 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Search Suggestions for Alphanumeric Queries
Apr 01, 2026Alphanumeric identifiers such as manufacturer part numbers (MPNs), SKUs, and model codes are ubiquitous in e-commerce catalogs and search. These identifiers are sparse, non linguistic, and highly sensitive to tokenization and typographical variation, rendering conventional lexical and embedding based retrieval methods ineffective. We propose a training free, character level retrieval framework that encodes each alphanumeric sequence as a fixed length binary vector. This representation enables efficient similarity computation via Hamming distance and supports nearest neighbor retrieval over large identifier corpora. An optional re-ranking stage using edit distance refines precision while preserving latency guarantees. The method offers a practical and interpretable alternative to learned dense retrieval models, making it suitable for production deployment in search suggestion generation systems. Significant gains in business metrics in the A/B test further prove utility of our approach.
Parameter-Efficient Quality Estimation via Frozen Recursive Models
Mar 15, 2026Tiny Recursive Models (TRM) achieve strong results on reasoning tasks through iterative refinement of a shared network. We investigate whether these recursive mechanisms transfer to Quality Estimation (QE) for low-resource languages using a three-phase methodology. Experiments on $8$ language pairs on a low-resource QE dataset reveal three findings. First, TRM's recursive mechanisms do not transfer to QE. External iteration hurts performance, and internal recursion offers only narrow benefits. Next, representation quality dominates architectural choices, and lastly, frozen pretrained embeddings match fine-tuned performance while reducing trainable parameters by 37$\times$ (7M vs 262M). TRM-QE with frozen XLM-R embeddings achieves a Spearman's correlation of 0.370, matching fine-tuned variants (0.369) and outperforming an equivalent-depth standard transformer (0.336). On Hindi and Tamil, frozen TRM-QE outperforms MonoTransQuest (560M parameters) with 80$\times$ fewer trainable parameters, suggesting that weight sharing combined with frozen embeddings enables parameter efficiency for QE. We release the code publicly for further research. Code is available at https://github.com/surrey-nlp/TRMQE.
MUNIChus: Multilingual News Image Captioning Benchmark
Mar 11, 2026The goal of news image captioning is to generate captions by integrating news article content with corresponding images, highlighting the relationship between textual context and visual elements. The majority of research on news image captioning focuses on English, primarily because datasets in other languages are scarce. To address this limitation, we create the first multilingual news image captioning benchmark, MUNIChus, comprising 9 languages, including several low-resource languages such as Sinhala and Urdu. We evaluate various state-of-the-art neural news image captioning models on MUNIChus and find that news image captioning remains challenging. We also make MUNIChus publicly available with over 20 models already benchmarked. MUNIChus opens new avenues for further advancements in developing and evaluating multilingual news image captioning models.
Beyond Scalar Scores: Reinforcement Learning for Error-Aware Quality Estimation of Machine Translation
Feb 09, 2026Quality Estimation (QE) aims to assess the quality of machine translation (MT) outputs without relying on reference translations, making it essential for real-world, large-scale MT evaluation. Large Language Models (LLMs) have shown significant promise in advancing the field of quality estimation of machine translation. However, most of the QE approaches solely rely on scalar quality scores, offering no explicit information about the translation errors that should drive these judgments. Moreover, for low-resource languages where annotated QE data is limited, existing approaches struggle to achieve reliable performance. To address these challenges, we introduce the first segment-level QE dataset for English to Malayalam, a severely resource-scarce language pair in the QE domain, comprising human-annotated Direct Assessment (DA) scores and Translation Quality Remarks (TQR), which are short, contextual, free-form annotator comments that describe translation errors. We further introduce ALOPE-RL, a policy-based reinforcement learning framework that trains efficient adapters based on policy rewards derived from DA score and TQR. Integrating error-aware rewards with ALOPE-RL, enables LLMs to reason about translation quality beyond numeric scores. Despite being trained on a small-scale QE dataset, ALOPE-RL achieves state-of-the-art performance on English to Malayalam QE using compact LLMs (<=4B parameters}) fine-tuned with LoRA and 4-bit quantization, outperforming both larger LLM-based baselines and leading encoder-based QE models. Our results demonstrate that error-aware, policy-based learning can deliver strong QE performance under limited data and compute budgets. We release our dataset, code, and trained models to support future research.
