 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
LLM-assisted Graph-RAG Information Extraction from IFC Data
Apr 23, 2025



IFC data has become the general building information standard for collaborative work in the construction industry. However, IFC data can be very complicated because it allows for multiple ways to represent the same product information. In this research, we utilise the capabilities of LLMs to parse the IFC data with Graph Retrieval-Augmented Generation (Graph-RAG) technique to retrieve building object properties and their relations. We will show that, despite limitations due to the complex hierarchy of the IFC data, the Graph-RAG parsing enhances generative LLMs like GPT-4o with graph-based knowledge, enabling natural language query-response retrieval without the need for a complex pipeline.
Centrality-aware Product Retrieval and Ranking
Oct 21, 2024This paper addresses the challenge of improving user experience on e-commerce platforms by enhancing product ranking relevant to users' search queries. Ambiguity and complexity of user queries often lead to a mismatch between the user's intent and retrieved product titles or documents. Recent approaches have proposed the use of Transformer-based models, which need millions of annotated query-title pairs during the pre-training stage, and this data often does not take user intent into account. To tackle this, we curate samples from existing datasets at eBay, manually annotated with buyer-centric relevance scores and centrality scores, which reflect how well the product title matches the users' intent. We introduce a User-intent Centrality Optimization (UCO) approach for existing models, which optimises for the user intent in semantic product search. To that end, we propose a dual-loss based optimisation to handle hard negatives, i.e., product titles that are semantically relevant but do not reflect the user's intent. Our contributions include curating challenging evaluation sets and implementing UCO, resulting in significant product ranking efficiency improvements observed for different evaluation metrics. Our work aims to ensure that the most buyer-centric titles for a query are ranked higher, thereby, enhancing the user experience on e-commerce platforms.
Cyber Risks of Machine Translation Critical Errors : Arabic Mental Health Tweets as a Case Study
May 19, 2024


With the advent of Neural Machine Translation (NMT) systems, the MT output has reached unprecedented accuracy levels which resulted in the ubiquity of MT tools on almost all online platforms with multilingual content. However, NMT systems, like other state-of-the-art AI generative systems, are prone to errors that are deemed machine hallucinations. The problem with NMT hallucinations is that they are remarkably \textit{fluent} hallucinations. Since they are trained to produce grammatically correct utterances, NMT systems are capable of producing mistranslations that are too fluent to be recognised by both users of the MT tool, as well as by automatic quality metrics that are used to gauge their performance. In this paper, we introduce an authentic dataset of machine translation critical errors to point to the ethical and safety issues involved in the common use of MT. The dataset comprises mistranslations of Arabic mental health postings manually annotated with critical error types. We also show how the commonly used quality metrics do not penalise critical errors and highlight this as a critical issue that merits further attention from researchers.
Google Translate Error Analysis for Mental Healthcare Information: Evaluating Accuracy, Comprehensibility, and Implications for Multilingual Healthcare Communication
Feb 06, 2024This study explores the use of Google Translate (GT) for translating mental healthcare (MHealth) information and evaluates its accuracy, comprehensibility, and implications for multilingual healthcare communication through analysing GT output in the MHealth domain from English to Persian, Arabic, Turkish, Romanian, and Spanish. Two datasets comprising MHealth information from the UK National Health Service website and information leaflets from The Royal College of Psychiatrists were used. Native speakers of the target languages manually assessed the GT translations, focusing on medical terminology accuracy, comprehensibility, and critical syntactic/semantic errors. GT output analysis revealed challenges in accurately translating medical terminology, particularly in Arabic, Romanian, and Persian. Fluency issues were prevalent across various languages, affecting comprehension, mainly in Arabic and Spanish. Critical errors arose in specific contexts, such as bullet-point formatting, specifically in Persian, Turkish, and Romanian. Although improvements are seen in longer-text translations, there remains a need to enhance accuracy in medical and mental health terminology and fluency, whilst also addressing formatting issues for a more seamless user experience. The findings highlight the need to use customised translation engines for Mhealth translation and the challenges when relying solely on machine-translated medical content, emphasising the crucial role of human reviewers in multilingual healthcare communication.
Better Transcription of UK Supreme Court Hearings
Dec 22, 2022Transcription of legal proceedings is very important to enable access to justice. However, speech transcription is an expensive and slow process. In this paper we describe part of a combined research and industrial project for building an automated transcription tool designed specifically for the Justice sector in the UK. We explain the challenges involved in transcribing court room hearings and the Natural Language Processing (NLP) techniques we employ to tackle these challenges. We will show that fine-tuning a generic off-the-shelf pre-trained Automatic Speech Recognition (ASR) system with an in-domain language model as well as infusing common phrases extracted with a collocation detection model can improve not only the Word Error Rate (WER) of the transcribed hearings but avoid critical errors that are specific of the legal jargon and terminology commonly used in British courts.
