 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Chinese-English Machine Translation of Emotion-Loaded Microblog Texts: A Human Annotated Dataset for the Quality Assessment of Emotion Translation
Jun 20, 2023In this paper, we focus on how current Machine Translation (MT) tools perform on the translation of emotion-loaded texts by evaluating outputs from Google Translate according to a framework proposed in this paper. We propose this evaluation framework based on the Multidimensional Quality Metrics (MQM) and perform a detailed error analysis of the MT outputs. From our analysis, we observe that about 50% of the MT outputs fail to preserve the original emotion. After further analysis of the errors, we find that emotion carrying words and linguistic phenomena such as polysemous words, negation, abbreviation etc., are common causes for these translation errors.
Challenges in Translation of Emotions in Multilingual User-Generated Content: Twitter as a Case Study
Jun 20, 2021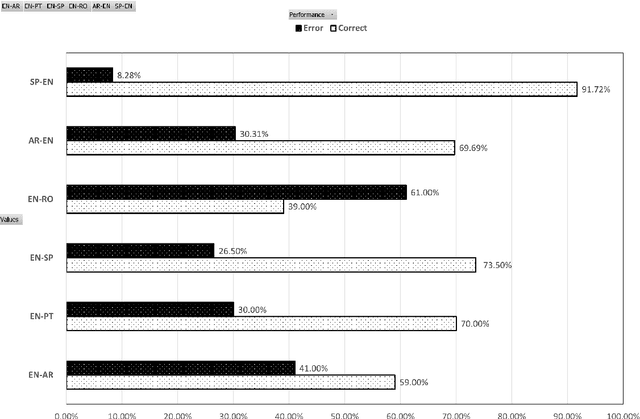

Although emotions are universal concepts, transferring the different shades of emotion from one language to another may not always be straightforward for human translators, let alone for machine translation systems. Moreover, the cognitive states are established by verbal explanations of experience which is shaped by both the verbal and cultural contexts. There are a number of verbal contexts where expression of emotions constitutes the pivotal component of the message. This is particularly true for User-Generated Content (UGC) which can be in the form of a review of a product or a service, a tweet, or a social media post. Recently, it has become common practice for multilingual websites such as Twitter to provide an automatic translation of UGC to reach out to their linguistically diverse users. In such scenarios, the process of translating the user's emotion is entirely automatic with no human intervention, neither for post-editing nor for accuracy checking. In this research, we assess whether automatic translation tools can be a successful real-life utility in transferring emotion in user-generated multilingual data such as tweets. We show that there are linguistic phenomena specific of Twitter data that pose a challenge in translation of emotions in different languages. We summarise these challenges in a list of linguistic features and show how frequent these features are in different language pairs. We also assess the capacity of commonly used methods for evaluating the performance of an MT system with respect to the preservation of emotion in the source text.