 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Joint Knowledge and Power Management for Secure Semantic Communication Networks
Apr 21, 2025Recently, semantic communication (SemCom) has shown its great superiorities in resource savings and information exchanges. However, while its unique background knowledge guarantees accurate semantic reasoning and recovery, semantic information security-related concerns are introduced at the same time. Since the potential eavesdroppers may have the same background knowledge to accurately decrypt the private semantic information transmitted between legal SemCom users, this makes the knowledge management in SemCom networks rather challenging in joint consideration with the power control. To this end, this paper focuses on jointly addressing three core issues of power allocation, knowledge base caching (KBC), and device-to-device (D2D) user pairing (DUP) in secure SemCom networks. We first develop a novel performance metric, namely semantic secrecy throughput (SST), to quantify the information security level that can be achieved at each pair of D2D SemCom users. Next, an SST maximization problem is formulated subject to secure SemCom-related delay and reliability constraints. Afterward, we propose a security-aware resource management solution using the Lagrange primal-dual method and a two-stage method. Simulation results demonstrate our proposed solution nearly doubles the SST performance and realizes less than half of the queuing delay performance compared to different benchmarks.
MVPbev: Multi-view Perspective Image Generation from BEV with Test-time Controllability and Generalizability
Jul 28, 2024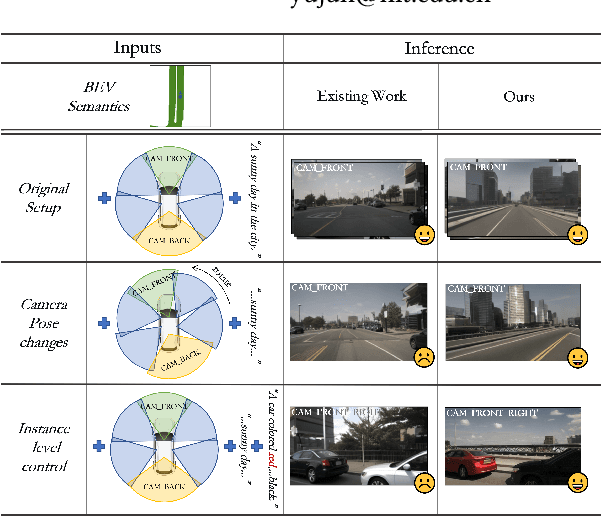
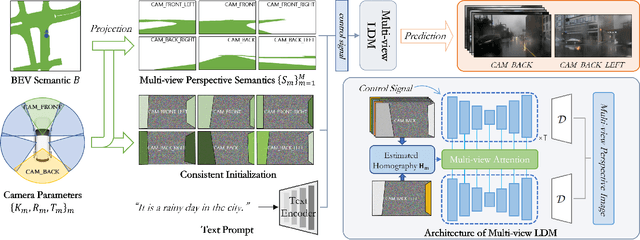
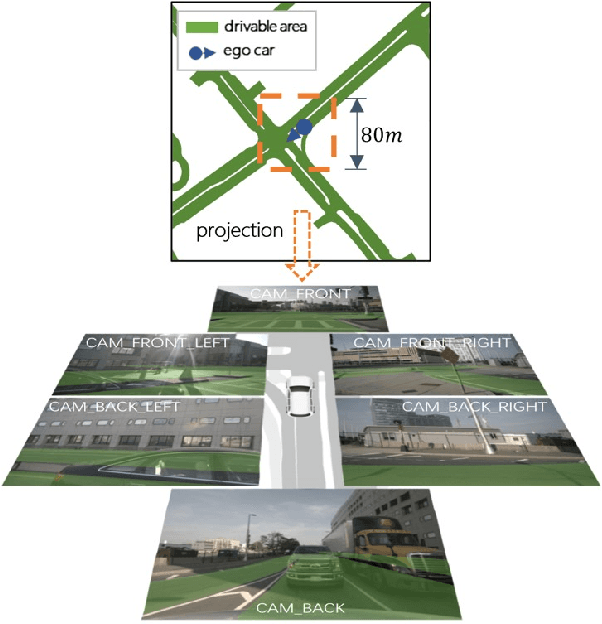
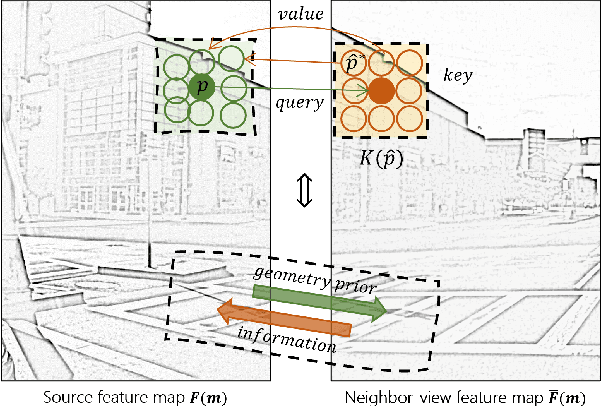
This work aims to address the multi-view perspective RGB generation from text prompts given Bird-Eye-View(BEV) semantics. Unlike prior methods that neglect layout consistency, lack the ability to handle detailed text prompts, or are incapable of generalizing to unseen view points, MVPbev simultaneously generates cross-view consistent images of different perspective views with a two-stage design, allowing object-level control and novel view generation at test-time. Specifically, MVPbev firstly projects given BEV semantics to perspective view with camera parameters, empowering the model to generalize to unseen view points. Then we introduce a multi-view attention module where special initialization and de-noising processes are introduced to explicitly enforce local consistency among overlapping views w.r.t. cross-view homography. Last but not least, MVPbev further allows test-time instance-level controllability by refining a pre-trained text-to-image diffusion model. Our extensive experiments on NuScenes demonstrate that our method is capable of generating high-resolution photorealistic images from text descriptions with thousands of training samples, surpassing the state-of-the-art methods under various evaluation metrics. We further demonstrate the advances of our method in terms of generalizability and controllability with the help of novel evaluation metrics and comprehensive human analysis. Our code, data, and model can be found in \url{https://github.com/kkaiwwana/MVPbev}.