PLOD: An Abbreviation Detection Dataset for Scientific Documents
Apr 28, 2022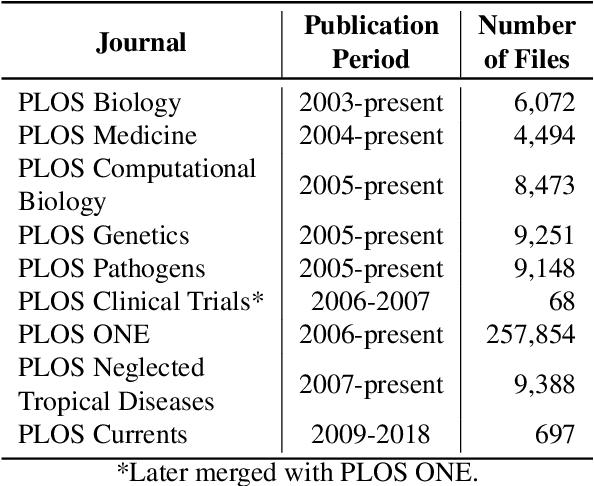
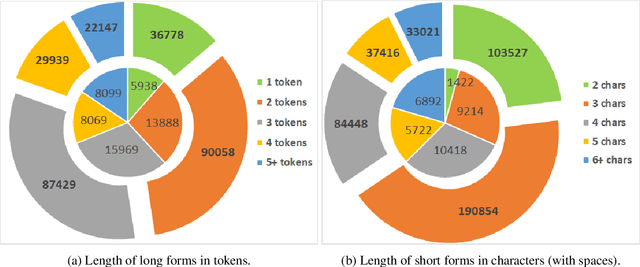
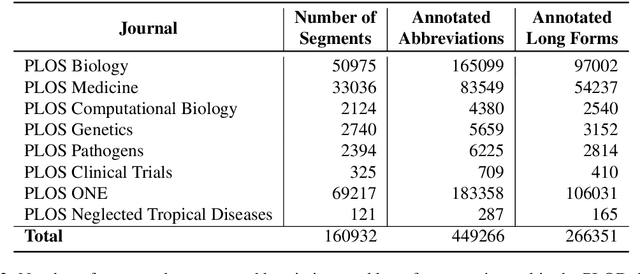
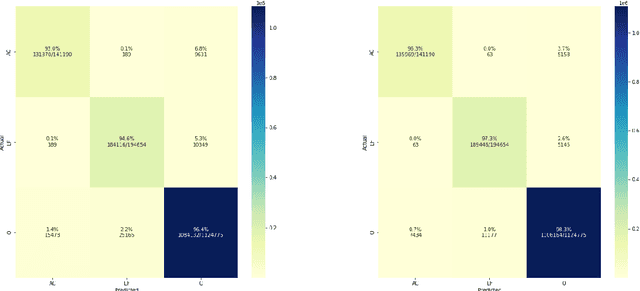
The detection and extraction of abbreviations from unstructured texts can help to improve the performance of Natural Language Processing tasks, such as machine translation and information retrieval. However, in terms of publicly available datasets, there is not enough data for training deep-neural-networks-based models to the point of generalising well over data. This paper presents PLOD, a large-scale dataset for abbreviation detection and extraction that contains 160k+ segments automatically annotated with abbreviations and their long forms. We performed manual validation over a set of instances and a complete automatic validation for this dataset. We then used it to generate several baseline models for detecting abbreviations and long forms. The best models achieved an F1-score of 0.92 for abbreviations and 0.89 for detecting their corresponding long forms. We release this dataset along with our code and all the models publicly in https://github.com/surrey-nlp/PLOD-AbbreviationDetection
An Ensemble Approach to Acronym Extraction using Transformers
Jan 09, 2022
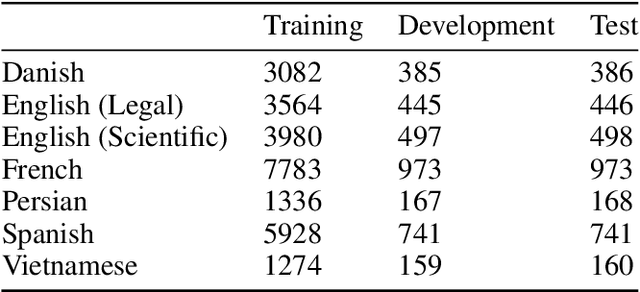
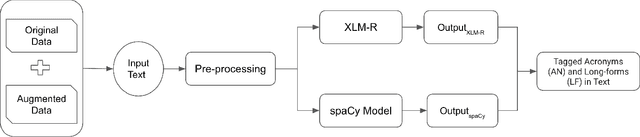
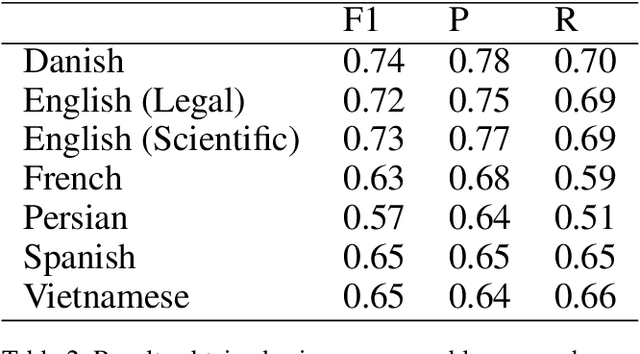
Acronyms are abbreviated units of a phrase constructed by using initial components of the phrase in a text. Automatic extraction of acronyms from a text can help various Natural Language Processing tasks like machine translation, information retrieval, and text summarisation. This paper discusses an ensemble approach for the task of Acronym Extraction, which utilises two different methods to extract acronyms and their corresponding long forms. The first method utilises a multilingual contextual language model and fine-tunes the model to perform the task. The second method relies on a convolutional neural network architecture to extract acronyms and append them