 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Syntactic-Semantic Internet:Engineering Infrastructures for Autonomous Systems
Jan 31, 2026The Internet has evolved through successive architectural abstractions that enabled unprecedented scale, interoperability, and innovation. Packet-based networking enabled the reliable transport of bits; cloud-native systems enabled the orchestration of distributed computation. Today, the emergence of autonomous, learning-based systems introduces a new architectural challenge: intelligence is increasingly embedded directly into network control, computation, and decision-making, yet the Internet lacks a structural foundation for representing and exchanging meaning. In this paper, we argue that cognition alone: pattern recognition, prediction, and optimization, is insufficient for the next generation of networked systems. As autonomous agents act across safety-critical and socio-technical domains, systems must not only compute and communicate, but also comprehend intent, context, and consequence. We introduce the concept of a Semantic Layer: a new architectural stratum that treats meaning as a first-class construct, enabling interpretive alignment, semantic accountability, and intelligible autonomous behavior. We show that this evolution leads naturally to a Syntactic-Semantic Internet. The syntactic stack continues to transport bits, packets, and workloads with speed and reliability, while a parallel semantic stack transports meaning, grounding, and consequence. We describe the structure of this semantic stack-semantic communication, a semantic substrate, and an emerging Agentic Web, and draw explicit architectural parallels to TCP/IP and the World Wide Web. Finally, we examine current industry efforts, identify critical architectural gaps, and outline the engineering challenges required to make semantic interoperability a global, interoperable infrastructure.
A Survey on Semantic Communication for Vision: Categories, Frameworks, Enabling Techniques, and Applications
Jan 29, 2026Semantic communication (SemCom) emerges as a transformative paradigm for traffic-intensive visual data transmission, shifting focus from raw data to meaningful content transmission and relieving the increasing pressure on communication resources. However, to achieve SemCom, challenges are faced in accurate semantic quantization for visual data, robust semantic extraction and reconstruction under diverse tasks and goals, transceiver coordination with effective knowledge utilization, and adaptation to unpredictable wireless communication environments. In this paper, we present a systematic review of SemCom for visual data transmission (SemCom-Vision), wherein an interdisciplinary analysis integrating computer vision (CV) and communication engineering is conducted to provide comprehensive guidelines for the machine learning (ML)-empowered SemCom-Vision design. Specifically, this survey first elucidates the basics and key concepts of SemCom. Then, we introduce a novel classification perspective to categorize existing SemCom-Vision approaches as semantic preservation communication (SPC), semantic expansion communication (SEC), and semantic refinement communication (SRC) based on communication goals interpreted through semantic quantization schemes. Moreover, this survey articulates the ML-based encoder-decoder models and training algorithms for each SemCom-Vision category, followed by knowledge structure and utilization strategies. Finally, we discuss potential SemCom-Vision applications.
A Deep Dive into OpenStreetMap Research Since its Inception (2008-2024): Contributors, Topics, and Future Trends
Jan 14, 2026OpenStreetMap (OSM) has transitioned from a pioneering volunteered geographic information (VGI) project into a global, multi-disciplinary research nexus. This study presents a bibliometric and systematic analysis of the OSM research landscape, examining its development trajectory and key driving forces. By evaluating 1,926 publications from the Web of Science (WoS) Core Collection and 782 State of the Map (SotM) presentations up to June 2024, we quantify publication growth, collaboration patterns, and thematic evolution. Results demonstrate simultaneous consolidation and diversification within the field. While a stable core of contributors continues to anchor OSM research, themes have shifted from initial concerns over data production and quality toward advanced analytical and applied uses. Comparative analysis of OSM-related research in WoS and SotM reveals distinct but complementary agendas between scholars and the OSM community. Building on these findings, we identify six emerging research directions and discuss how evolving partnerships among academia, the OSM community, and industry are poised to shape the future of OSM research. This study establishes a structured reference for understanding the state of OSM studies and offers strategic pathways for navigating its future trajectory.The data and code are available at https://github.com/ya0-sun/OSMbib.
