 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOPE: Adaptive Layer Optimization for Translation Quality Estimation using Large Language Models
Aug 10, 2025
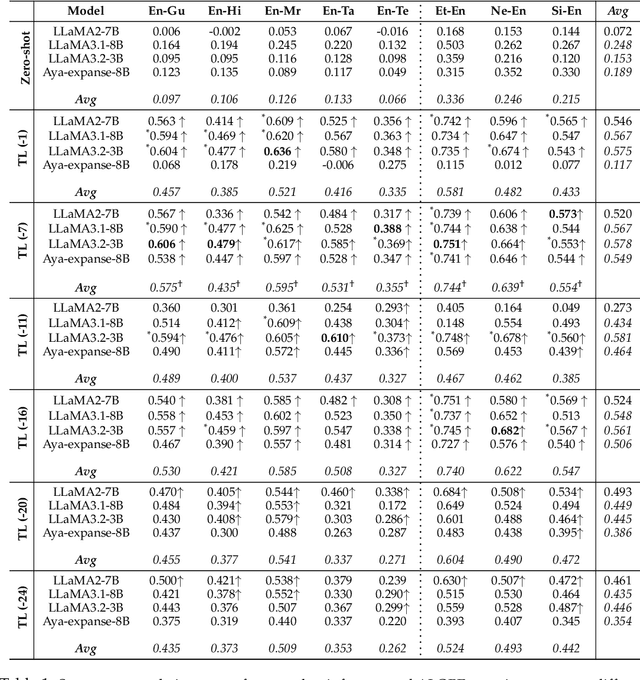
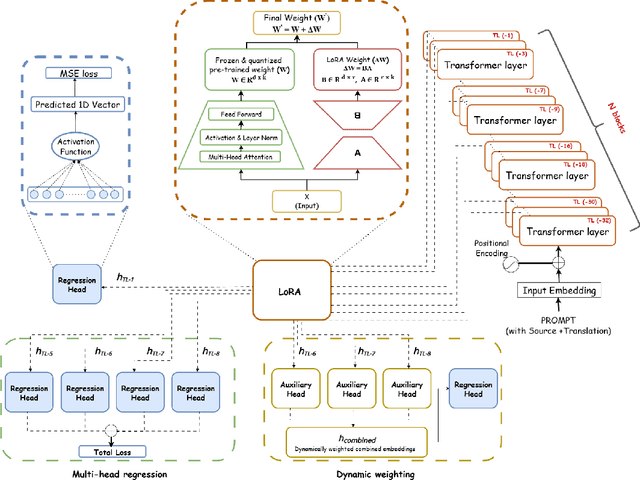
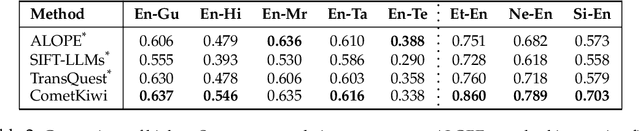
Large Language Models (LLMs) have shown remarkable performance across a wide range of natural language processing tasks. Quality Estimation (QE) for Machine Translation (MT), which assesses the quality of a source-target pair without relying on reference translations, remains a challenging cross-lingual task for LLMs. The challenges stem from the inherent limitations of existing LLM-based QE systems, which are pre-trained for causal language modelling rather than regression-specific tasks, further elevated by the presence of low-resource languages given pre-training data distribution. This paper introduces ALOPE, an adaptive layer-optimization framework designed to enhance LLM-based QE by restructuring Transformer representations through layer-wise adaptation for improved regression-based prediction. Our framework integrates low-rank adapters (LoRA) with regression task heads, leveraging selected pre-trained Transformer layers for improved cross-lingual alignment. In addition to the layer-specific adaptation, ALOPE introduces two strategies-dynamic weighting, which adaptively combines representations from multiple layers, and multi-head regression, which aggregates regression losses from multiple heads for QE. Our framework shows improvements over various existing LLM-based QE approaches. Empirical evidence suggests that intermediate Transformer layers in LLMs provide contextual representations that are more aligned with the cross-lingual nature of the QE task. We make resultant models and framework code publicly available for further research, also allowing existing LLM-based MT frameworks to be scaled with QE capabilities.
NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
When LLMs Struggle: Reference-less Translation Evaluation for Low-resource Languages
Jan 08, 2025



This paper investigates the reference-less evaluation of machine translation for low-resource language pairs, known as quality estimation (QE). Segment-level QE is a challenging cross-lingual language understanding task that provides a quality score (0-100) to the translated output. We comprehensively evaluate large language models (LLMs) in zero/few-shot scenarios and perform instruction fine-tuning using a novel prompt based on annotation guidelines. Our results indicate that prompt-based approaches are outperformed by the encoder-based fine-tuned QE models. Our error analysis reveals tokenization issues, along with errors due to transliteration and named entities, and argues for refinement in LLM pre-training for cross-lingual tasks. We release the data, and models trained publicly for further research.
Benchmarking terminology building capabilities of ChatGPT on an English-Russian Fashion Corpus
Dec 04, 2024
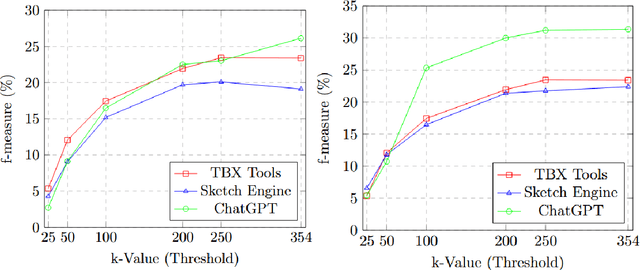
This paper compares the accuracy of the terms extracted using SketchEngine, TBXTools and ChatGPT. In addition, it evaluates the quality of the definitions produced by ChatGPT for these terms. The research is carried out on a comparable corpus of fashion magazines written in English and Russian collected from the web. A gold standard for the fashion terminology was also developed by identifying web pages that can be harvested automatically and contain definitions of terms from the fashion domain in English and Russian. This gold standard was used to evaluate the quality of the extracted terms and of the definitions produced. Our evaluation shows that TBXTools and SketchEngine, while capable of high recall, suffer from reduced precision as the number of terms increases, which affects their overall performance. Conversely, ChatGPT demonstrates superior performance, maintaining or improving precision as more terms are considered. Analysis of the definitions produced by ChatGPT for 60 commonly used terms in English and Russian shows that ChatGPT maintains a reasonable level of accuracy and fidelity across languages, but sometimes the definitions in both languages miss crucial specifics and include unnecessary deviations. Our research reveals that no single tool excels universally; each has strengths suited to particular aspects of terminology extraction and application.
Centrality-aware Product Retrieval and Ranking
Oct 21, 2024This paper addresses the challenge of improving user experience on e-commerce platforms by enhancing product ranking relevant to users' search queries. Ambiguity and complexity of user queries often lead to a mismatch between the user's intent and retrieved product titles or documents. Recent approaches have proposed the use of Transformer-based models, which need millions of annotated query-title pairs during the pre-training stage, and this data often does not take user intent into account. To tackle this, we curate samples from existing datasets at eBay, manually annotated with buyer-centric relevance scores and centrality scores, which reflect how well the product title matches the users' intent. We introduce a User-intent Centrality Optimization (UCO) approach for existing models, which optimises for the user intent in semantic product search. To that end, we propose a dual-loss based optimisation to handle hard negatives, i.e., product titles that are semantically relevant but do not reflect the user's intent. Our contributions include curating challenging evaluation sets and implementing UCO, resulting in significant product ranking efficiency improvements observed for different evaluation metrics. Our work aims to ensure that the most buyer-centric titles for a query are ranked higher, thereby, enhancing the user experience on e-commerce platforms.
