 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1.x-Distill: Breaking the Diversity, Quality, and Efficiency Barrier in Distribution Matching Distillation
Apr 05, 2026Diffusion models produce high-quality text-to-image results, but their iterative denoising is computationally expensive.Distribution Matching Distillation (DMD) emerges as a promising path to few-step distillation, but suffers from diversity collapse and fidelity degradation when reduced to two steps or fewer. We present 1.x-Distill, the first fractional-step distillation framework that breaks the integer-step constraint of prior few-step methods and establishes 1.x-step generation as a practical regime for distilled diffusion models.Specifically, we first analyze the overlooked role of teacher CFG in DMD and introduce a simple yet effective modification to suppress mode collapse. Then, to improve performance under extreme steps, we introduce Stagewise Focused Distillation, a two-stage strategy that learns coarse structure through diversity-preserving distribution matching and refines details with inference-consistent adversarial distillation. Furthermore, we design a lightweight compensation module for Distill--Cache co-Training, which naturally incorporates block-level caching into our distillation pipeline.Experiments on SD3-Medium and SD3.5-Large show that 1.x-Distill surpasses prior few-step methods, achieving better quality and diversity at 1.67 and 1.74 effective NFEs, respectively, with up to 33x speedup over original 28x2 NFE sampling.
Improving Search Suggestions for Alphanumeric Queries
Apr 01, 2026Alphanumeric identifiers such as manufacturer part numbers (MPNs), SKUs, and model codes are ubiquitous in e-commerce catalogs and search. These identifiers are sparse, non linguistic, and highly sensitive to tokenization and typographical variation, rendering conventional lexical and embedding based retrieval methods ineffective. We propose a training free, character level retrieval framework that encodes each alphanumeric sequence as a fixed length binary vector. This representation enables efficient similarity computation via Hamming distance and supports nearest neighbor retrieval over large identifier corpora. An optional re-ranking stage using edit distance refines precision while preserving latency guarantees. The method offers a practical and interpretable alternative to learned dense retrieval models, making it suitable for production deployment in search suggestion generation systems. Significant gains in business metrics in the A/B test further prove utility of our approach.
K^2-Agent: Co-Evolving Know-What and Know-How for Hierarchical Mobile Device Control
Feb 28, 2026Existing mobile device control agents often perform poorly when solving complex tasks requiring long-horizon planning and precise operations, typically due to a lack of relevant task experience or unfamiliarity with skill execution. We propose K2-Agent, a hierarchical framework that models human-like cognition by separating and co-evolving declarative (knowing what) and procedural (knowing how) knowledge for planning and execution. K2-Agent's high level reasoner is bootstrapped from a single demonstration per task and runs a Summarize-Reflect-Locate-Revise (SRLR) loop to distill and iteratively refine task-level declarative knowledge through self-evolution. The low-level executor is trained with our curriculum-guided Group Relative Policy Optimization (C-GRPO), which (i) constructs a balanced sample pool using decoupled reward signals and (ii) employs dynamic demonstration injection to guide the model in autonomously generating successful trajectories for training. On the challenging AndroidWorld benchmark, K2-Agent achieves a 76.1% success rate using only raw screenshots and open-source backbones. Furthermore, K2-Agent shows powerful dual generalization: its high-level declarative knowledge transfers across diverse base models, while its low-level procedural skills achieve competitive performance on unseen tasks in ScreenSpot-v2 and Android-in-the-Wild (AitW).
