 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalBuildingAtlas: An Open Global and Complete Dataset of Building Polygons, Heights and LoD1 3D Models
Jun 04, 2025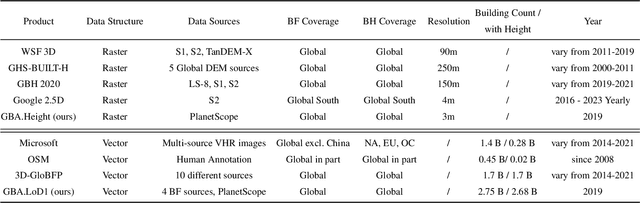
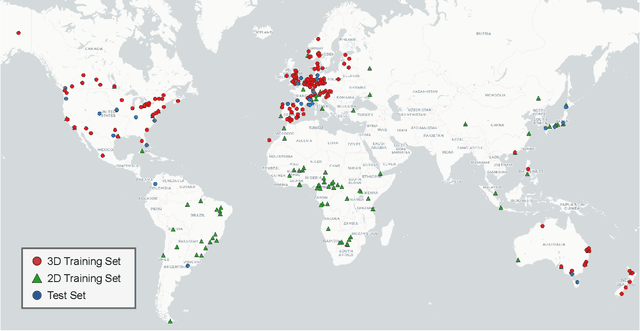
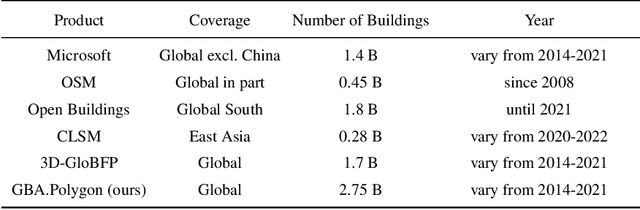
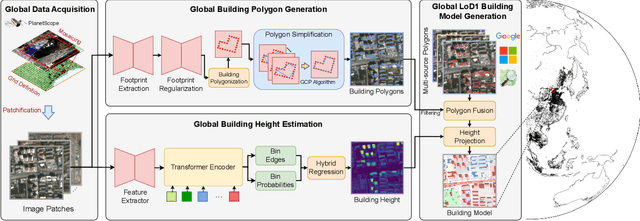
We introduce GlobalBuildingAtlas, a publicly available dataset providing global and complete coverage of building polygons, heights and Level of Detail 1 (LoD1) 3D building models. This is the first open dataset to offer high quality, consistent, and complete building data in 2D and 3D form at the individual building level on a global scale. Towards this dataset, we developed machine learning-based pipelines to derive building polygons and heights (called GBA.Height) from global PlanetScope satellite data, respectively. Also a quality-based fusion strategy was employed to generate higher-quality polygons (called GBA.Polygon) based on existing open building polygons, including our own derived one. With more than 2.75 billion buildings worldwide, GBA.Polygon surpasses the most comprehensive database to date by more than 1 billion buildings. GBA.Height offers the most detailed and accurate global 3D building height maps to date, achieving a spatial resolution of 3x3 meters-30 times finer than previous global products (90 m), enabling a high-resolution and reliable analysis of building volumes at both local and global scales. Finally, we generated a global LoD1 building model (called GBA.LoD1) from the resulting GBA.Polygon and GBA.Height. GBA.LoD1 represents the first complete global LoD1 building models, including 2.68 billion building instances with predicted heights, i.e., with a height completeness of more than 97%, achieving RMSEs ranging from 1.5 m to 8.9 m across different continents. With its height accuracy, comprehensive global coverage and rich spatial details, GlobalBuildingAltas offers novel insights on the status quo of global buildings, which unlocks unprecedented geospatial analysis possibilities, as showcased by a better illustration of where people live and a more comprehensive monitoring of the progress on the 11th Sustainable Development Goal of the United Nations.
