 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Scores: Reinforcement Learning for Error-Aware Quality Estimation of Machine Translation
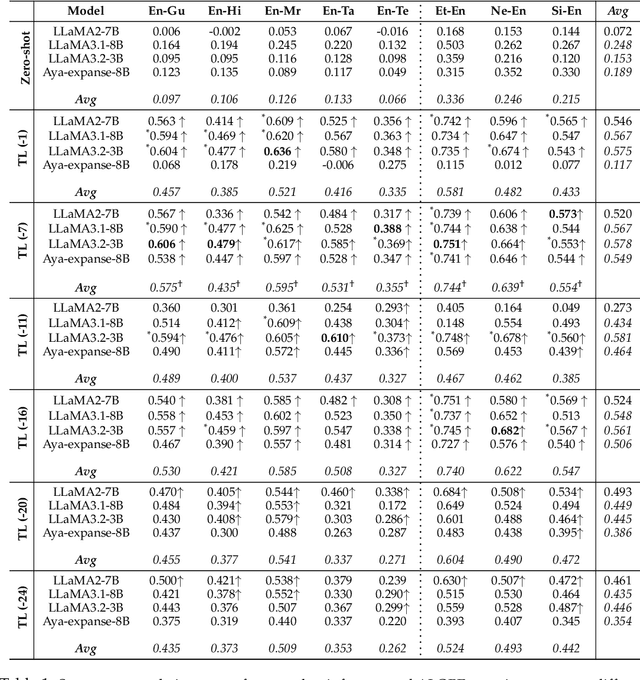
Feb 09, 2026Quality Estimation (QE) aims to assess the quality of machine translation (MT) outputs without relying on reference translations, making it essential for real-world, large-scale MT evaluation. Large Language Models (LLMs) have shown significant promise in advancing the field of quality estimation of machine translation. However, most of the QE approaches solely rely on scalar quality scores, offering no explicit information about the translation errors that should drive these judgments. Moreover, for low-resource languages where annotated QE data is limited, existing approaches struggle to achieve reliable performance. To address these challenges, we introduce the first segment-level QE dataset for English to Malayalam, a severely resource-scarce language pair in the QE domain, comprising human-annotated Direct Assessment (DA) scores and Translation Quality Remarks (TQR), which are short, contextual, free-form annotator comments that describe translation errors. We further introduce ALOPE-RL, a policy-based reinforcement learning framework that trains efficient adapters based on policy rewards derived from DA score and TQR. Integrating error-aware rewards with ALOPE-RL, enables LLMs to reason about translation quality beyond numeric scores. Despite being trained on a small-scale QE dataset, ALOPE-RL achieves state-of-the-art performance on English to Malayalam QE using compact LLMs (<=4B parameters}) fine-tuned with LoRA and 4-bit quantization, outperforming both larger LLM-based baselines and leading encoder-based QE models. Our results demonstrate that error-aware, policy-based learning can deliver strong QE performance under limited data and compute budgets. We release our dataset, code, and trained models to support future research.
ALOPE: Adaptive Layer Optimization for Translation Quality Estimation using Large Language Models
Aug 10, 2025
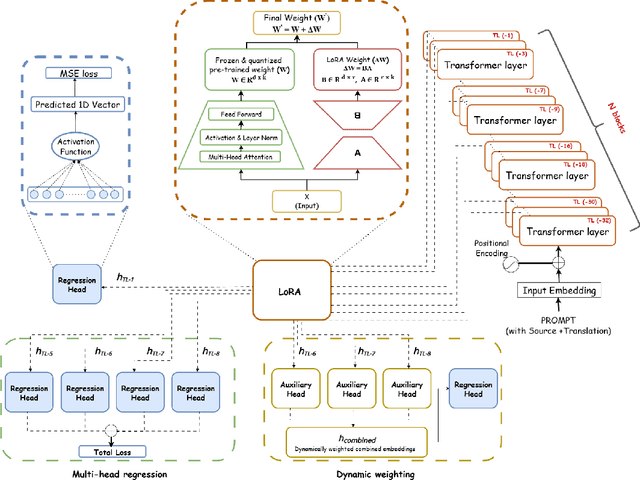
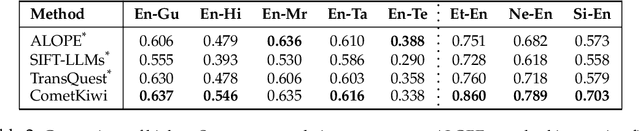
Large Language Models (LLMs) have shown remarkable performance across a wide range of natural language processing tasks. Quality Estimation (QE) for Machine Translation (MT), which assesses the quality of a source-target pair without relying on reference translations, remains a challenging cross-lingual task for LLMs. The challenges stem from the inherent limitations of existing LLM-based QE systems, which are pre-trained for causal language modelling rather than regression-specific tasks, further elevated by the presence of low-resource languages given pre-training data distribution. This paper introduces ALOPE, an adaptive layer-optimization framework designed to enhance LLM-based QE by restructuring Transformer representations through layer-wise adaptation for improved regression-based prediction. Our framework integrates low-rank adapters (LoRA) with regression task heads, leveraging selected pre-trained Transformer layers for improved cross-lingual alignment. In addition to the layer-specific adaptation, ALOPE introduces two strategies-dynamic weighting, which adaptively combines representations from multiple layers, and multi-head regression, which aggregates regression losses from multiple heads for QE. Our framework shows improvements over various existing LLM-based QE approaches. Empirical evidence suggests that intermediate Transformer layers in LLMs provide contextual representations that are more aligned with the cross-lingual nature of the QE task. We make resultant models and framework code publicly available for further research, also allowing existing LLM-based MT frameworks to be scaled with QE capabilities.