to the output of the previous method. We also augment the official training dataset with additional training samples extracted from several open-access journals to help improve the task performance. Our dataset analysis also highlights the noise within the current task dataset. Our approach achieves the following macro-F1 scores on test data released with the task: Danish (0.74), English-Legal (0.72), English-Scientific (0.73), French (0.63), Persian (0.57), Spanish (0.65), Vietnamese (0.65). We release our code and models publicly.
Sentiment-Aware Measure (SAM) for Evaluating Sentiment Transfer by Machine Translation Systems
Oct 05, 2021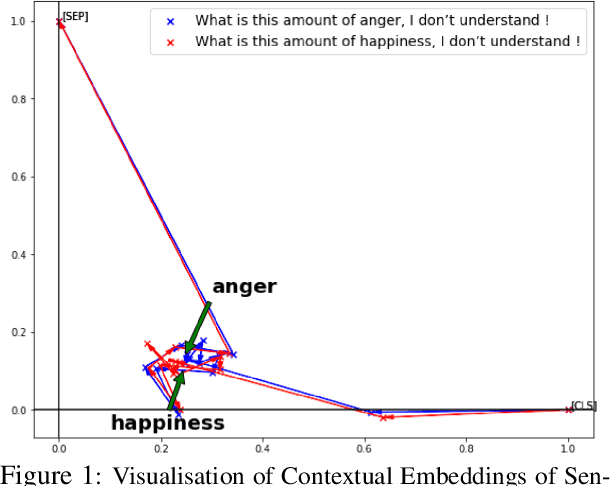

In translating text where sentiment is the main message, human translators give particular attention to sentiment-carrying words. The reason is that an incorrect translation of such words would miss the fundamental aspect of the source text, i.e. the author's sentiment. In the online world, MT systems are extensively used to translate User-Generated Content (UGC) such as reviews, tweets, and social media posts, where the main message is often the author's positive or negative attitude towards the topic of the text. It is important in such scenarios to accurately measure how far an MT system can be a reliable real-life utility in transferring the correct affect message. This paper tackles an under-recognised problem in the field of machine translation evaluation which is judging to what extent automatic metrics concur with the gold standard of human evaluation for a correct translation of sentiment. We evaluate the efficacy of conventional quality metrics in spotting a mistranslation of sentiment, especially when it is the sole error in the MT output. We propose a numerical `sentiment-closeness' measure appropriate for assessing the accuracy of a translated affect message in UGC text by an MT system. We will show that incorporating this sentiment-aware measure can significantly enhance the correlation of some available quality metrics with the human judgement of an accurate translation of sentiment.