Global Collinearity-aware Polygonizer for Polygonal Building Mapping in Remote Sensing
May 02, 2025This paper addresses the challenge of mapping polygonal buildings from remote sensing images and introduces a novel algorithm, the Global Collinearity-aware Polygonizer (GCP). GCP, built upon an instance segmentation framework, processes binary masks produced by any instance segmentation model. The algorithm begins by collecting polylines sampled along the contours of the binary masks. These polylines undergo a refinement process using a transformer-based regression module to ensure they accurately fit the contours of the targeted building instances. Subsequently, a collinearity-aware polygon simplification module simplifies these refined polylines and generate the final polygon representation. This module employs dynamic programming technique to optimize an objective function that balances the simplicity and fidelity of the polygons, achieving globally optimal solutions. Furthermore, the optimized collinearity-aware objective is seamlessly integrated into network training, enhancing the cohesiveness of the entire pipeline. The effectiveness of GCP has been validated on two public benchmarks for polygonal building mapping. Further experiments reveal that applying the collinearity-aware polygon simplification module to arbitrary polylines, without prior knowledge, enhances accuracy over traditional methods such as the Douglas-Peucker algorithm. This finding underscores the broad applicability of GCP. The code for the proposed method will be made available at https://github.com/zhu-xlab.
CopyLens: Dynamically Flagging Copyrighted Sub-Dataset Contributions to LLM Outputs
Oct 06, 2024



Large Language Models (LLMs) have become pervasive due to their knowledge absorption and text-generation capabilities. Concurrently, the copyright issue for pretraining datasets has been a pressing concern, particularly when generation includes specific styles. Previous methods either focus on the defense of identical copyrighted outputs or find interpretability by individual tokens with computational burdens. However, the gap between them exists, where direct assessments of how dataset contributions impact LLM outputs are missing. Once the model providers ensure