 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgus: Resilience-Oriented Safety Assurance Framework for End-to-End ADSs
Nov 12, 2025End-to-end autonomous driving systems (ADSs), with their strong capabilities in environmental perception and generalizable driving decisions, are attracting growing attention from both academia and industry. However, once deployed on public roads, ADSs are inevitably exposed to diverse driving hazards that may compromise safety and degrade system performance. This raises a strong demand for resilience of ADSs, particularly the capability to continuously monitor driving hazards and adaptively respond to potential safety violations, which is crucial for maintaining robust driving behaviors in complex driving scenarios. To bridge this gap, we propose a runtime resilience-oriented framework, Argus, to mitigate the driving hazards, thus preventing potential safety violations and improving the driving performance of an ADS. Argus continuously monitors the trajectories generated by the ADS for potential hazards and, whenever the EGO vehicle is deemed unsafe, seamlessly takes control through a hazard mitigator. We integrate Argus with three state-of-the-art end-to-end ADSs, i.e., TCP, UniAD and VAD. Our evaluation has demonstrated that Argus effectively and efficiently enhances the resilience of ADSs, improving the driving score of the ADS by up to 150.30% on average, and preventing up to 64.38% of the violations, with little additional time overhead.
* The paper has been accepted by the 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025
Building Floor Number Estimation from Crowdsourced Street-Level Images: Munich Dataset and Baseline Method
May 23, 2025Accurate information on the number of building floors, or above-ground storeys, is essential for household estimation, utility provision, risk assessment, evacuation planning, and energy modeling. Yet large-scale floor-count data are rarely available in cadastral and 3D city databases. This study proposes an end-to-end deep learning framework that infers floor numbers directly from unrestricted, crowdsourced street-level imagery, avoiding hand-crafted features and generalizing across diverse facade styles. To enable benchmarking, we release the Munich Building Floor Dataset, a public set of over 6800 geo-tagged images collected from Mapillary and targeted field photography, each paired with a verified storey label. On this dataset, the proposed classification-regression network attains 81.2% exact accuracy and predicts 97.9% of buildings within +/-1 floor. The method and dataset together offer a scalable route to enrich 3D city models with vertical information and lay a foundation for future work in urban informatics, remote sensing, and geographic information science. Source code and data will be released under an open license at https://github.com/ya0-sun/Munich-SVI-Floor-Benchmark.
Who Gets Recommended? Investigating Gender, Race, and Country Disparities in Paper Recommendations from Large Language Models
Dec 31, 2024



This paper investigates the performance of several representative large models in the tasks of literature recommendation and explores potential biases in research exposure. The results indicate that not only LLMs' overall recommendation accuracy remains limited but also the models tend to recommend literature with greater citation counts, later publication date, and larger author teams. Yet, in scholar recommendation tasks, there is no evidence that LLMs disproportionately recommend male, white, or developed-country authors, contrasting with patterns of known human biases.
AdvFuzz: Finding More Violations Caused by the EGO Vehicle in Simulation Testing by Adversarial NPC Vehicles
Nov 29, 2024



Recently, there has been a significant escalation in both academic and industrial commitment towards the development of autonomous driving systems (ADSs). A number of simulation testing approaches have been proposed to generate diverse driving scenarios for ADS testing. However, scenarios generated by these previous approaches are static and lack interactions between the EGO vehicle and the NPC vehicles, resulting in a large amount of time on average to find violation scenarios. Besides, a large number of the violations they found are caused by aggressive behaviors of NPC vehicles, revealing none bugs of ADS. In this work, we propose the concept of adversarial NPC vehicles and introduce AdvFuzz, a novel simulation testing approach, to generate adversarial scenarios on main lanes (e.g., urban roads and highways). AdvFuzz allows NPC vehicles to dynamically interact with the EGO vehicle and regulates the behaviors of NPC vehicles, finding more violation scenarios caused by the EGO vehicle more quickly. We compare AdvFuzz with a random approach and three state-of-the-art scenario-based testing approaches. Our experiments demonstrate that AdvFuzz can generate 198.34% more violation scenarios compared to the other four approaches in 12 hours and increase the proportion of violations caused by the EGO vehicle to 87.04%, which is more than 7 times that of other approaches. Additionally, AdvFuzz is at least 92.21% faster in finding one violation caused by the EGO vehicle than that of the other approaches.
Towards Large-scale Building Attribute Mapping using Crowdsourced Images: Scene Text Recognition on Flickr and Problems to be Solved
Sep 14, 2023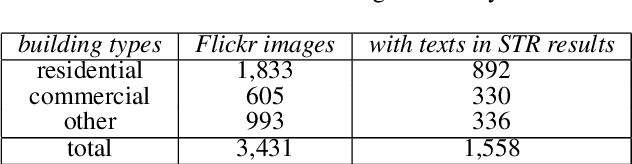

