 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Linguistic Generalisation in Language Models: A Dataset for Brazilian Portuguese
May 23, 2023Much recent effort has been devoted to creating large-scale language models. Nowadays, the most prominent approaches are based on deep neural networks, such as BERT. However, they lack transparency and interpretability, and are often seen as black boxes. This affects not only their applicability in downstream tasks but also the comparability of different architectures or even of the same model trained using different corpora or hyperparameters. In this paper, we propose a set of intrinsic evaluation tasks that inspect the linguistic information encoded in models developed for Brazilian Portuguese. These tasks are designed to evaluate how different language models generalise information related to grammatical structures and multiword expressions (MWEs), thus allowing for an assessment of whether the model has learned different linguistic phenomena. The dataset that was developed for these tasks is composed of a series of sentences with a single masked word and a cue phrase that helps in narrowing down the context. This dataset is divided into MWEs and grammatical structures, and the latter is subdivided into 6 tasks: impersonal verbs, subject agreement, verb agreement, nominal agreement, passive and connectors. The subset for MWEs was used to test BERTimbau Large, BERTimbau Base and mBERT. For the grammatical structures, we used only BERTimbau Large, because it yielded the best results in the MWE task.
PLOD: An Abbreviation Detection Dataset for Scientific Documents
Apr 28, 2022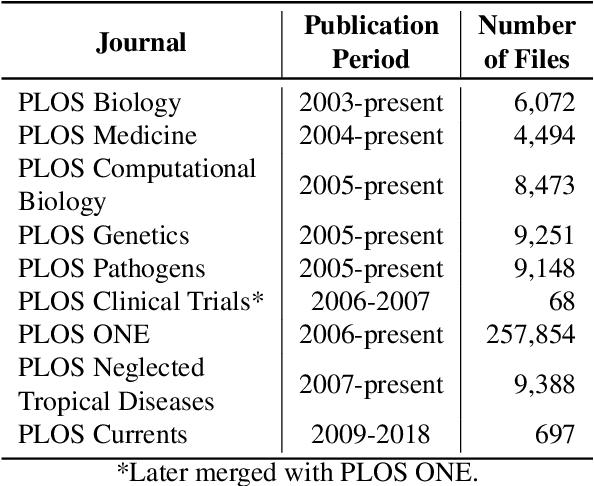
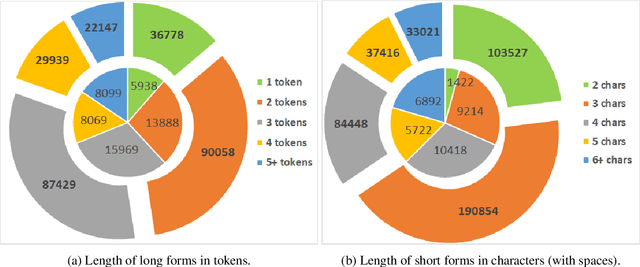
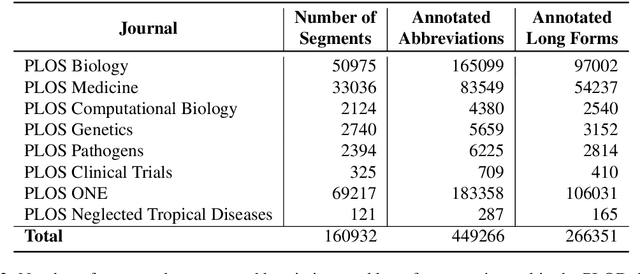
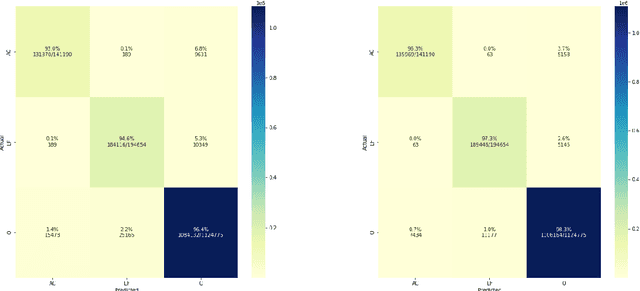
The detection and extraction of abbreviations from unstructured texts can help to improve the performance of Natural Language Processing tasks, such as machine translation and information retrieval. However, in terms of publicly available datasets, there is not enough data for training deep-neural-networks-based models to the point of generalising well over data. This paper presents PLOD, a large-scale dataset for abbreviation detection and extraction that contains 160k+ segments automatically annotated with abbreviations and their long forms. We performed manual validation over a set of instances and a complete automatic validation for this dataset. We then used it to generate several baseline models for detecting abbreviations and long forms. The best models achieved an F1-score of 0.92 for abbreviations and 0.89 for detecting their corresponding long forms. We release this dataset along with our code and all the models publicly in https://github.com/surrey-nlp/PLOD-AbbreviationDetection
An Ensemble Approach to Acronym Extraction using Transformers
Jan 09, 2022
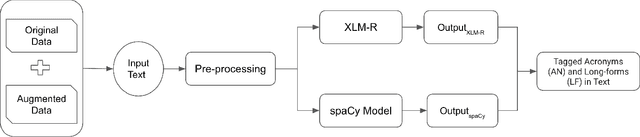
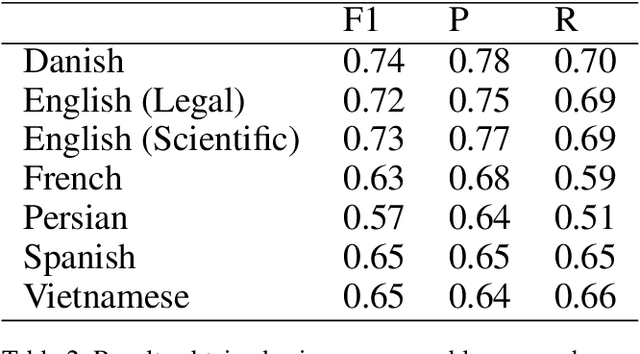