copyright protection for data holders, a more mature LLM community can be established. To address these limitations, we introduce CopyLens, a new framework to analyze how copyrighted datasets may influence LLM responses. Specifically, a two-stage approach is employed: First, based on the uniqueness of pretraining data in the embedding space, token representations are initially fused for potential copyrighted texts, followed by a lightweight LSTM-based network to analyze dataset contributions. With such a prior, a contrastive-learning-based non-copyright OOD detector is designed. Our framework can dynamically face different situations and bridge the gap between current copyright detection methods. Experiments show that CopyLens improves efficiency and accuracy by 15.2% over our proposed baseline, 58.7% over prompt engineering methods, and 0.21 AUC over OOD detection baselines.
Neural Plasticity-Inspired Foundation Model for Observing the Earth Crossing Modalities
Mar 22, 2024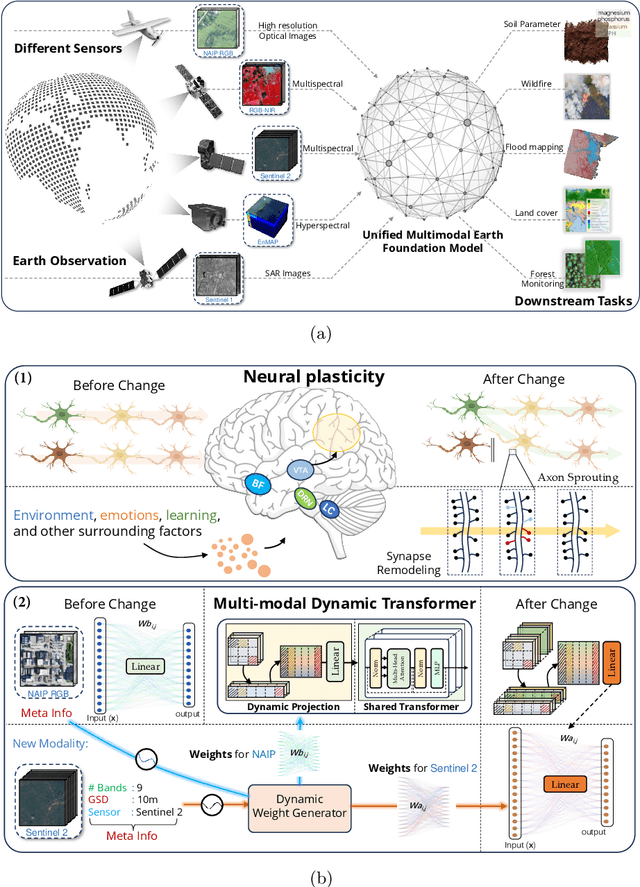
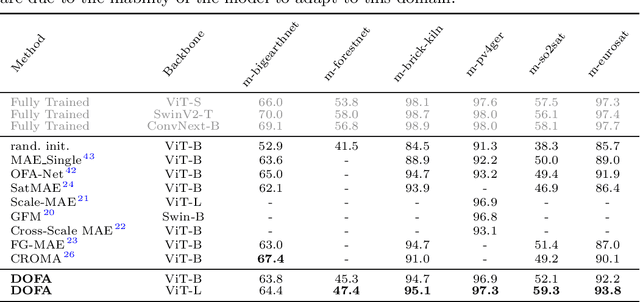
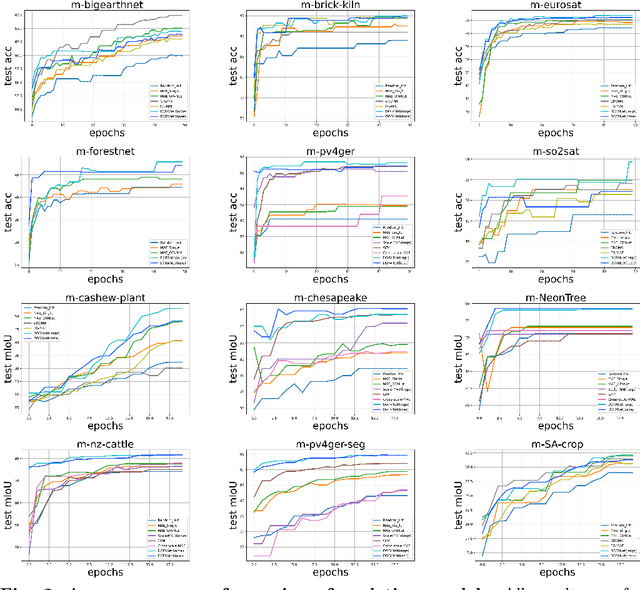
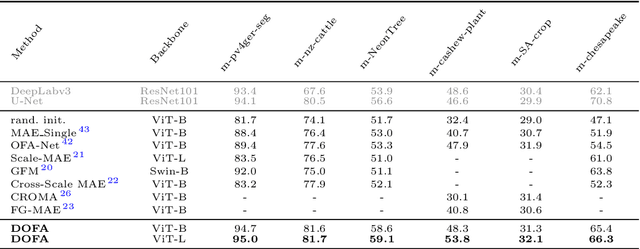
The development of foundation models has revolutionized our ability to interpret the Earth's surface using satellite observational data. Traditional models have been siloed, tailored to specific sensors or data types like optical, radar, and hyperspectral, each with its own unique characteristics. This specialization hinders the potential for a holistic analysis that could benefit from the combined strengths of these diverse data sources. Our novel approach introduces the Dynamic One-For-All (DOFA) model, leveraging the concept of neural plasticity in brain science to integrate various data modalities into a single framework adaptively. This dynamic hypernetwork, adjusting to different wavelengths, enables a single versatile Transformer jointly trained on data from five sensors to excel across 12 distinct Earth observation tasks, including sensors never seen during pretraining. DOFA's innovative design offers a promising leap towards more accurate, efficient, and unified Earth observation analysis, showcasing remarkable adaptability and performance in harnessing the potential of multimodal Earth observation data.
