 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSE-Net: Semi-supervised Monocular Height Estimation from Single Remote Sensing Images
Nov 17, 2025


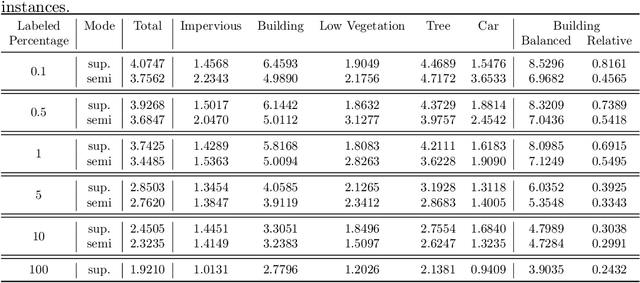
Monocular height estimation plays a critical role in 3D perception for remote sensing, offering a cost-effective alternative to multi-view or LiDAR-based methods. While deep learning has significantly advanced the capabilities of monocular height estimation, these methods remain fundamentally limited by the availability of labeled data, which are expensive and labor-intensive to obtain at scale. The scarcity of high-quality annotations hinders the generalization and performance of existing models. To overcome this limitation, we propose leveraging large volumes of unlabeled data through a semi-supervised learning framework, enabling the model to extract informative cues from unlabeled samples and improve its predictive performance. In this work, we introduce TSE-Net, a self-training pipeline for semi-supervised monocular height estimation. The pipeline integrates teacher, student, and exam networks. The student network is trained on unlabeled data using pseudo-labels generated by the teacher network, while the exam network functions as a temporal ensemble of the student network to stabilize performance. The teacher network is formulated as a joint regression and classification model: the regression branch predicts height values that serve as pseudo-labels, and the classification branch predicts height value classes along with class probabilities, which are used to filter pseudo-labels. Height value classes are defined using a hierarchical bi-cut strategy to address the inherent long-tailed distribution of heights, and the predicted class probabilities are calibrated with a Plackett-Luce model to reflect the expected accuracy of pseudo-labels. We evaluate the proposed pipeline on three datasets spanning different resolutions and imaging modalities. Codes are available at https://github.com/zhu-xlab/tse-net.
GlobalBuildingAtlas: An Open Global and Complete Dataset of Building Polygons, Heights and LoD1 3D Models
Jun 04, 2025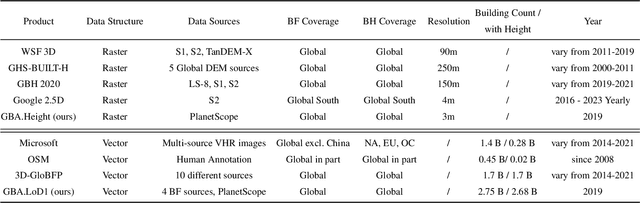
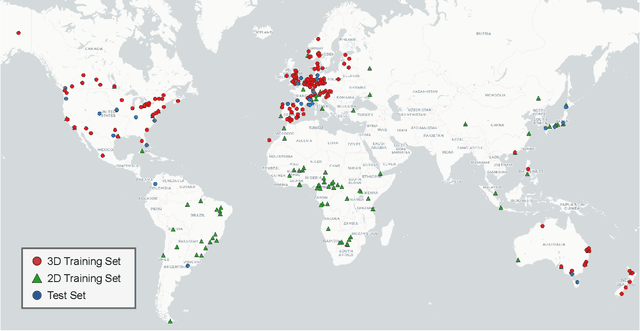
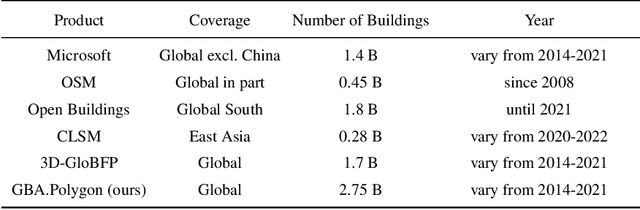
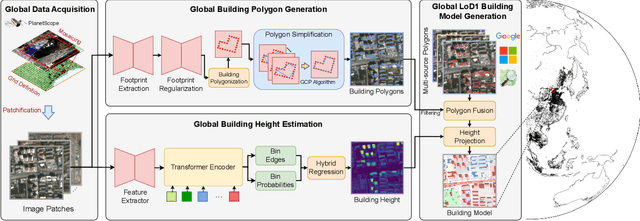
We introduce GlobalBuildingAtlas, a publicly available dataset providing global and complete coverage of building polygons, heights and Level of Detail 1 (LoD1) 3D building models. This is the first open dataset to offer high quality, consistent, and complete building data in 2D and 3D form at the individual building level on a global scale. Towards this dataset, we developed machine learning-based pipelines to derive building polygons and heights (called GBA.Height) from global PlanetScope satellite data, respectively. Also a quality-based fusion strategy was employed to generate higher-quality polygons (called GBA.Polygon) based on existing open building polygons, including our own derived one. With more than 2.75 billion buildings worldwide, GBA.Polygon surpasses the most comprehensive database to date by more than 1 billion buildings. GBA.Height offers the most detailed and accurate global 3D building height maps to date, achieving a spatial resolution of 3x3 meters-30 times finer than previous global products (90 m), enabling a high-resolution and reliable analysis of building volumes at both local and global scales. Finally, we generated a global LoD1 building model (called GBA.LoD1) from the resulting GBA.Polygon and GBA.Height. GBA.LoD1 represents the first complete global LoD1 building models, including 2.68 billion building instances with predicted heights, i.e., with a height completeness of more than 97%, achieving RMSEs ranging from 1.5 m to 8.9 m across different continents. With its height accuracy, comprehensive global coverage and rich spatial details, GlobalBuildingAltas offers novel insights on the status quo of global buildings, which unlocks unprecedented geospatial analysis possibilities, as showcased by a better illustration of where people live and a more comprehensive monitoring of the progress on the 11th Sustainable Development Goal of the United Nations.