Boosting Instance Awareness via Cross-View Correlation with 4D Radar and Camera for 3D Object Detection
Feb 24, 20264D millimeter-wave radar has emerged as a promising sensing modality for autonomous driving due to its robustness and affordability. However, its sparse and weak geometric cues make reliable instance activation difficult, limiting the effectiveness of existing radar-camera fusion paradigms. BEV-level fusion offers global scene understanding but suffers from weak instance focus, while perspective-level fusion captures instance details but lacks holistic context. To address these limitations, we propose SIFormer, a scene-instance aware transformer for 3D object detection using 4D radar and camera. SIFormer first suppresses background noise during view transformation through segmentation- and depth-guided localization. It then introduces a cross-view activation mechanism that injects 2D instance cues into BEV space, enabling reliable instance awareness under weak radar geometry. Finally, a transformer-based fusion module aggregates complementary image semantics and radar geometry for robust perception. As a result, with the aim of enhancing instance awareness, SIFormer bridges the gap between the two paradigms, combining their complementary strengths to address inherent sparse nature of radar and improve detection accuracy. Experiments demonstrate that SIFormer achieves state-of-the-art performance on View-of-Delft, TJ4DRadSet and NuScenes datasets. Source code is available at github.com/shawnnnkb/SIFormer.
Towards Scalable Meta-Learning of near-optimal Interpretable Models via Synthetic Model Generations
Nov 06, 2025Decision trees are widely used in high-stakes fields like finance and healthcare due to their interpretability. This work introduces an efficient, scalable method for generating synthetic pre-training data to enable meta-learning of decision trees. Our approach samples near-optimal decision trees synthetically, creating large-scale, realistic datasets. Using the MetaTree transformer architecture, we demonstrate that this method achieves performance comparable to pre-training on real-world data or with computationally expensive optimal decision trees. This strategy significantly reduces computational costs, enhances data generation flexibility, and paves the way for scalable and efficient meta-learning of interpretable decision tree models.
Hi-Agent: Hierarchical Vision-Language Agents for Mobile Device Control
Oct 16, 2025Building agents that autonomously operate mobile devices has attracted increasing attention. While Vision-Language Models (VLMs) show promise, most existing approaches rely on direct state-to-action mappings, which lack structured reasoning and planning, and thus generalize poorly to novel tasks or unseen UI layouts. We introduce Hi-Agent, a trainable hierarchical vision-language agent for mobile control, featuring a high-level reasoning model and a low-level action model that are jointly optimized. For efficient training, we reformulate multi-step decision-making as a sequence of single-step subgoals and propose a foresight advantage function, which leverages execution feedback from the low-level model to guide high-level optimization. This design alleviates the path explosion issue encountered by Group Relative Policy Optimization (GRPO) in long-horizon tasks and enables stable, critic-free joint training. Hi-Agent achieves a new State-Of-The-Art (SOTA) 87.9% task success rate on the Android-in-the-Wild (AitW) benchmark, significantly outperforming prior methods across three paradigms: prompt-based (AppAgent: 17.7%), supervised (Filtered BC: 54.5%), and reinforcement learning-based (DigiRL: 71.9%). It also demonstrates competitive zero-shot generalization on the ScreenSpot-v2 benchmark. On the more challenging AndroidWorld benchmark, Hi-Agent also scales effectively with larger backbones, showing strong adaptability in high-complexity mobile control scenarios.
Recurrent Cross-View Object Geo-Localization
Sep 16, 2025Cross-view object geo-localization (CVOGL) aims to determine the location of a specific object in high-resolution satellite imagery given a query image with a point prompt. Existing approaches treat CVOGL as a one-shot detection task, directly regressing object locations from cross-view information aggregation, but they are vulnerable to feature noise and lack mechanisms for error correction. In this paper, we propose ReCOT, a Recurrent Cross-view Object geo-localization Transformer, which reformulates CVOGL as a recurrent localization task. ReCOT introduces a set of learnable tokens that encode task-specific intent from the query image and prompt embeddings, and iteratively attend to the reference features to refine the predicted location. To enhance this recurrent process, we incorporate two complementary modules: (1) a SAM-based knowledge distillation strategy that transfers segmentation priors from the Segment Anything Model (SAM) to provide clearer semantic guidance without additional inference cost, and (2) a Reference Feature Enhancement Module (RFEM) that introduces a hierarchical attention to emphasize object-relevant regions in the reference features. Extensive experiments on standard CVOGL benchmarks demonstrate that ReCOT achieves state-of-the-art (SOTA) performance while reducing parameters by 60% compared to previous SOTA approaches.