One for All: Toward Unified Foundation Models for Earth Vision
Jan 15, 2024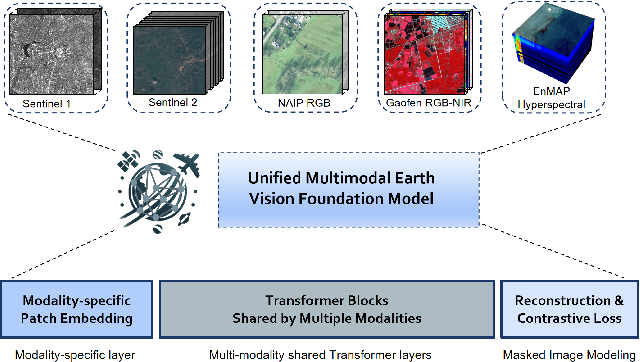

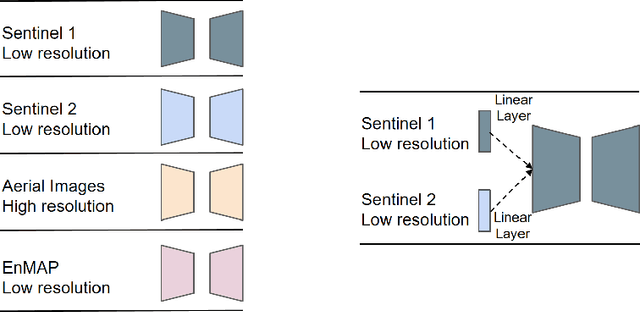

Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.
Self-supervised Domain-agnostic Domain Adaptation for Satellite Images
Sep 25, 2023
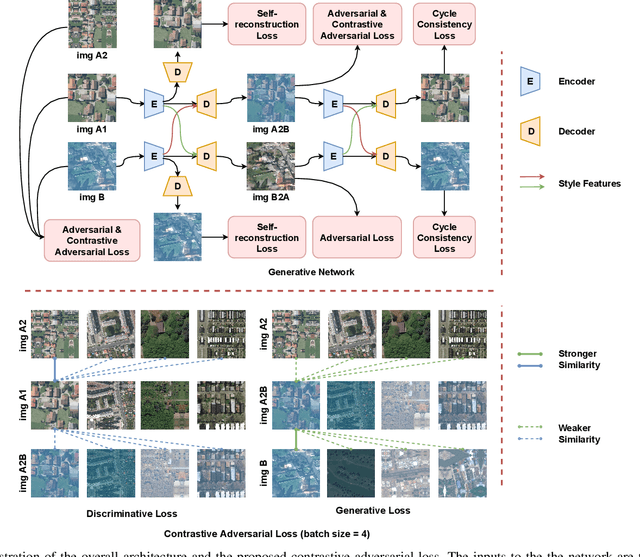

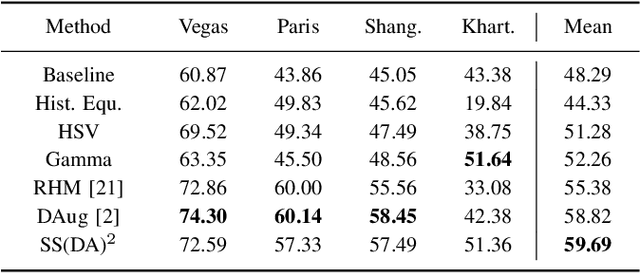
Domain shift caused by, e.g., different geographical regions or acquisition conditions is a common issue in machine learning for global scale satellite image processing. A promising method to address this problem is domain adaptation, where the training and the testing datasets are split into two or multiple domains according to their distributions, and an adaptation method is applied to improve the generalizability of the model on the testing dataset. However, defining the domain to which each satellite image belongs is not trivial, especially under large-scale multi-temporal and multi-sensory scenarios, where a single image mosaic could be generated from multiple data sources. In this paper, we propose an self-supervised domain-agnostic domain adaptation (SS(DA)2) method to perform domain adaptation without such a domain definition. To achieve this, we first design a contrastive generative adversarial loss to train a generative network to perform image-to-image translation between any two satellite image patches. Then, we improve the generalizability of the downstream models by augmenting the training data with different testing spectral characteristics. The experimental results on public benchmarks verify the effectiveness of SS(DA)2.
