 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Risks of Machine Translation Critical Errors : Arabic Mental Health Tweets as a Case Study
May 19, 2024


With the advent of Neural Machine Translation (NMT) systems, the MT output has reached unprecedented accuracy levels which resulted in the ubiquity of MT tools on almost all online platforms with multilingual content. However, NMT systems, like other state-of-the-art AI generative systems, are prone to errors that are deemed machine hallucinations. The problem with NMT hallucinations is that they are remarkably \textit{fluent} hallucinations. Since they are trained to produce grammatically correct utterances, NMT systems are capable of producing mistranslations that are too fluent to be recognised by both users of the MT tool, as well as by automatic quality metrics that are used to gauge their performance. In this paper, we introduce an authentic dataset of machine translation critical errors to point to the ethical and safety issues involved in the common use of MT. The dataset comprises mistranslations of Arabic mental health postings manually annotated with critical error types. We also show how the commonly used quality metrics do not penalise critical errors and highlight this as a critical issue that merits further attention from researchers.
On the Elements of Datasets for Cyber Physical Systems Security
Aug 17, 2022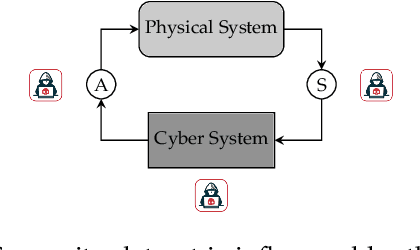

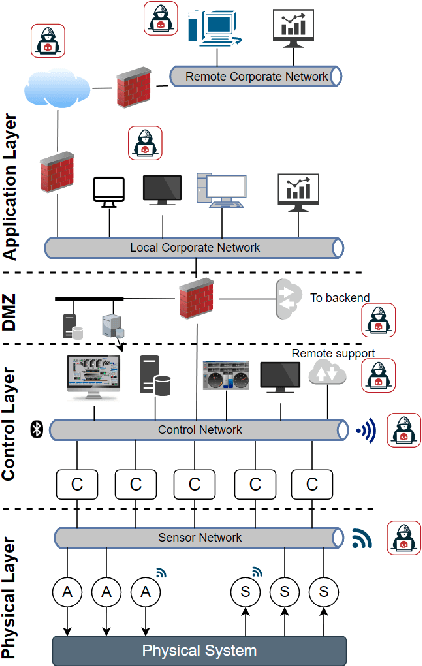

Datasets are essential to apply AI algorithms to Cyber Physical System (CPS) Security. Due to scarcity of real CPS datasets, researchers elected to generate their own datasets using either real or virtualized testbeds. However, unlike other AI domains, a CPS is a complex system with many interfaces that determine its behavior. A dataset that comprises merely a collection of sensor measurements and network traffic may not be sufficient to develop resilient AI defensive or offensive agents. In this paper, we study the \emph{elements} of CPS security datasets required to capture the system behavior and interactions, and propose a dataset architecture that has the potential to enhance the performance of AI algorithms in securing cyber physical systems. The framework includes dataset elements, attack representation, and required dataset features. We compare existing datasets to the proposed architecture to identify the current limitations and discuss the future of CPS dataset generation using testbeds.
Sentiment-Aware Measure (SAM) for Evaluating Sentiment Transfer by Machine Translation Systems
Oct 05, 2021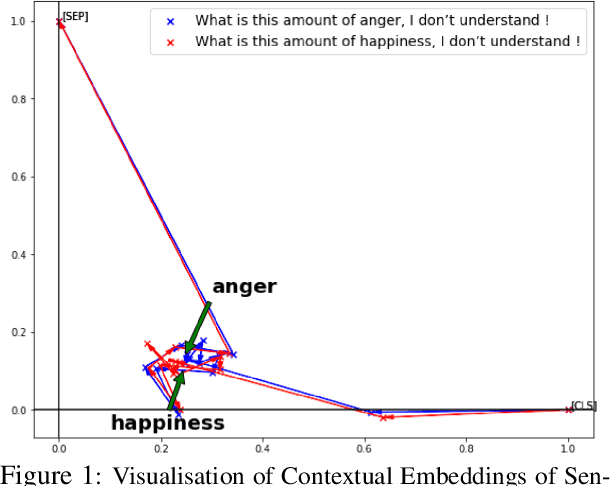

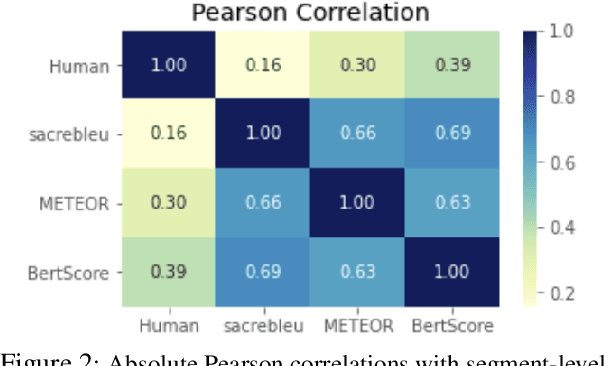
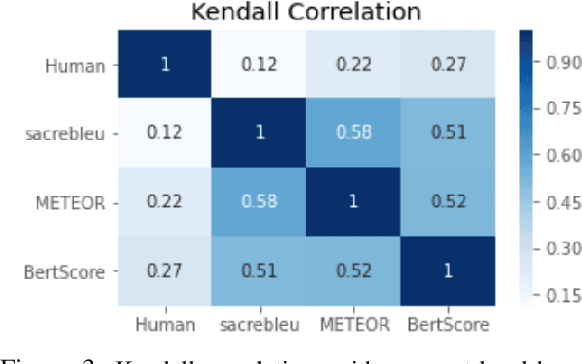
In translating text where sentiment is the main message, human translators give particular attention to sentiment-carrying words. The reason is that an incorrect translation of such words would miss the fundamental aspect of the source text, i.e. the author's sentiment. In the online world, MT systems are extensively used to translate User-Generated Content (UGC) such as reviews, tweets, and social media posts, where the main message is often the author's positive or negative attitude towards the topic of the text. It is important in such scenarios to accurately measure how far an MT system can be a reliable real-life utility in transferring the correct affect message. This paper tackles an under-recognised problem in the field of machine translation evaluation which is judging to what extent automatic metrics concur with the gold standard of human evaluation for a correct translation of sentiment. We evaluate the efficacy of conventional quality metrics in spotting a mistranslation of sentiment, especially when it is the sole error in the MT output. We propose a numerical `sentiment-closeness' measure appropriate for assessing the accuracy of a translated affect message in UGC text by an MT system. We will show that incorporating this sentiment-aware measure can significantly enhance the correlation of some available quality metrics with the human judgement of an accurate translation of sentiment.
* Accepted for RANLP (Recent Advances in Natural Language Processing) 2021