TANDEM: Temporal-Aware Neural Detection for Multimodal Hate Speech
Jan 16, 2026Social media platforms are increasingly dominated by long-form multimodal content, where harmful narratives are constructed through a complex interplay of audio, visual, and textual cues. While automated systems can flag hate speech with high accuracy, they often function as "black boxes" that fail to provide the granular, interpretable evidence, such as precise timestamps and target identities, required for effective human-in-the-loop moderation. In this work, we introduce TANDEM, a unified framework that transforms audio-visual hate detection from a binary classification task into a structured reasoning problem. Our approach employs a novel tandem reinforcement learning strategy where vision-language and audio-language models optimize each other through self-constrained cross-modal context, stabilizing reasoning over extended temporal sequences without requiring dense frame-level supervision. Experiments across three benchmark datasets demonstrate that TANDEM significantly outperforms zero-shot and context-augmented baselines, achieving 0.73 F1 in target identification on HateMM (a 30% improvement over state-of-the-art) while maintaining precise temporal grounding. We further observe that while binary detection is robust, differentiating between offensive and hateful content remains challenging in multi-class settings due to inherent label ambiguity and dataset imbalance. More broadly, our findings suggest that structured, interpretable alignment is achievable even in complex multimodal settings, offering a blueprint for the next generation of transparent and actionable online safety moderation tools.
MAGIC-Talk: Motion-aware Audio-Driven Talking Face Generation with Customizable Identity Control
Oct 26, 2025Audio-driven talking face generation has gained significant attention for applications in digital media and virtual avatars. While recent methods improve audio-lip synchronization, they often struggle with temporal consistency, identity preservation, and customization, especially in long video generation. To address these issues, we propose MAGIC-Talk, a one-shot diffusion-based framework for customizable and temporally stable talking face generation. MAGIC-Talk consists of ReferenceNet, which preserves identity and enables fine-grained facial editing via text prompts, and AnimateNet, which enhances motion coherence using structured motion priors. Unlike previous methods requiring multiple reference images or fine-tuning, MAGIC-Talk maintains identity from a single image while ensuring smooth transitions across frames. Additionally, a progressive latent fusion strategy is introduced to improve long-form video quality by reducing motion inconsistencies and flickering. Extensive experiments demonstrate that MAGIC-Talk outperforms state-of-the-art methods in visual quality, identity preservation, and synchronization accuracy, offering a robust solution for talking face generation.
ALOPE: Adaptive Layer Optimization for Translation Quality Estimation using Large Language Models
Aug 10, 2025
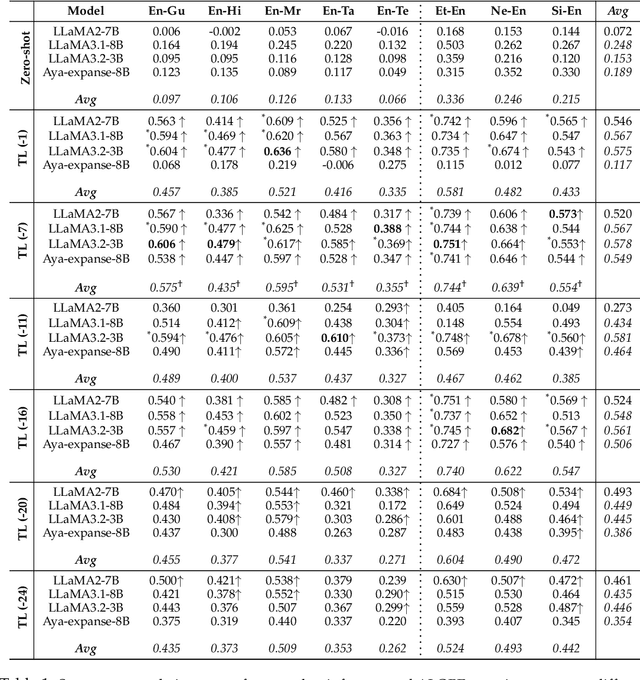
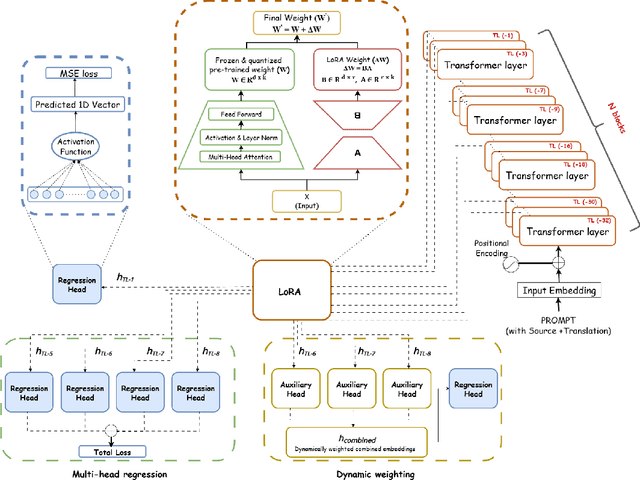
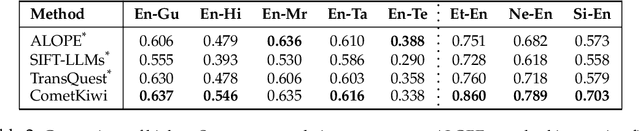
Large Language Models (LLMs) have shown remarkable performance across a wide range of natural language processing tasks. Quality Estimation (QE) for Machine Translation (MT), which assesses the quality of a source-target pair without relying on reference translations, remains a challenging cross-lingual task for LLMs. The challenges stem from the inherent limitations of existing LLM-based QE systems, which are pre-trained for causal language modelling rather than regression-specific tasks, further elevated by the presence of low-resource languages given pre-training data distribution. This paper introduces