 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOPE: Adaptive Layer Optimization for Translation Quality Estimation using Large Language Models
Aug 10, 2025
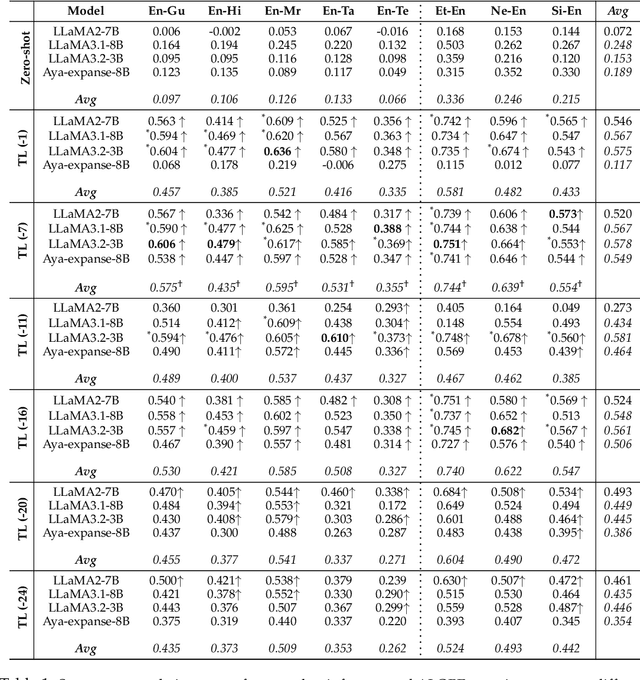
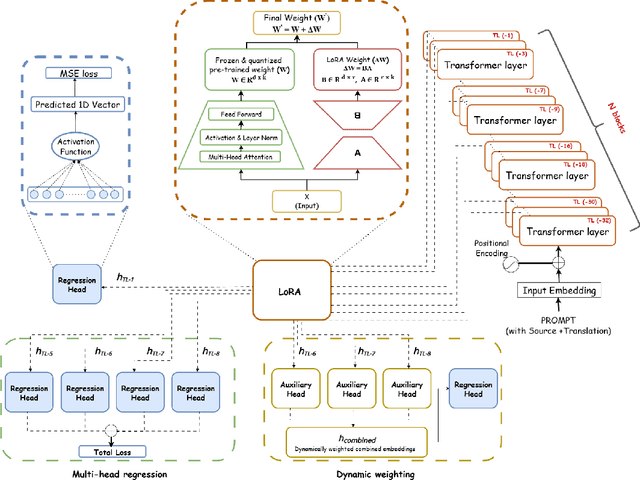
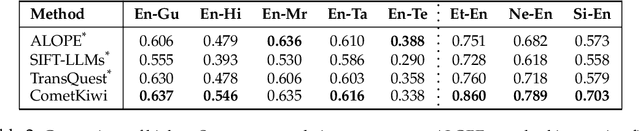
Large Language Models (LLMs) have shown remarkable performance across a wide range of natural language processing tasks. Quality Estimation (QE) for Machine Translation (MT), which assesses the quality of a source-target pair without relying on reference translations, remains a challenging cross-lingual task for LLMs. The challenges stem from the inherent limitations of existing LLM-based QE systems, which are pre-trained for causal language modelling rather than regression-specific tasks, further elevated by the presence of low-resource languages given pre-training data distribution. This paper introduces ALOPE, an adaptive layer-optimization framework designed to enhance LLM-based QE by restructuring Transformer representations through layer-wise adaptation for improved regression-based prediction. Our framework integrates low-rank adapters (LoRA) with regression task heads, leveraging selected pre-trained Transformer layers for improved cross-lingual alignment. In addition to the layer-specific adaptation, ALOPE introduces two strategies-dynamic weighting, which adaptively combines representations from multiple layers, and multi-head regression, which aggregates regression losses from multiple heads for QE. Our framework shows improvements over various existing LLM-based QE approaches. Empirical evidence suggests that intermediate Transformer layers in LLMs provide contextual representations that are more aligned with the cross-lingual nature of the QE task. We make resultant models and framework code publicly available for further research, also allowing existing LLM-based MT frameworks to be scaled with QE capabilities.
NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
Automatically Generating Chinese Homophone Words to Probe Machine Translation Estimation Systems
Mar 20, 2025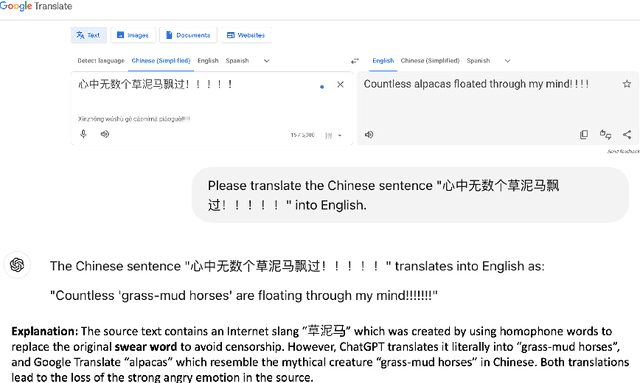

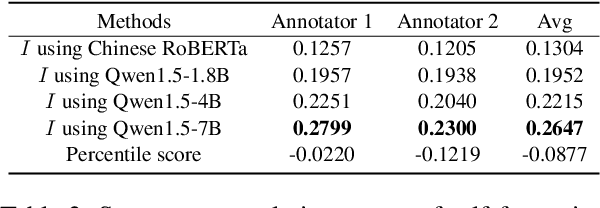
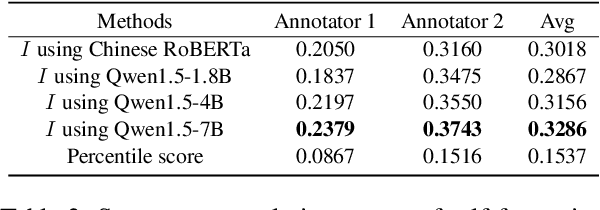
Evaluating machine translation (MT) of user-generated content (UGC) involves unique challenges such as checking whether the nuance of emotions from the source are preserved in the target text. Recent studies have proposed emotion-related datasets, frameworks and models to automatically evaluate MT quality of Chinese UGC, without relying on reference translations. However, whether these models are robust to the challenge of preserving emotional nuances has been left largely unexplored. To address this gap, we introduce a novel method inspired by information theory which generates challenging Chinese homophone words related to emotions, by leveraging the concept of self-information. Our approach generates homophones that were observed to cause translation errors in emotion preservation, and exposes vulnerabilities in MT systems and their evaluation methods when tackling emotional UGC. We evaluate the efficacy of our method using human evaluation for the quality of these generated homophones, and compare it with an existing one, showing that our method achieves higher correlation with human judgments. The generated Chinese homophones, along with their manual translations, are utilized to generate perturbations and to probe the robustness of existing quality evaluation models, including models trained using multi-task learning, fine-tuned variants of multilingual language models, as well as large language models (LLMs). Our results indicate that LLMs with larger size exhibit higher stability and robustness to such perturbations. We release our data and code for reproducibility and further research.
When LLMs Struggle: Reference-less Translation Evaluation for Low-resource Languages
Jan 08, 2025



This paper investigates the reference-less evaluation of machine translation for low-resource language pairs, known as quality estimation (QE). Segment-level QE is a challenging cross-lingual language understanding task that provides a quality score (0-100) to the translated output. We comprehensively evaluate large language models (LLMs) in zero/few-shot scenarios and perform instruction fine-tuning using a novel prompt based on annotation guidelines. Our results indicate that prompt-based approaches are outperformed by the encoder-based fine-tuned QE models. Our error analysis reveals tokenization issues, along with errors due to transliteration and named entities, and argues for refinement in LLM pre-training for cross-lingual tasks. We release the data, and models trained publicly for further research.
Are Large Language Models State-of-the-art Quality Estimators for Machine Translation of User-generated Content?
Oct 08, 2024This paper investigates whether large language models (LLMs) are state-of-the-art quality estimators for machine translation of user-generated content (UGC) that contains emotional expressions, without the use of reference translations. To achieve this, we employ an existing emotion-related dataset with human-annotated errors and calculate quality evaluation scores based on the Multi-dimensional Quality Metrics. We compare the accuracy of several LLMs with that of our fine-tuned baseline models, under in-context learning and parameter-efficient fine-tuning (PEFT) scenarios. We find that PEFT of LLMs leads to better performance in score prediction with human interpretable explanations than fine-tuned models. However, a manual analysis of LLM outputs reveals that they still have problems such as refusal to reply to a prompt and unstable output while evaluating machine translation of UGC.
What do Large Language Models Need for Machine Translation Evaluation?