Acronyms are abbreviated units of a phrase constructed by using initial components of the phrase in a text. Automatic extraction of acronyms from a text can help various Natural Language Processing tasks like machine translation, information retrieval, and text summarisation. This paper discusses an ensemble approach for the task of Acronym Extraction, which utilises two different methods to extract acronyms and their corresponding long forms. The first method utilises a multilingual contextual language model and fine-tunes the model to perform the task. The second method relies on a convolutional neural network architecture to extract acronyms and append them to the output of the previous method. We also augment the official training dataset with additional training samples extracted from several open-access journals to help improve the task performance. Our dataset analysis also highlights the noise within the current task dataset. Our approach achieves the following macro-F1 scores on test data released with the task: Danish (0.74), English-Legal (0.72), English-Scientific (0.73), French (0.63), Persian (0.57), Spanish (0.65), Vietnamese (0.65). We release our code and models publicly.
Challenges in Translation of Emotions in Multilingual User-Generated Content: Twitter as a Case Study
Jun 20, 2021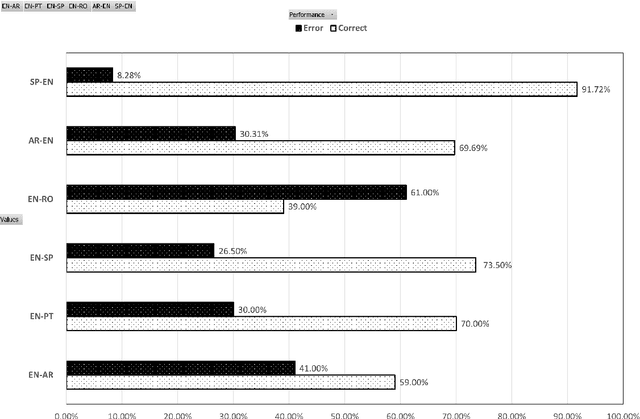

Although emotions are universal concepts, transferring the different shades of emotion from one language to another may not always be straightforward for human translators, let alone for machine translation systems. Moreover, the cognitive states are established by verbal explanations of experience which is shaped by both the verbal and cultural contexts. There are a number of verbal contexts where expression of emotions constitutes the pivotal component of the message. This is particularly true for User-Generated Content (UGC) which can be in the form of a review of a product or a service, a tweet, or a social media post. Recently, it has become common practice for multilingual websites such as Twitter to provide an automatic translation of UGC to reach out to their linguistically diverse users. In such scenarios, the process of translating the user's emotion is entirely automatic with no human intervention, neither for post-editing nor for accuracy checking. In this research, we assess whether automatic translation tools can be a successful real-life utility in transferring emotion in user-generated multilingual data such as tweets. We show that there are linguistic phenomena specific of Twitter data that pose a challenge in translation of emotions in different languages. We summarise these challenges in a list of linguistic features and show how frequent these features are in different language pairs. We also assess the capacity of commonly used methods for evaluating the performance of an MT system with respect to the preservation of emotion in the source text.