QoE Optimization for Semantic Self-Correcting Video Transmission in Multi-UAV Networks
Jul 09, 2025
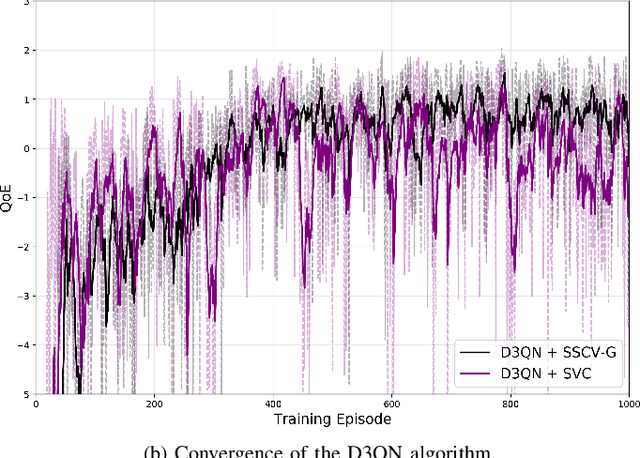
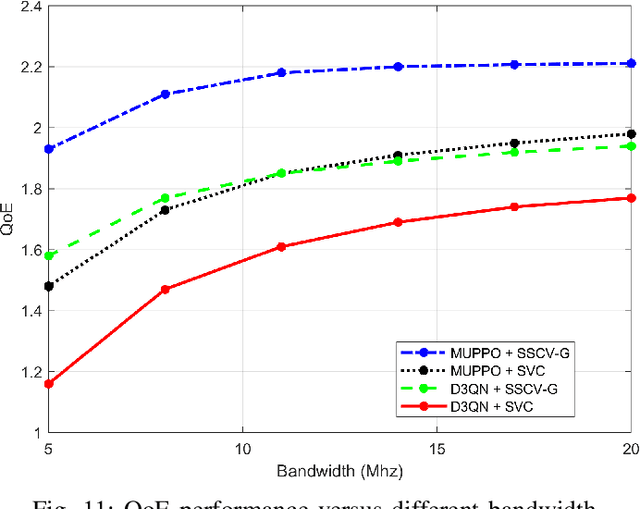
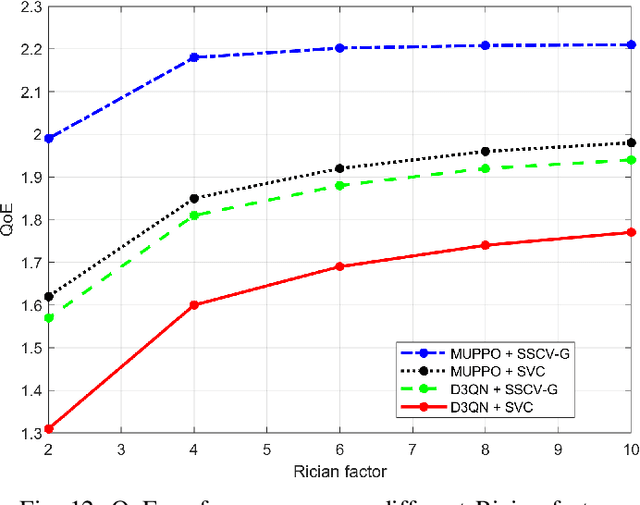
Real-time unmanned aerial vehicle (UAV) video streaming is essential for time-sensitive applications, including remote surveillance, emergency response, and environmental monitoring. However, it faces challenges such as limited bandwidth, latency fluctuations, and high packet loss. To address these issues, we propose a novel semantic self-correcting video transmission framework with ultra-fine bitrate granularity (SSCV-G). In SSCV-G, video frames are encoded into a compact semantic codebook space, and the transmitter adaptively sends a subset of semantic indices based on bandwidth availability, enabling fine-grained bitrate control for improved bandwidth efficiency. At the receiver, a spatio-temporal vision transformer (ST-ViT) performs multi-frame joint decoding to reconstruct dropped semantic indices by modeling intra- and inter-frame dependencies. To further improve performance under dynamic network conditions, we integrate a multi-user proximal policy optimization (MUPPO) reinforcement learning scheme that jointly optimizes communication resource allocation and semantic bitrate selection to maximize user Quality of Experience (QoE). Extensive experiments demonstrate that the proposed SSCV-G significantly outperforms state-of-the-art video codecs in coding efficiency, bandwidth adaptability, and packet loss robustness. Moreover, the proposed MUPPO-based QoE optimization consistently surpasses existing benchmarks.