ALOPE, an adaptive layer-optimization framework designed to enhance LLM-based QE by restructuring Transformer representations through layer-wise adaptation for improved regression-based prediction. Our framework integrates low-rank adapters (LoRA) with regression task heads, leveraging selected pre-trained Transformer layers for improved cross-lingual alignment. In addition to the layer-specific adaptation, ALOPE introduces two strategies-dynamic weighting, which adaptively combines representations from multiple layers, and multi-head regression, which aggregates regression losses from multiple heads for QE. Our framework shows improvements over various existing LLM-based QE approaches. Empirical evidence suggests that intermediate Transformer layers in LLMs provide contextual representations that are more aligned with the cross-lingual nature of the QE task. We make resultant models and framework code publicly available for further research, also allowing existing LLM-based MT frameworks to be scaled with QE capabilities.
Cyberbullying Detection via Aggression-Enhanced Prompting
Aug 08, 2025Detecting cyberbullying on social media remains a critical challenge due to its subtle and varied expressions. This study investigates whether integrating aggression detection as an auxiliary task within a unified training framework can enhance the generalisation and performance of large language models (LLMs) in cyberbullying detection. Experiments are conducted on five aggression datasets and one cyberbullying dataset using instruction-tuned LLMs. We evaluated multiple strategies: zero-shot, few-shot, independent LoRA fine-tuning, and multi-task learning (MTL). Given the inconsistent results of MTL, we propose an enriched prompt pipeline approach in which aggression predictions are embedded into cyberbullying detection prompts to provide contextual augmentation. Preliminary results show that the enriched prompt pipeline consistently outperforms standard LoRA fine-tuning, indicating that aggression-informed context significantly boosts cyberbullying detection. This study highlights the potential of auxiliary tasks, such as aggression detection, to improve the generalisation of LLMs for safety-critical applications on social networks.
NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
CAMU: Context Augmentation for Meme Understanding
Apr 24, 2025



Social media memes are a challenging domain for hate detection because they intertwine visual and textual cues into culturally nuanced messages. We introduce a novel framework, CAMU, which leverages large vision-language models to generate more descriptive captions, a caption-scoring neural network to emphasise hate-relevant content, and parameter-efficient fine-tuning of CLIP's text encoder for an improved multimodal understanding of memes. Experiments on publicly available hateful meme datasets show that simple projection layer fine-tuning yields modest gains, whereas selectively tuning deeper text encoder layers significantly boosts performance on all evaluation metrics. Moreover, our approach attains high accuracy (0.807) and F1-score (0.806) on the Hateful Memes dataset, at par with the existing SoTA framework while being much more efficient, offering practical advantages in real-world scenarios that rely on fixed decision thresholds. CAMU also achieves the best F1-score of 0.673 on the MultiOFF dataset for offensive meme identification, demonstrating its generalisability. Additional analyses on benign confounders reveal that robust visual grounding and nuanced text representations are crucial for reliable hate and offence detection. We will publicly release CAMU along with the resultant models for further research. Disclaimer: This paper includes references to potentially disturbing, hateful, or offensive content due to the nature of the task.