Few-shot Object Detection in Remote Sensing: Lifting the Curse of Incompletely Annotated Novel Objects
Sep 19, 2023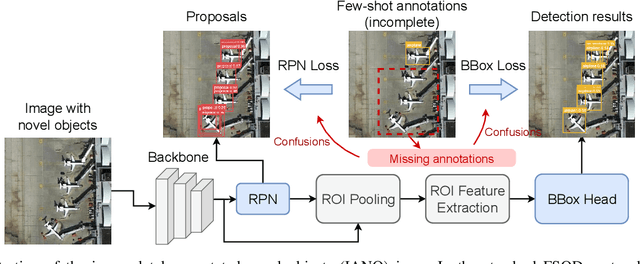
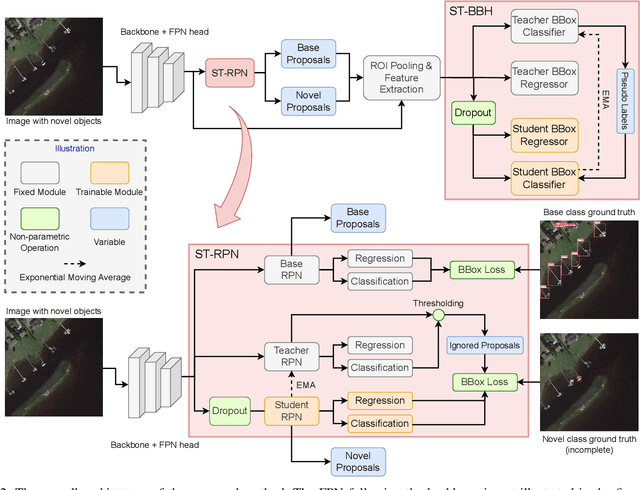
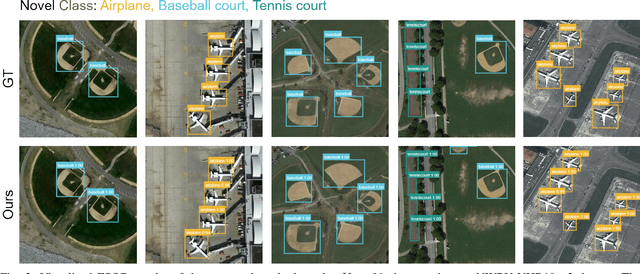
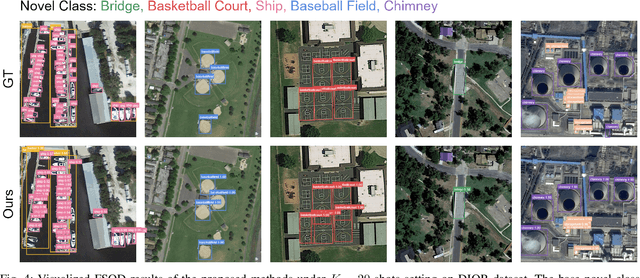
Object detection is an essential and fundamental task in computer vision and satellite image processing. Existing deep learning methods have achieved impressive performance thanks to the availability of large-scale annotated datasets. Yet, in real-world applications the availability of labels is limited. In this context, few-shot object detection (FSOD) has emerged as a promising direction, which aims at enabling the model to detect novel objects with only few of them annotated. However, many existing FSOD algorithms overlook a critical issue: when an input image contains multiple novel objects and only a subset of them are annotated, the unlabeled objects will be considered as background during training. This can cause confusions and severely impact the model's ability to recall novel objects. To address this issue, we propose a self-training-based FSOD (ST-FSOD) approach, which incorporates the self-training mechanism into the few-shot fine-tuning process. ST-FSOD aims to enable the discovery of novel objects that are not annotated, and take them into account during training. On the one hand, we devise a two-branch region proposal networks (RPN) to separate the proposal extraction of base and novel objects, On another hand, we incorporate the student-teacher mechanism into RPN and the region of interest (RoI) head to include those highly confident yet unlabeled targets as pseudo labels. Experimental results demonstrate that our proposed method outperforms the state-of-the-art in various FSOD settings by a large margin. The codes will be publicly available at https://github.com/zhu-xlab/ST-FSOD.