Building Floor Number Estimation from Crowdsourced Street-Level Images: Munich Dataset and Baseline Method
May 23, 2025Accurate information on the number of building floors, or above-ground storeys, is essential for household estimation, utility provision, risk assessment, evacuation planning, and energy modeling. Yet large-scale floor-count data are rarely available in cadastral and 3D city databases. This study proposes an end-to-end deep learning framework that infers floor numbers directly from unrestricted, crowdsourced street-level imagery, avoiding hand-crafted features and generalizing across diverse facade styles. To enable benchmarking, we release the Munich Building Floor Dataset, a public set of over 6800 geo-tagged images collected from Mapillary and targeted field photography, each paired with a verified storey label. On this dataset, the proposed classification-regression network attains 81.2% exact accuracy and predicts 97.9% of buildings within +/-1 floor. The method and dataset together offer a scalable route to enrich 3D city models with vertical information and lay a foundation for future work in urban informatics, remote sensing, and geographic information science. Source code and data will be released under an open license at https://github.com/ya0-sun/Munich-SVI-Floor-Benchmark.
HTC-DC Net: Monocular Height Estimation from Single Remote Sensing Images
Sep 28, 20233D geo-information is of great significance for understanding the living environment; however, 3D perception from remote sensing data, especially on a large scale, is restricted. To tackle this problem, we propose a method for monocular height estimation from optical imagery, which is currently one of the richest sources of remote sensing data. As an ill-posed problem, monocular height estimation requires well-designed networks for enhanced representations to improve performance. Moreover, the distribution of height values is long-tailed with the low-height pixels, e.g., the background, as the head, and thus trained networks are usually biased and tend to underestimate building heights. To solve the problems, instead of formalizing the problem as a regression task, we propose HTC-DC Net following the classification-regression paradigm, with the head-tail cut (HTC) and the distribution-based constraints (DCs) as the main contributions. HTC-DC Net is composed of the backbone network as the feature extractor, the HTC-AdaBins module, and the hybrid regression process. The HTC-AdaBins module serves as the classification phase to determine bins adaptive to each input image. It is equipped with a vision transformer encoder to incorporate local context with holistic information and involves an HTC to address the long-tailed problem in monocular height estimation for balancing the performances of foreground and background pixels. The hybrid regression process does the regression via the smoothing of bins from the classification phase, which is trained via DCs. The proposed network is tested on three datasets of different resolutions, namely ISPRS Vaihingen (0.09 m), DFC19 (1.3 m) and GBH (3 m). Experimental results show the superiority of the proposed network over existing methods by large margins. Extensive ablation studies demonstrate the effectiveness of each design component.