* Accepted for RANLP (Recent Advances in Natural Language Processing) 2021
BLEU, METEOR, BERTScore: Evaluation of Metrics Performance in Assessing Critical Translation Errors in Sentiment-oriented Text
Sep 29, 2021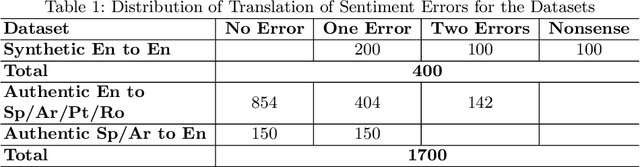
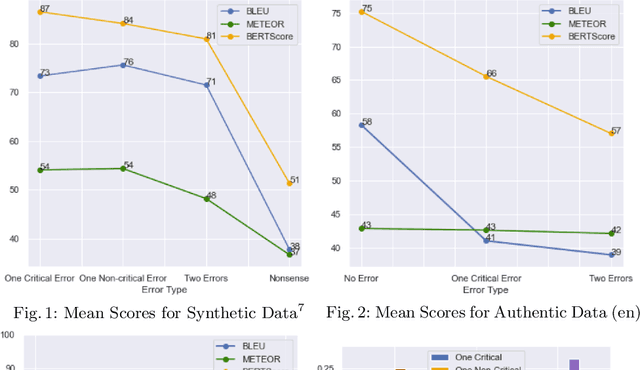
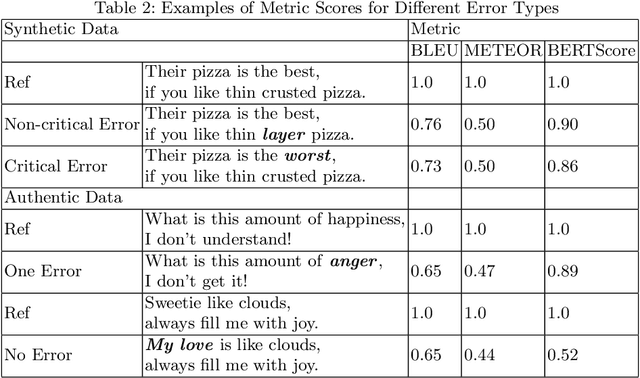

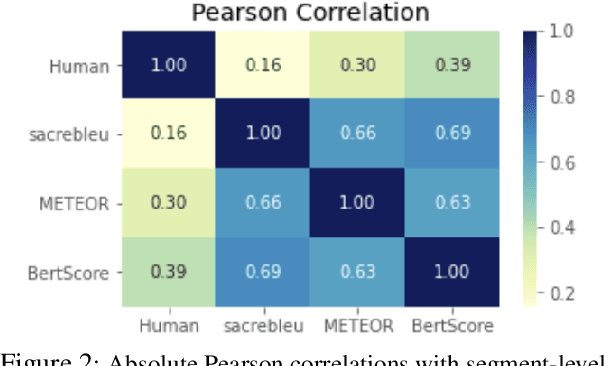
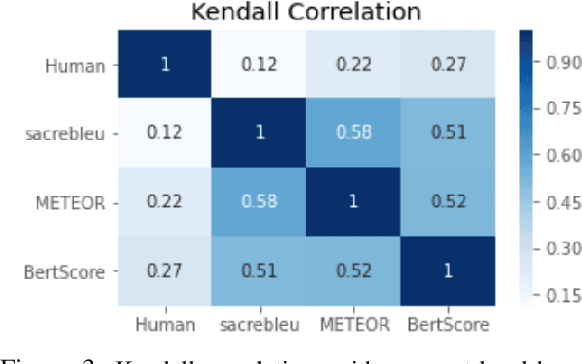
Social media companies as well as authorities make extensive use of artificial intelligence (AI) tools to monitor postings of hate speech, celebrations of violence or profanity. Since AI software requires massive volumes of data to train computers, Machine Translation (MT) of the online content is commonly used to process posts written in several languages and hence augment the data needed for training. However, MT mistakes are a regular occurrence when translating sentiment-oriented user-generated content (UGC), especially when a low-resource language is involved. The adequacy of the whole process relies on the assumption that the evaluation metrics used give a reliable indication of the quality of the translation. In this paper, we assess the ability of automatic quality metrics to detect critical machine translation errors which can cause serious misunderstanding of the affect message. We compare the performance of three canonical metrics on meaningless translations where the semantic content is seriously impaired as compared to meaningful translations with a critical error which exclusively distorts the sentiment of the source text. We conclude that there is a need for fine-tuning of automatic metrics to make them more robust in detecting sentiment critical errors.
* Accepted for TRITON (TRanslation and Interpreting Technology ONline) 2021