Building Floor Number Estimation from Crowdsourced Street-Level Images: Munich Dataset and Baseline Method
May 23, 2025Accurate information on the number of building floors, or above-ground storeys, is essential for household estimation, utility provision, risk assessment, evacuation planning, and energy modeling. Yet large-scale floor-count data are rarely available in cadastral and 3D city databases. This study proposes an end-to-end deep learning framework that infers floor numbers directly from unrestricted, crowdsourced street-level imagery, avoiding hand-crafted features and generalizing across diverse facade styles. To enable benchmarking, we release the Munich Building Floor Dataset, a public set of over 6800 geo-tagged images collected from Mapillary and targeted field photography, each paired with a verified storey label. On this dataset, the proposed classification-regression network attains 81.2% exact accuracy and predicts 97.9% of buildings within +/-1 floor. The method and dataset together offer a scalable route to enrich 3D city models with vertical information and lay a foundation for future work in urban informatics, remote sensing, and geographic information science. Source code and data will be released under an open license at https://github.com/ya0-sun/Munich-SVI-Floor-Benchmark.
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025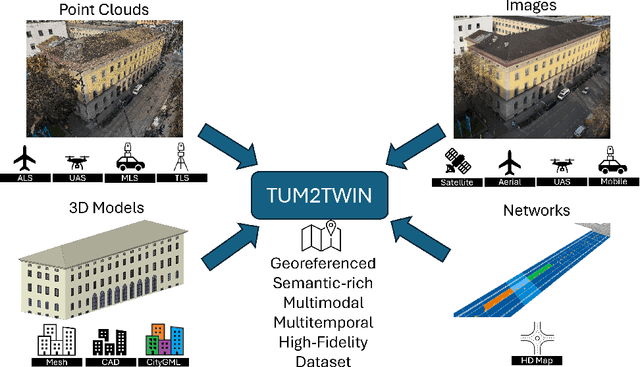
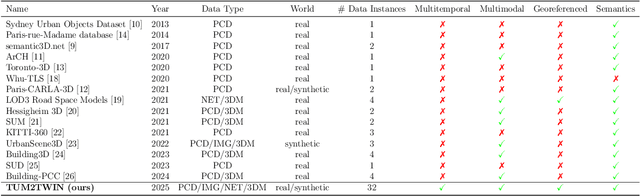

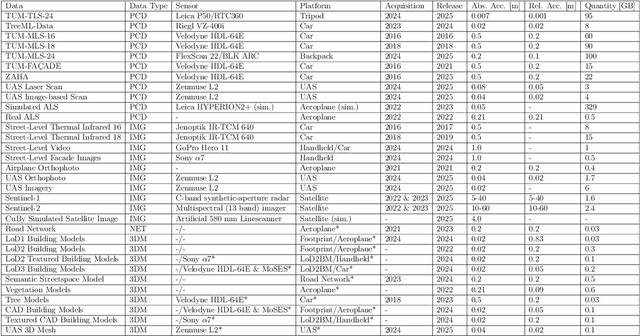
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
Joint Knowledge and Power Management for Secure Semantic Communication Networks
Apr 21, 2025Recently, semantic communication (SemCom) has shown its great superiorities in resource savings and information exchanges. However, while its unique background knowledge guarantees accurate semantic reasoning and recovery, semantic information security-related concerns are introduced at the same time. Since the potential eavesdroppers may have the same background knowledge to accurately decrypt the private semantic information transmitted between legal SemCom users, this makes the knowledge management in SemCom networks rather challenging in joint consideration with the power control. To this end, this paper focuses on jointly addressing three core issues of power allocation, knowledge base caching (KBC), and device-to-device (D2D) user pairing (DUP) in secure SemCom networks. We first develop a novel performance metric, namely semantic secrecy throughput (SST), to quantify the information security level that can be achieved at each pair of D2D SemCom users. Next, an SST maximization problem is formulated subject to secure SemCom-related delay and reliability constraints. Afterward, we propose a security-aware resource management solution using the Lagrange primal-dual method and a two-stage method. Simulation results demonstrate our proposed solution nearly doubles the SST performance and realizes less than half of the queuing delay performance compared to different benchmarks.