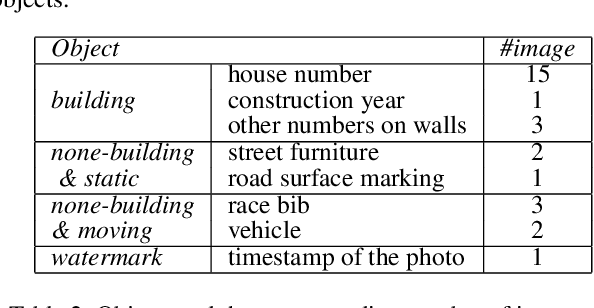

Crowdsourced platforms provide huge amounts of street-view images that contain valuable building information. This work addresses the challenges in applying Scene Text Recognition (STR) in crowdsourced street-view images for building attribute mapping. We use Flickr images, particularly examining texts on building facades. A Berlin Flickr dataset is created, and pre-trained STR models are used for text detection and recognition. Manual checking on a subset of STR-recognized images demonstrates high accuracy. We examined the correlation between STR results and building functions, and analysed instances where texts were recognized on residential buildings but not on commercial ones. Further investigation revealed significant challenges associated with this task, including small text regions in street-view images, the absence of ground truth labels, and mismatches in buildings in Flickr images and building footprints in OpenStreetMap (OSM). To develop city-wide mapping beyond urban hotspot locations, we suggest differentiating the scenarios where STR proves effective while developing appropriate algorithms or bringing in additional data for handling other cases. Furthermore, interdisciplinary collaboration should be undertaken to understand the motivation behind building photography and labeling. The STR-on-Flickr results are publicly available at https://github.com/ya0-sun/STR-Berlin.
Investigating Robustness and Interpretability of Link Prediction via Adversarial Modifications
May 02, 2019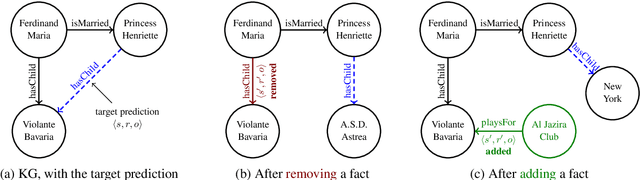
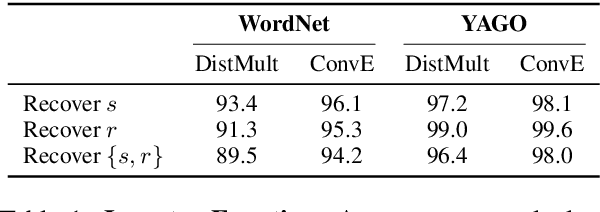
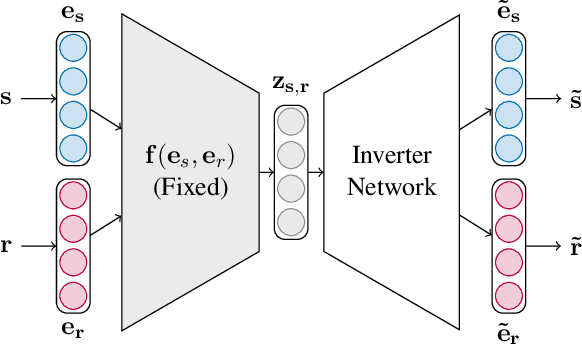

Representing entities and relations in an embedding space is a well-studied approach for machine learning on relational data. Existing approaches, however, primarily focus on improving accuracy and overlook other aspects such as robustness and interpretability. In this paper, we propose adversarial modifications for link prediction models: identifying the fact to add into or remove from the knowledge graph that changes the prediction for a target fact after the model is retrained. Using these single modifications of the graph, we identify the most influential fact for a predicted link and evaluate the sensitivity of the model to the addition of fake facts. We introduce an efficient approach to estimate the effect of such modifications by approximating the change in the embeddings when the knowledge graph changes. To avoid the combinatorial search over all possible facts, we train a network to decode embeddings to their corresponding graph components, allowing the use of gradient-based optimization to identify the adversarial modification. We use these techniques to evaluate the robustness of link prediction models (by measuring sensitivity to additional facts), study interpretability through the facts most responsible for predictions (by identifying the most influential neighbors), and detect incorrect facts in the knowledge base.