GAMUS: A Geometry-aware Multi-modal Semantic Segmentation Benchmark for Remote Sensing Data
May 24, 2023Geometric information in the normalized digital surface models (nDSM) is highly correlated with the semantic class of the land cover. Exploiting two modalities (RGB and nDSM (height)) jointly has great potential to improve the segmentation performance. However, it is still an under-explored field in remote sensing due to the following challenges. First, the scales of existing datasets are relatively small and the diversity of existing datasets is limited, which restricts the ability of validation. Second, there is a lack of unified benchmarks for performance assessment, which leads to difficulties in comparing the effectiveness of different models. Last, sophisticated multi-modal semantic segmentation methods have not been deeply explored for remote sensing data. To cope with these challenges, in this paper, we introduce a new remote-sensing benchmark dataset for multi-modal semantic segmentation based on RGB-Height (RGB-H) data. Towards a fair and comprehensive analysis of existing methods, the proposed benchmark consists of 1) a large-scale dataset including co-registered RGB and nDSM pairs and pixel-wise semantic labels; 2) a comprehensive evaluation and analysis of existing multi-modal fusion strategies for both convolutional and Transformer-based networks on remote sensing data. Furthermore, we propose a novel and effective Transformer-based intermediary multi-modal fusion (TIMF) module to improve the semantic segmentation performance through adaptive token-level multi-modal fusion.The designed benchmark can foster future research on developing new methods for multi-modal learning on remote sensing data. Extensive analyses of those methods are conducted and valuable insights are provided through the experimental results. Code for the benchmark and baselines can be accessed at \url{https://github.com/EarthNets/RSI-MMSegmentation}.
Disentangled Latent Transformer for Interpretable Monocular Height Estimation
Feb 02, 2022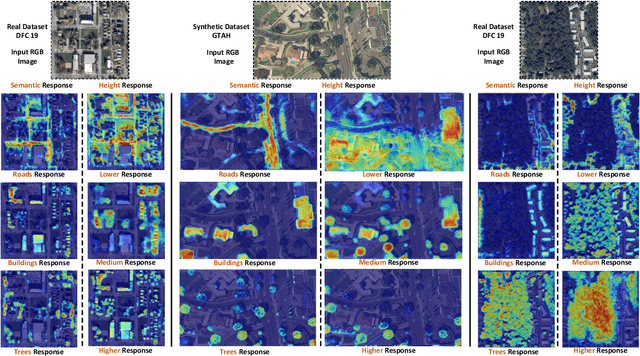
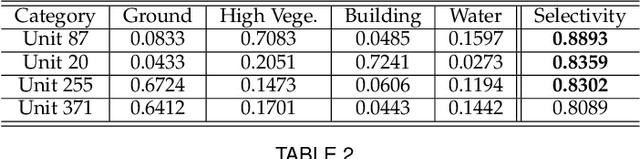
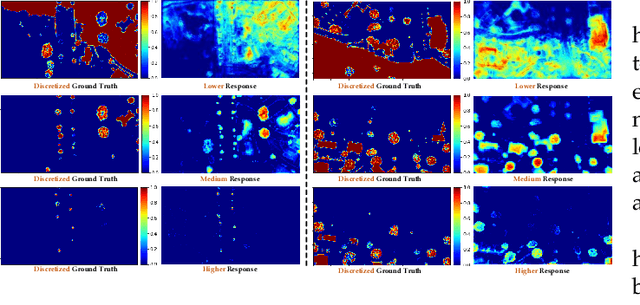

Monocular height estimation (MHE) from remote sensing imagery has high potential in generating 3D city models efficiently for a quick response to natural disasters. Most existing works pursue higher performance. However, there is little research exploring the interpretability of MHE networks. In this paper, we target at exploring how deep neural networks predict height from a single monocular image. Towards a comprehensive understanding of MHE networks, we propose to interpret them from multiple levels: 1) Neurons: unit-level dissection. Exploring the semantic and height selectivity of the learned internal deep representations; 2) Instances: object-level interpretation. Studying the effects of different semantic classes, scales, and spatial contexts on height estimation; 3) Attribution: pixel-level analysis. Understanding which input pixels are important for the height estimation. Based on the multi-level interpretation, a disentangled latent Transformer network is proposed towards a more compact, reliable, and explainable deep model for monocular height estimation. Furthermore, a novel unsupervised semantic segmentation task based on height estimation is first introduced in this work. Additionally, we also construct a new dataset for joint semantic segmentation and height estimation. Our work provides novel insights for both understanding and designing MHE models.