Cyber Risks of Machine Translation Critical Errors : Arabic Mental Health Tweets as a Case Study
May 19, 2024


With the advent of Neural Machine Translation (NMT) systems, the MT output has reached unprecedented accuracy levels which resulted in the ubiquity of MT tools on almost all online platforms with multilingual content. However, NMT systems, like other state-of-the-art AI generative systems, are prone to errors that are deemed machine hallucinations. The problem with NMT hallucinations is that they are remarkably \textit{fluent} hallucinations. Since they are trained to produce grammatically correct utterances, NMT systems are capable of producing mistranslations that are too fluent to be recognised by both users of the MT tool, as well as by automatic quality metrics that are used to gauge their performance. In this paper, we introduce an authentic dataset of machine translation critical errors to point to the ethical and safety issues involved in the common use of MT. The dataset comprises mistranslations of Arabic mental health postings manually annotated with critical error types. We also show how the commonly used quality metrics do not penalise critical errors and highlight this as a critical issue that merits further attention from researchers.
Google Translate Error Analysis for Mental Healthcare Information: Evaluating Accuracy, Comprehensibility, and Implications for Multilingual Healthcare Communication
Feb 06, 2024This study explores the use of Google Translate (GT) for translating mental healthcare (MHealth) information and evaluates its accuracy, comprehensibility, and implications for multilingual healthcare communication through analysing GT output in the MHealth domain from English to Persian, Arabic, Turkish, Romanian, and Spanish. Two datasets comprising MHealth information from the UK National Health Service website and information leaflets from The Royal College of Psychiatrists were used. Native speakers of the target languages manually assessed the GT translations, focusing on medical terminology accuracy, comprehensibility, and critical syntactic/semantic errors. GT output analysis revealed challenges in accurately translating medical terminology, particularly in Arabic, Romanian, and Persian. Fluency issues were prevalent across various languages, affecting comprehension, mainly in Arabic and Spanish. Critical errors arose in specific contexts, such as bullet-point formatting, specifically in Persian, Turkish, and Romanian. Although improvements are seen in longer-text translations, there remains a need to enhance accuracy in medical and mental health terminology and fluency, whilst also addressing formatting issues for a more seamless user experience. The findings highlight the need to use customised translation engines for Mhealth translation and the challenges when relying solely on machine-translated medical content, emphasising the crucial role of human reviewers in multilingual healthcare communication.
SurreyAI 2023 Submission for the Quality Estimation Shared Task
Dec 01, 2023Quality Estimation (QE) systems are important in situations where it is necessary to assess the quality of translations, but there is no reference available. This paper describes the approach adopted by the SurreyAI team for addressing the Sentence-Level Direct Assessment shared task in WMT23. The proposed approach builds upon the TransQuest framework, exploring various autoencoder pre-trained language models within the MonoTransQuest architecture using single and ensemble settings. The autoencoder pre-trained language models employed in the proposed systems are XLMV, InfoXLM-large, and XLMR-large. The evaluation utilizes Spearman and Pearson correlation coefficients, assessing the relationship between machine-predicted quality scores and human judgments for 5 language pairs (English-Gujarati, English-Hindi, English-Marathi, English-Tamil and English-Telugu). The MonoTQ-InfoXLM-large approach emerges as a robust strategy, surpassing all other individual models proposed in this study by significantly improving over the baseline for the majority of the language pairs.
Evaluation of Chinese-English Machine Translation of Emotion-Loaded Microblog Texts: A Human Annotated Dataset for the Quality Assessment of Emotion Translation
Jun 20, 2023In this paper, we focus on how current Machine Translation (MT) tools perform on the translation of emotion-loaded texts by evaluating outputs from Google Translate according to a framework proposed in this paper. We propose this evaluation framework based on the Multidimensional Quality Metrics (MQM) and perform a detailed error analysis of the MT outputs. From our analysis, we observe that about 50% of the MT outputs fail to preserve the original emotion. After further analysis of the errors, we find that emotion carrying words and linguistic phenomena such as polysemous words, negation, abbreviation etc., are common causes for these translation errors.