EarthNets: Empowering AI in Earth Observation
Oct 10, 2022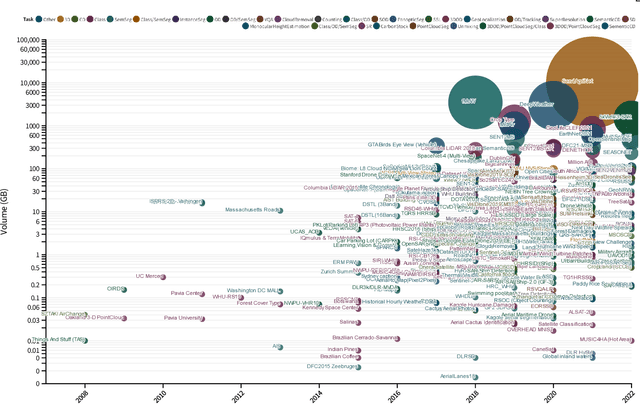
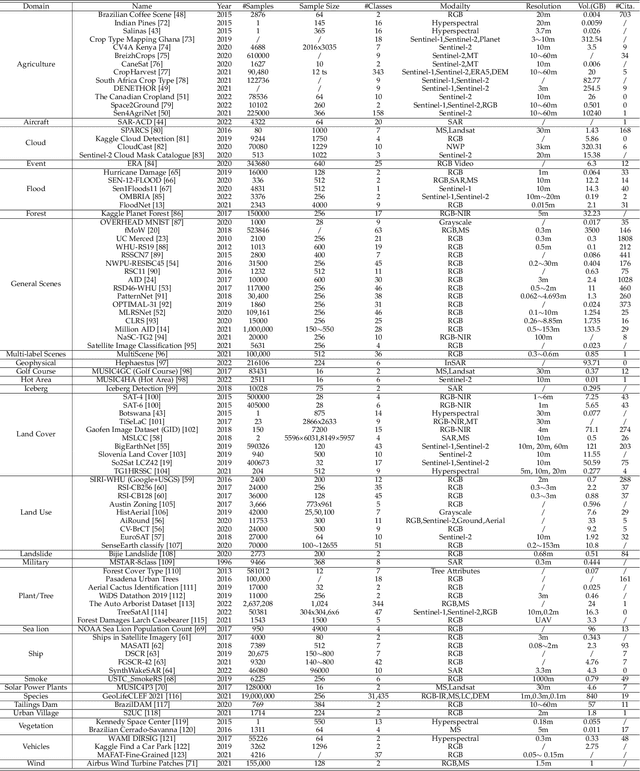
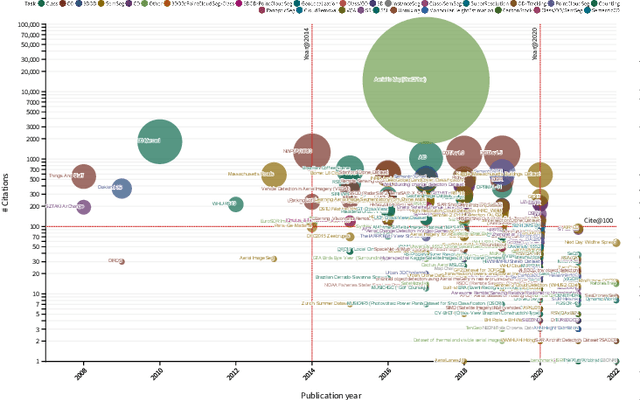
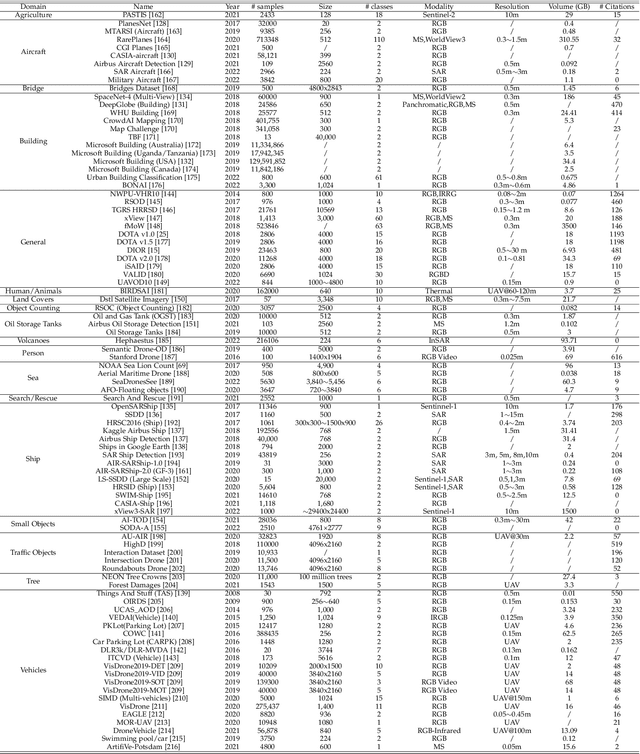
Earth observation, aiming at monitoring the state of planet Earth using remote sensing data, is critical for improving our daily lives and living environment. With an increasing number of satellites in orbit, more and more datasets with diverse sensors and research domains are published to facilitate the research of the remote sensing community. In this paper, for the first time, we present a comprehensive review of more than 400 publicly published datasets, including applications like, land use/cover, change/disaster monitoring, scene understanding, agriculture, climate change and weather forecasting. We systemically analyze these Earth observation datasets from five aspects, including the volume, bibliometric analysis, research domains and the correlation between datasets. Based on the dataset attributes, we propose to measure, rank and select datasets to build a new benchmark for model evaluation. Furthermore, a