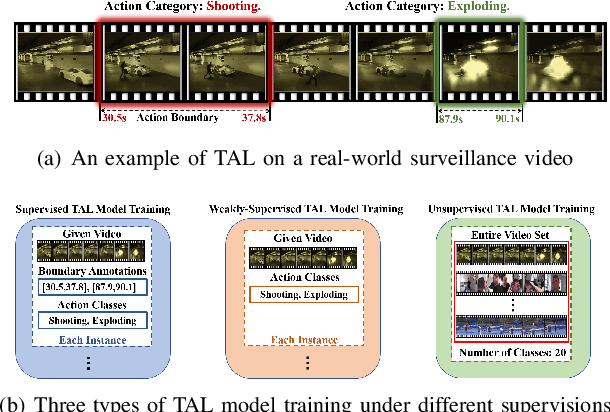
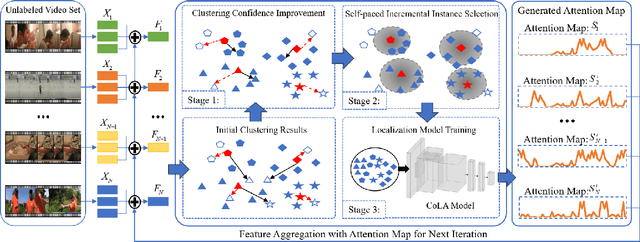
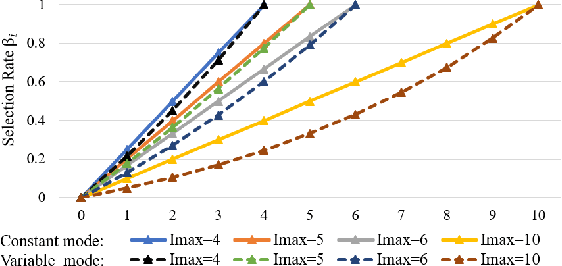
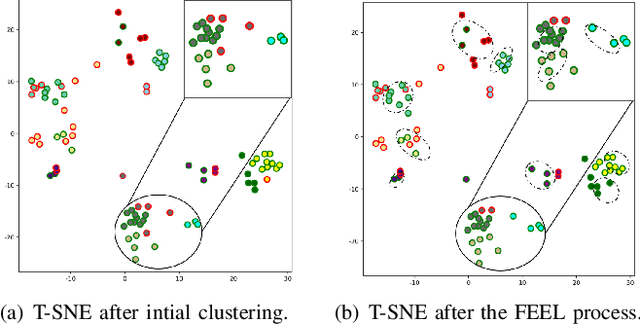
Recently, temporal action localization (TAL) has garnered significant interest in information retrieval community. However, existing supervised/weakly supervised methods are heavily dependent on extensive labeled temporal boundaries and action categories, which is labor-intensive and time-consuming. Although some unsupervised methods have utilized the ``iteratively clustering and localization'' paradigm for TAL, they still suffer from two pivotal impediments: 1) unsatisfactory video clustering confidence, and 2) unreliable video pseudolabels for model training. To address these limitations, we present a novel self-paced incremental learning model to enhance clustering and localization training simultaneously, thereby facilitating more effective unsupervised TAL. Concretely, we improve the clustering confidence through exploring the contextual feature-robust visual information. Thereafter, we design two (constant- and variable- speed) incremental instance learning strategies for easy-to-hard model training, thus ensuring the reliability of these video pseudolabels and further improving overall localization performance. Extensive experiments on two public datasets have substantiated the superiority of our model over several state-of-the-art competitors.
Evaluation and Analysis of Hallucination in Large Vision-Language Models
Aug 29, 2023

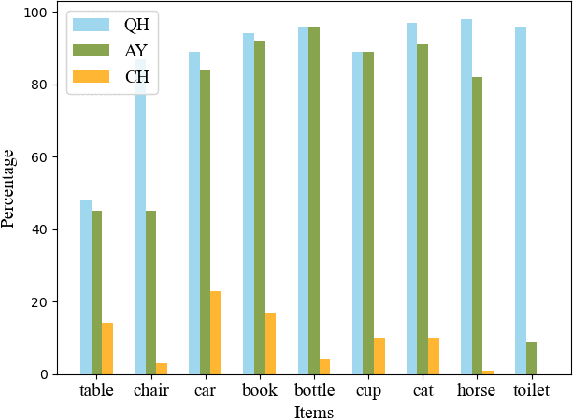
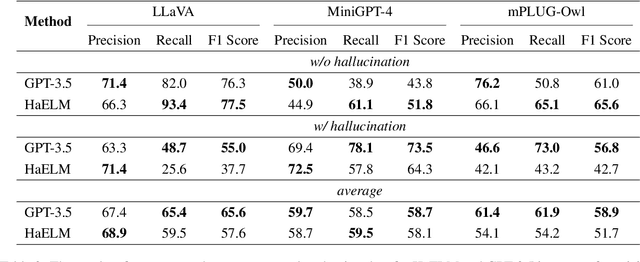
Large Vision-Language Models (LVLMs) have recently achieved remarkable success. However, LVLMs are still plagued by the hallucination problem, which limits the practicality in many scenarios. Hallucination refers to the information of LVLMs' responses that does not exist in the visual input, which poses potential risks of substantial consequences. There has been limited work studying hallucination evaluation in LVLMs. In this paper, we propose Hallucination Evaluation based on Large Language Models (HaELM), an LLM-based hallucination evaluation framework. HaELM achieves an approximate 95% performance comparable to ChatGPT and has additional advantages including low cost, reproducibility, privacy preservation and local deployment. Leveraging the HaELM, we evaluate the hallucination in current LVLMs. Furthermore, we analyze the factors contributing to hallucination in LVLMs and offer helpful suggestions to mitigate the hallucination problem. Our training data and human annotation hallucination data will be made public soon.
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.