Biographical: A Semi-Supervised Relation Extraction Dataset
May 02, 2022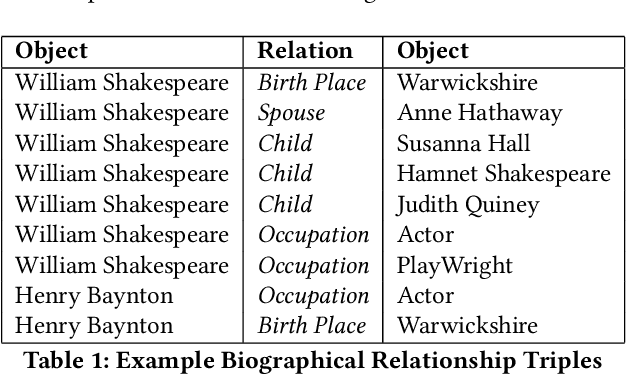
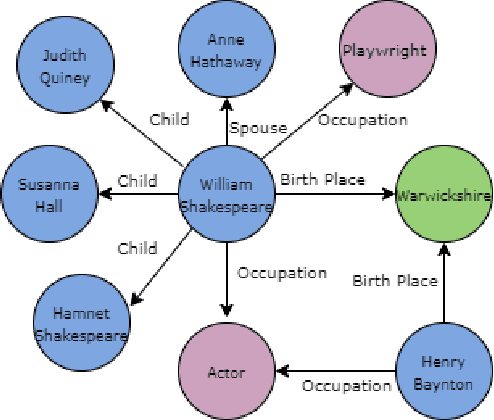
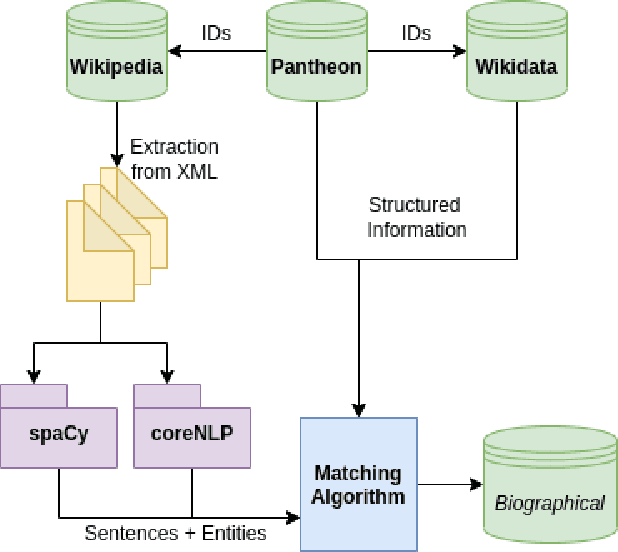
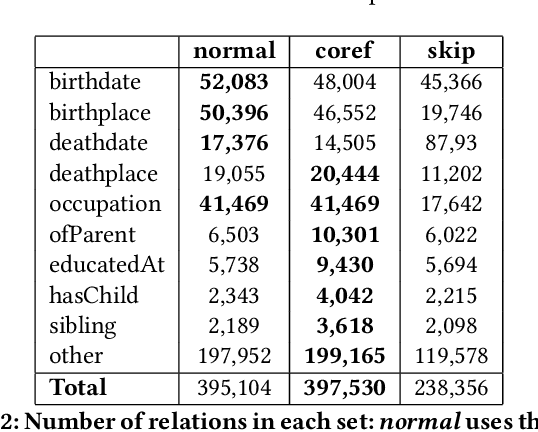
Extracting biographical information from online documents is a popular research topic among the information extraction (IE) community. Various natural language processing (NLP) techniques such as text classification, text summarisation and relation extraction are commonly used to achieve this. Among these techniques, RE is the most common since it can be directly used to build biographical knowledge graphs. RE is usually framed as a supervised machine learning (ML) problem, where ML models are trained on annotated datasets. However, there are few annotated datasets for RE since the annotation process can be costly and time-consuming. To address this, we developed Biographical, the first semi-supervised dataset for RE. The dataset, which is aimed towards digital humanities (DH) and historical research, is automatically compiled by aligning sentences from Wikipedia articles with matching structured data from sources including Pantheon and Wikidata. By exploiting the structure of Wikipedia articles and robust named entity recognition (NER), we match information with relatively high precision in order to compile annotated relation pairs for ten different relations that are important in the DH domain. Furthermore, we demonstrate the effectiveness of the dataset by training a state-of-the-art neural model to classify relation pairs, and evaluate it on a manually annotated gold standard set. Biographical is primarily aimed at training neural models for RE within the domain of digital humanities and history, but as we discuss at the end of this paper, it can be useful for other purposes as well.