Oct 04, 2024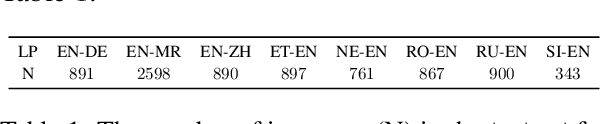
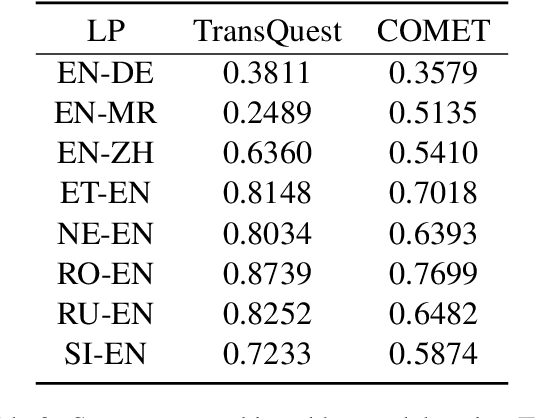
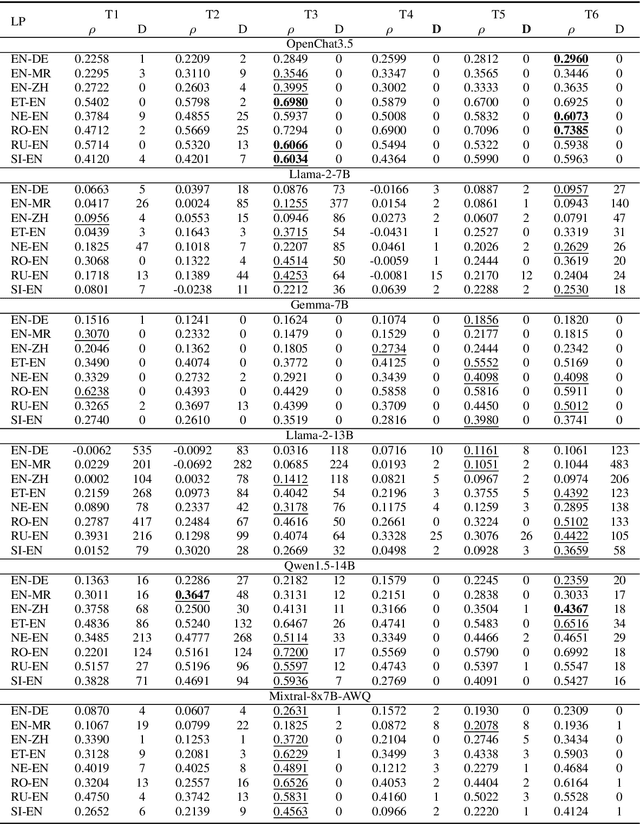
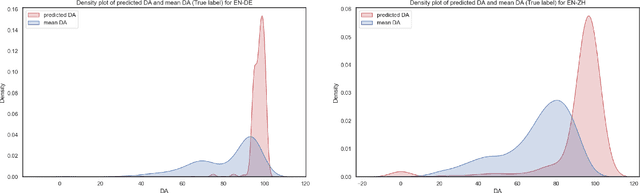
Leveraging large language models (LLMs) for various natural language processing tasks has led to superlative claims about their performance. For the evaluation of machine translation (MT), existing research shows that LLMs are able to achieve results comparable to fine-tuned multilingual pre-trained language models. In this paper, we explore what translation information, such as the source, reference, translation errors and annotation guidelines, is needed for LLMs to evaluate MT quality. In addition, we investigate prompting techniques such as zero-shot, Chain of Thought (CoT) and few-shot prompting for eight language pairs covering high-, medium- and low-resource languages, leveraging varying LLM variants. Our findings indicate the importance of reference translations for an LLM-based evaluation. While larger models do not necessarily fare better, they tend to benefit more from CoT prompting, than smaller models. We also observe that LLMs do not always provide a numerical score when generating evaluations, which poses a question on their reliability for the task. Our work presents a comprehensive analysis for resource-constrained and training-less LLM-based evaluation of machine translation. We release the accrued prompt templates, code and data publicly for reproducibility.
Evaluation of Chinese-English Machine Translation of Emotion-Loaded Microblog Texts: A Human Annotated Dataset for the Quality Assessment of Emotion Translation
Jun 20, 2023In this paper, we focus on how current Machine Translation (MT) tools perform on the translation of emotion-loaded texts by evaluating outputs from Google Translate according to a framework proposed in this paper. We propose this evaluation framework based on the Multidimensional Quality Metrics (MQM) and perform a detailed error analysis of the MT outputs. From our analysis, we observe that about 50% of the MT outputs fail to preserve the original emotion. After further analysis of the errors, we find that emotion carrying words and linguistic phenomena such as polysemous words, negation, abbreviation etc., are common causes for these translation errors.