When LLMs Struggle: Reference-less Translation Evaluation for Low-resource Languages
Jan 08, 2025



This paper investigates the reference-less evaluation of machine translation for low-resource language pairs, known as quality estimation (QE). Segment-level QE is a challenging cross-lingual language understanding task that provides a quality score (0-100) to the translated output. We comprehensively evaluate large language models (LLMs) in zero/few-shot scenarios and perform instruction fine-tuning using a novel prompt based on annotation guidelines. Our results indicate that prompt-based approaches are outperformed by the encoder-based fine-tuned QE models. Our error analysis reveals tokenization issues, along with errors due to transliteration and named entities, and argues for refinement in LLM pre-training for cross-lingual tasks. We release the data, and models trained publicly for further research.
What do Large Language Models Need for Machine Translation Evaluation?
Oct 04, 2024
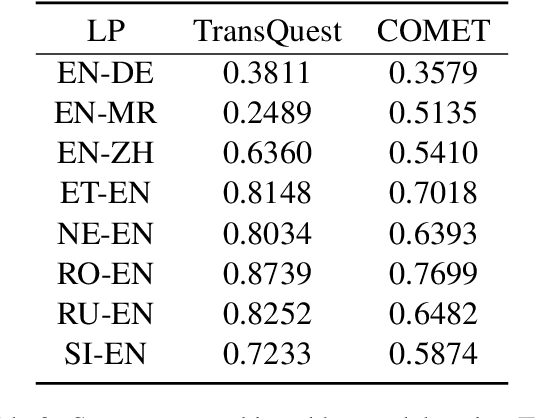
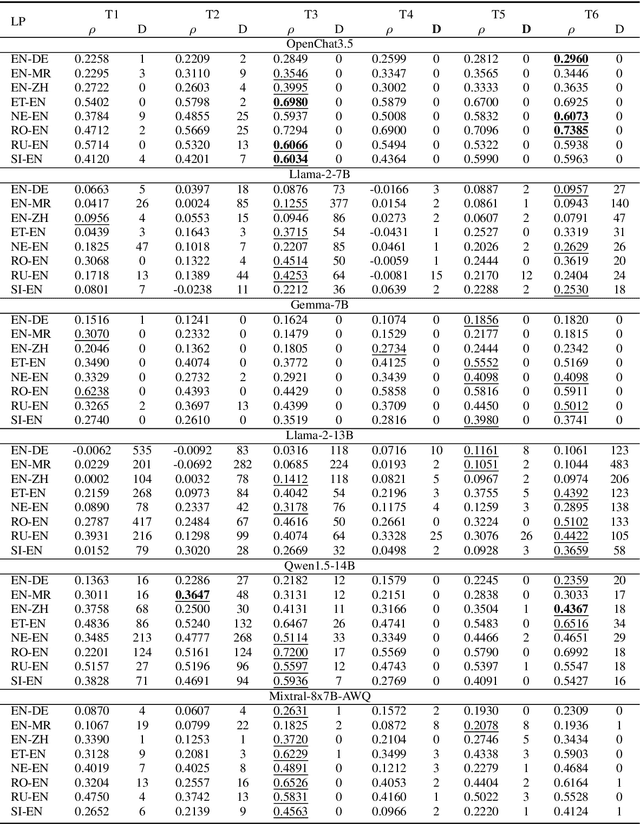
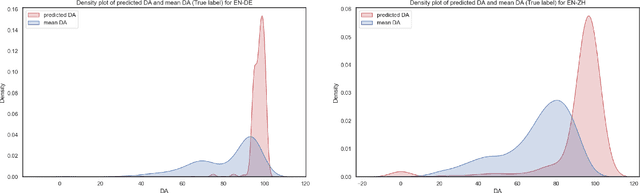
Leveraging large language models (LLMs) for various natural language processing tasks has led to superlative claims about their performance. For the evaluation of machine translation (MT), existing research shows that LLMs are able to achieve results comparable to fine-tuned multilingual pre-trained language models. In this paper, we explore what translation information, such as the source, reference, translation errors and annotation guidelines, is needed for LLMs to evaluate MT quality. In addition, we investigate prompting techniques such as zero-shot, Chain of Thought (CoT) and few-shot prompting for eight language pairs covering high-, medium- and low-resource languages, leveraging varying LLM variants. Our findings indicate the importance of reference translations for an LLM-based evaluation. While larger models do not necessarily fare better, they tend to benefit more from CoT prompting, than smaller models. We also observe that LLMs do not always provide a numerical score when generating evaluations, which poses a question on their reliability for the task. Our work presents a comprehensive analysis for resource-constrained and training-less LLM-based evaluation of machine translation. We release the accrued prompt templates, code and data publicly for reproducibility.
SurreyAI 2023 Submission for the Quality Estimation Shared Task
Dec 01, 2023Quality Estimation (QE) systems are important in situations where it is necessary to assess the quality of translations, but there is no reference available. This paper describes the approach adopted by the SurreyAI team for addressing the Sentence-Level Direct Assessment shared task in WMT23. The proposed approach builds upon the TransQuest framework, exploring various autoencoder pre-trained language models within the MonoTransQuest architecture using single and ensemble settings. The autoencoder pre-trained language models employed in the proposed systems are XLMV, InfoXLM-large, and XLMR-large. The evaluation utilizes Spearman and Pearson correlation coefficients, assessing the relationship between machine-predicted quality scores and human judgments for 5 language pairs (English-Gujarati, English-Hindi, English-Marathi, English-Tamil and English-Telugu). The MonoTQ-InfoXLM-large approach emerges as a robust strategy, surpassing all other individual models proposed in this study by significantly improving over the baseline for the majority of the language pairs.