new platform for Earth observation, termed EarthNets, is released towards a fair and consistent evaluation of deep learning methods on remote sensing data. EarthNets supports standard dataset libraries and cutting-edge deep learning models to bridge the gap between remote sensing and the machine learning community. Based on the EarthNets platform, extensive deep learning methods are evaluated on the new benchmark. The insightful results are beneficial to future research. The platform, dataset collections are publicly available at https://earthnets.nicepage.io.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
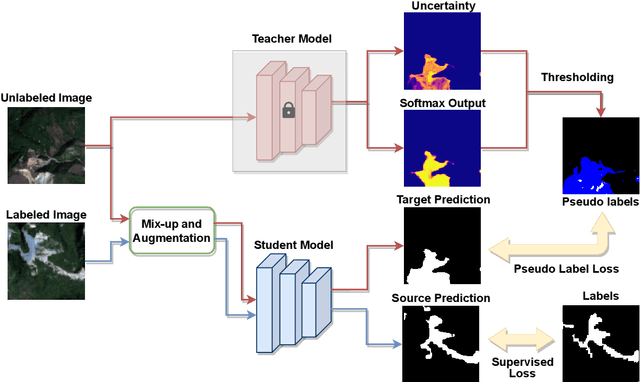
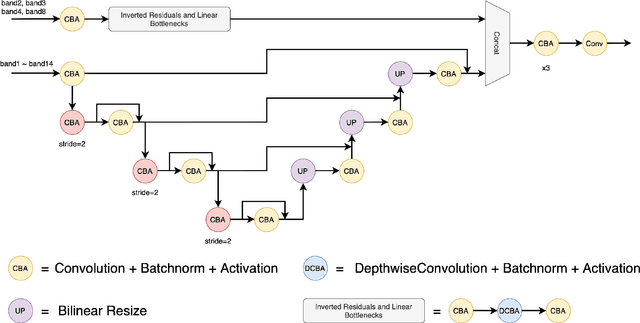
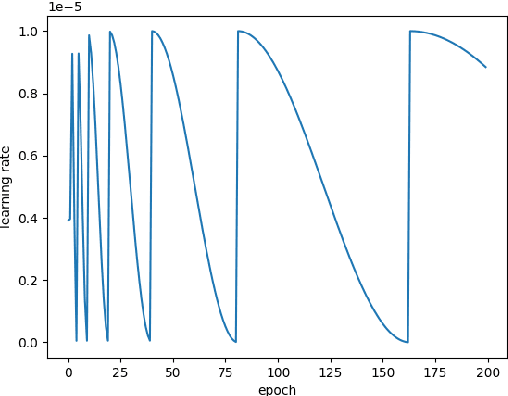
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
Optimal Clustering Framework for Hyperspectral Band Selection
Apr 30, 2019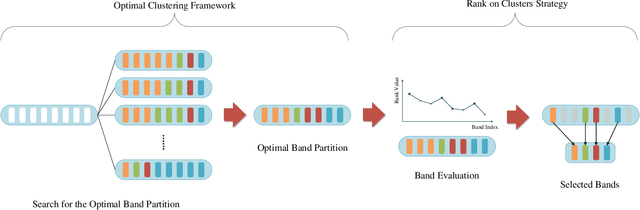
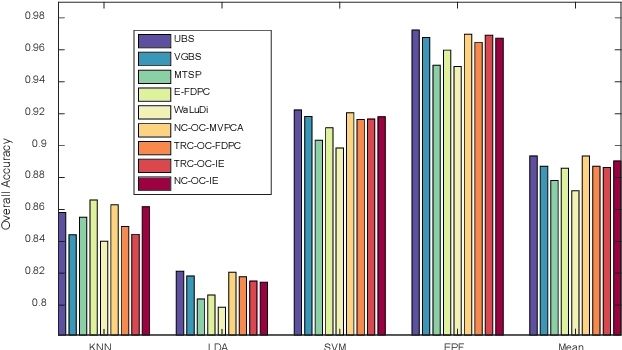
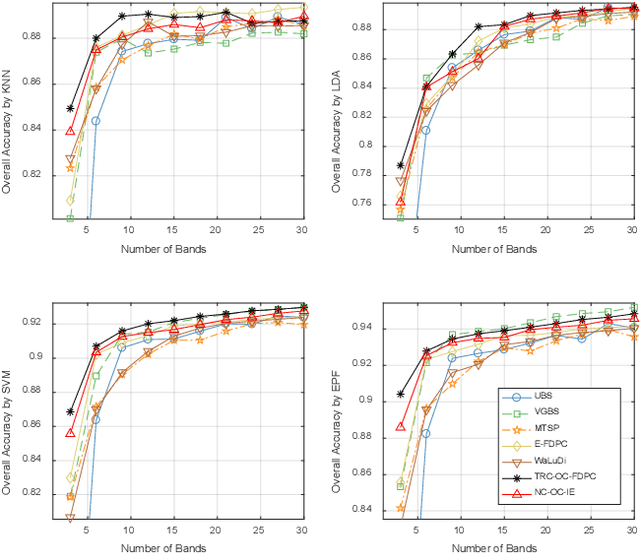
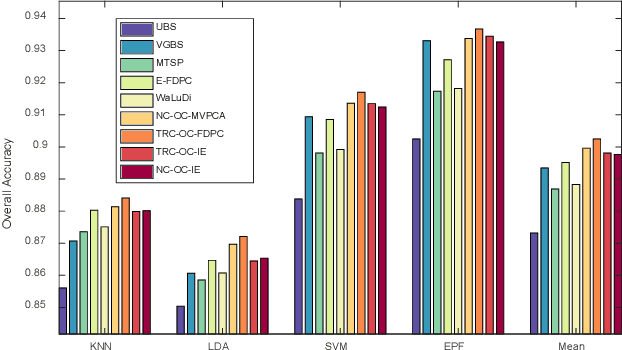
Band selection, by choosing a set of representative bands in hyperspectral image (HSI), is an effective method to reduce the redundant information without compromising the original contents. Recently, various unsupervised band selection methods have been proposed, but most of them are based on approximation algorithms which can only obtain suboptimal solutions toward a specific objective function. This paper focuses on clustering-based band selection, and proposes a new framework to solve the above dilemma, claiming the following contributions: 1) An optimal clustering framework (OCF), which can obtain the optimal clustering result for a particular form of objective function under a reasonable constraint. 2) A rank on clusters strategy (RCS), which provides an effective criterion to select bands on existing clustering structure. 3) An automatic method to determine the number of the required bands, which can better evaluate the distinctive information produced by certain number of bands. In experiments, the proposed algorithm is compared to some state-of-the-art competitors. According to the experimental results, the proposed algorithm is robust and significantly outperform the other methods on various data sets.