 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for All: Toward Unified Foundation Models for Earth Vision
Paper and Code
Jan 15, 2024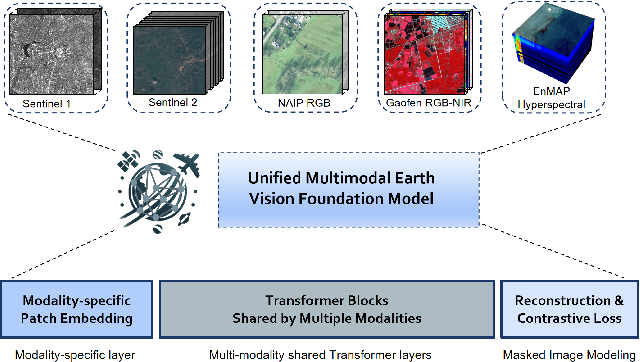

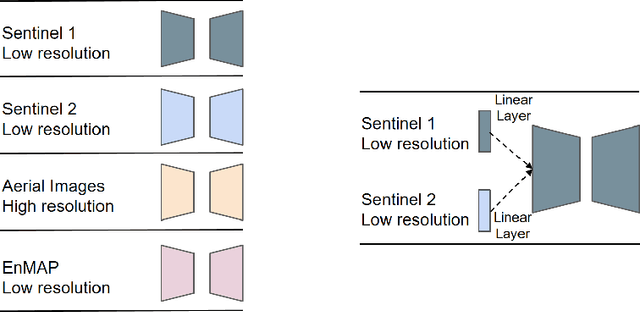

Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.