Falcon: Fractional Alternating Cut with Overcoming Minima in Unsupervised Segmentation
Apr 08, 2025Today's unsupervised image segmentation algorithms often segment suboptimally. Modern graph-cut based approaches rely on high-dimensional attention maps from Transformer-based foundation models, typically employing a relaxed Normalized Cut solved recursively via the Fiedler vector (the eigenvector of the second smallest eigenvalue). Consequently, they still lag behind supervised methods in both mask generation speed and segmentation accuracy. We present a regularized fractional alternating cut (Falcon), an optimization-based K-way Normalized Cut without relying on recursive eigenvector computations, achieving substantially improved speed and accuracy. Falcon operates in two stages: (1) a fast K-way Normalized Cut solved by extending into a fractional quadratic transformation, with an alternating iterative procedure and regularization to avoid local minima; and (2) refinement of the resulting masks using complementary low-level information, producing high-quality pixel-level segmentations. Experiments show that Falcon not only surpasses existing state-of-the-art methods by an average of 2.5% across six widely recognized benchmarks (reaching up to 4.3\% improvement on Cityscapes), but also reduces runtime by around 30% compared to prior graph-based approaches. These findings demonstrate that the semantic information within foundation-model attention can be effectively harnessed by a highly parallelizable graph cut framework. Consequently, Falcon can narrow the gap between unsupervised and supervised segmentation, enhancing scalability in real-world applications and paving the way for dense prediction-based vision pre-training in various downstream tasks. The code is released in https://github.com/KordingLab/Falcon.
A semantic communication-based workload-adjustable transceiver for wireless AI-generated content (AIGC) delivery
Mar 24, 2025With the significant advances in generative AI (GAI) and the proliferation of mobile devices, providing high-quality AI-generated content (AIGC) services via wireless networks is becoming the future direction. However, the primary challenges of AIGC service delivery in wireless networks lie in unstable channels, limited bandwidth resources, and unevenly distributed computational resources. In this paper, we employ semantic communication (SemCom) in diffusion-based GAI models to propose a Resource-aware wOrkload-adjUstable TransceivEr (ROUTE) for AIGC delivery in dynamic wireless networks. Specifically, to relieve the communication resource bottleneck, SemCom is utilized to prioritize semantic information of the generated content. Then, to improve computational resource utilization in both edge and local and reduce AIGC semantic distortion in transmission, modified diffusion-based models are applied to adjust the computing workload and semantic density in cooperative content generation. Simulations verify the superiority of our proposed ROUTE in terms of latency and content quality compared to conventional AIGC approaches.
Semantic Communication for the Internet of Sounds: Architecture, Design Principles, and Challenges
Jul 16, 2024



The Internet of Sounds (IoS) combines sound sensing, processing, and transmission techniques, enabling collaboration among diverse sound devices. To achieve perceptual quality of sound synchronization in the IoS, it is necessary to precisely synchronize three critical factors: sound quality, timing, and behavior control. However, conventional bit-oriented communication, which focuses on bit reproduction, may not be able to fulfill these synchronization requirements under dynamic channel conditions. One promising approach to address the synchronization challenges of the IoS is through the use of semantic communication (SC) that can capture and leverage the logical relationships in its source data. Consequently, in this paper, we propose an IoS-centric SC framework with a transceiver design. The designed encoder extracts semantic information from diverse sources and transmits it to IoS listeners. It can also distill important semantic information to reduce transmission latency for timing synchronization. At the receiver's end, the decoder employs context- and knowledge-based reasoning techniques to reconstruct and integrate sounds, which achieves sound quality synchronization across diverse communication environments. Moreover, by periodically sharing knowledge, SC models of IoS devices can be updated to optimize their synchronization behavior. Finally, we explore several open issues on mathematical models, resource allocation, and cross-layer protocols.