Bridging Modality Gaps in e-Commerce Products via Vision-Language Alignment
Aug 13, 2025Item information, such as titles and attributes, is essential for effective user engagement in e-commerce. However, manual or semi-manual entry of structured item specifics often produces inconsistent quality, errors, and slow turnaround, especially for Customer-to-Customer sellers. Generating accurate descriptions directly from item images offers a promising alternative. Existing retrieval-based solutions address some of these issues but often miss fine-grained visual details and struggle with niche or specialized categories. We propose Optimized Preference-Based AI for Listings (OPAL), a framework for generating schema-compliant, high-quality item descriptions from images using a fine-tuned multimodal large language model (MLLM). OPAL addresses key challenges in multimodal e-commerce applications, including bridging modality gaps and capturing detailed contextual information. It introduces two data refinement methods: MLLM-Assisted Conformity Enhancement, which ensures alignment with structured schema requirements, and LLM-Assisted Contextual Understanding, which improves the capture of nuanced and fine-grained information from visual inputs. OPAL uses visual instruction tuning combined with direct preference optimization to fine-tune the MLLM, reducing hallucinations and improving robustness across different backbone architectures. We evaluate OPAL on real-world e-commerce datasets, showing that it consistently outperforms baseline methods in both description quality and schema completion rates. These results demonstrate that OPAL effectively bridges the gap between visual and textual modalities, delivering richer, more accurate, and more consistent item descriptions. This work advances automated listing optimization and supports scalable, high-quality content generation in e-commerce platforms.
NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
May 02, 2025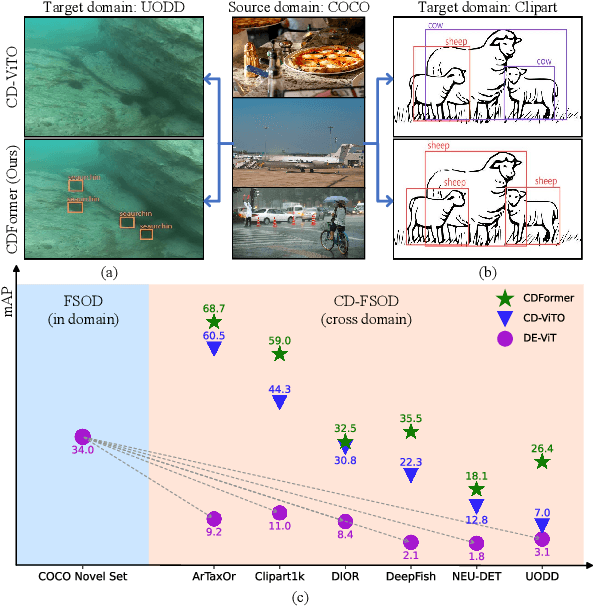
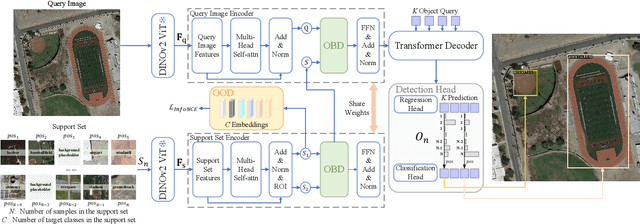

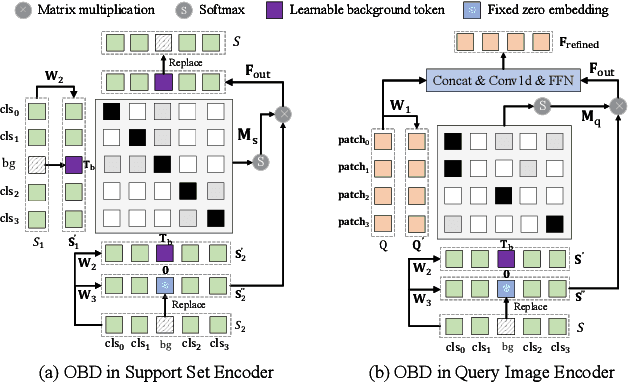
Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.