 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaMemento: Adaptive Memory-Assisted Policy Optimization for Reinforcement Learning
Oct 06, 2024



In sparse reward scenarios of reinforcement learning (RL), the memory mechanism provides promising shortcuts to policy optimization by reflecting on past experiences like humans. However, current memory-based RL methods simply store and reuse high-value policies, lacking a deeper refining and filtering of diverse past experiences and hence limiting the capability of memory. In this paper, we propose AdaMemento, an adaptive memory-enhanced RL framework. Instead of just memorizing positive past experiences, we design a memory-reflection module that exploits both positive and negative experiences by learning to predict known local optimal policies based on real-time states. To effectively gather informative trajectories for the memory, we further introduce a fine-grained intrinsic motivation paradigm, where nuances in similar states can be precisely distinguished to guide exploration. The exploitation of past experiences and exploration of new policies are then adaptively coordinated by ensemble learning to approach the global optimum. Furthermore, we theoretically prove the superiority of our new intrinsic motivation and ensemble mechanism. From 59 quantitative and visualization experiments, we confirm that AdaMemento can distinguish subtle states for better exploration and effectively exploiting past experiences in memory, achieving significant improvement over previous methods.
CopyLens: Dynamically Flagging Copyrighted Sub-Dataset Contributions to LLM Outputs
Oct 06, 2024



Large Language Models (LLMs) have become pervasive due to their knowledge absorption and text-generation capabilities. Concurrently, the copyright issue for pretraining datasets has been a pressing concern, particularly when generation includes specific styles. Previous methods either focus on the defense of identical copyrighted outputs or find interpretability by individual tokens with computational burdens. However, the gap between them exists, where direct assessments of how dataset contributions impact LLM outputs are missing. Once the model providers ensure copyright protection for data holders, a more mature LLM community can be established. To address these limitations, we introduce CopyLens, a new framework to analyze how copyrighted datasets may influence LLM responses. Specifically, a two-stage approach is employed: First, based on the uniqueness of pretraining data in the embedding space, token representations are initially fused for potential copyrighted texts, followed by a lightweight LSTM-based network to analyze dataset contributions. With such a prior, a contrastive-learning-based non-copyright OOD detector is designed. Our framework can dynamically face different situations and bridge the gap between current copyright detection methods. Experiments show that CopyLens improves efficiency and accuracy by 15.2% over our proposed baseline, 58.7% over prompt engineering methods, and 0.21 AUC over OOD detection baselines.
The Exploration-Exploitation Dilemma Revisited: An Entropy Perspective
Aug 19, 2024

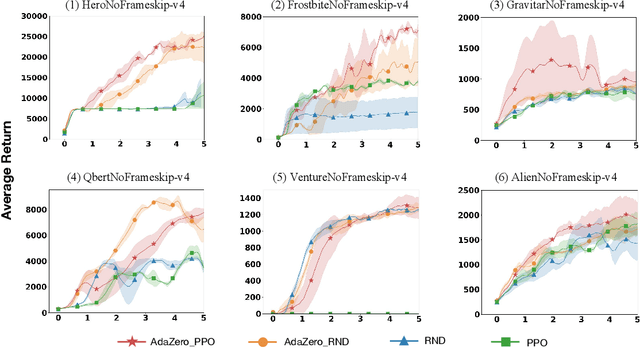
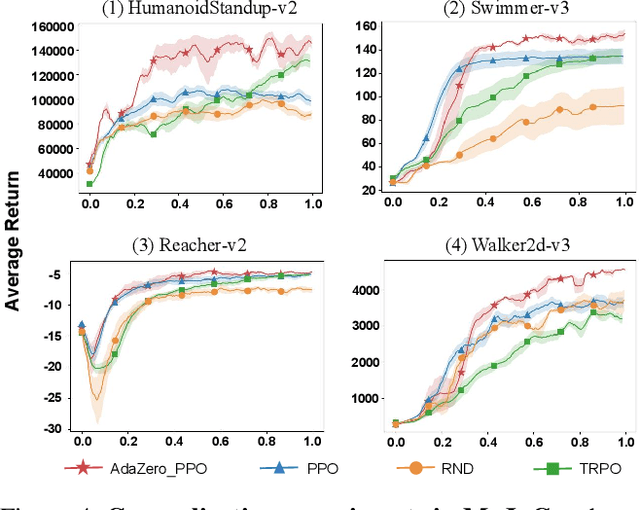
The imbalance of exploration and exploitation has long been a significant challenge in reinforcement learning. In policy optimization, excessive reliance on exploration reduces learning efficiency, while over-dependence on exploitation might trap agents in local optima. This paper revisits the exploration-exploitation dilemma from the perspective of entropy by revealing the relationship between entropy and the dynamic adaptive process of exploration and exploitation. Based on this theoretical insight, we establish an end-to-end adaptive framework called AdaZero, which automatically determines whether to explore or to exploit as well as their balance of strength. Experiments show that AdaZero significantly outperforms baseline models across various Atari and MuJoCo environments with only a single setting. Especially in the challenging environment of Montezuma, AdaZero boosts the final returns by up to fifteen times. Moreover, we conduct a series of visualization analyses to reveal the dynamics of our self-adaptive mechanism, demonstrating how entropy reflects and changes with respect to the agent's performance and adaptive process.
Transductive Off-policy Proximal Policy Optimization
Jun 06, 2024



Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
Reflective Policy Optimization
Jun 06, 2024



On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.