 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANDEM: Temporal-Aware Neural Detection for Multimodal Hate Speech
Jan 16, 2026Social media platforms are increasingly dominated by long-form multimodal content, where harmful narratives are constructed through a complex interplay of audio, visual, and textual cues. While automated systems can flag hate speech with high accuracy, they often function as "black boxes" that fail to provide the granular, interpretable evidence, such as precise timestamps and target identities, required for effective human-in-the-loop moderation. In this work, we introduce TANDEM, a unified framework that transforms audio-visual hate detection from a binary classification task into a structured reasoning problem. Our approach employs a novel tandem reinforcement learning strategy where vision-language and audio-language models optimize each other through self-constrained cross-modal context, stabilizing reasoning over extended temporal sequences without requiring dense frame-level supervision. Experiments across three benchmark datasets demonstrate that TANDEM significantly outperforms zero-shot and context-augmented baselines, achieving 0.73 F1 in target identification on HateMM (a 30% improvement over state-of-the-art) while maintaining precise temporal grounding. We further observe that while binary detection is robust, differentiating between offensive and hateful content remains challenging in multi-class settings due to inherent label ambiguity and dataset imbalance. More broadly, our findings suggest that structured, interpretable alignment is achievable even in complex multimodal settings, offering a blueprint for the next generation of transparent and actionable online safety moderation tools.
CAMU: Context Augmentation for Meme Understanding
Apr 24, 2025



Social media memes are a challenging domain for hate detection because they intertwine visual and textual cues into culturally nuanced messages. We introduce a novel framework, CAMU, which leverages large vision-language models to generate more descriptive captions, a caption-scoring neural network to emphasise hate-relevant content, and parameter-efficient fine-tuning of CLIP's text encoder for an improved multimodal understanding of memes. Experiments on publicly available hateful meme datasets show that simple projection layer fine-tuning yields modest gains, whereas selectively tuning deeper text encoder layers significantly boosts performance on all evaluation metrics. Moreover, our approach attains high accuracy (0.807) and F1-score (0.806) on the Hateful Memes dataset, at par with the existing SoTA framework while being much more efficient, offering practical advantages in real-world scenarios that rely on fixed decision thresholds. CAMU also achieves the best F1-score of 0.673 on the MultiOFF dataset for offensive meme identification, demonstrating its generalisability. Additional analyses on benign confounders reveal that robust visual grounding and nuanced text representations are crucial for reliable hate and offence detection. We will publicly release CAMU along with the resultant models for further research. Disclaimer: This paper includes references to potentially disturbing, hateful, or offensive content due to the nature of the task.
Towards a Robust Framework for Multimodal Hate Detection: A Study on Video vs. Image-based Content
Feb 11, 2025
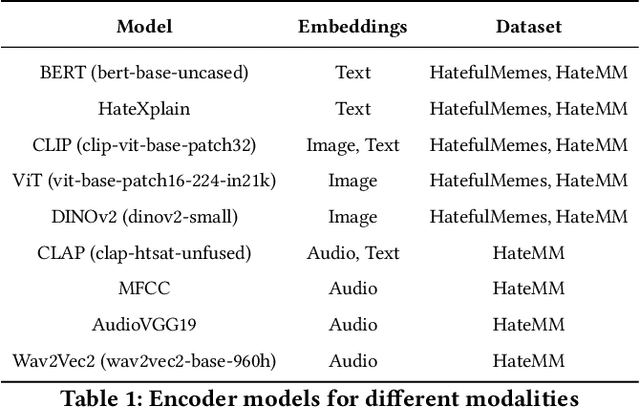
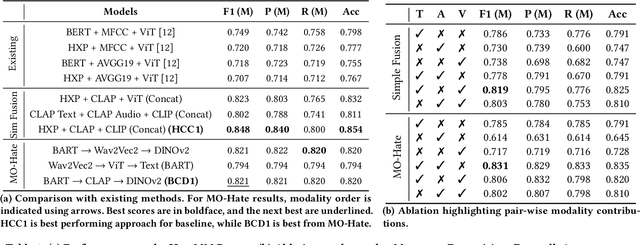
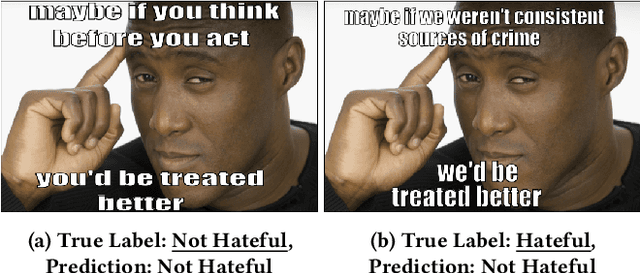
Social media platforms enable the propagation of hateful content across different modalities such as textual, auditory, and visual, necessitating effective detection methods. While recent approaches have shown promise in handling individual modalities, their effectiveness across different modality combinations remains unexplored. This paper presents a systematic analysis of fusion-based approaches for multimodal hate detection, focusing on their performance across video and image-based content. Our comprehensive evaluation reveals significant modality-specific limitations: while simple embedding fusion achieves state-of-the-art performance on video content (HateMM dataset) with a 9.9% points F1-score improvement, it struggles with complex image-text relationships in memes (Hateful Memes dataset). Through detailed ablation studies and error analysis, we demonstrate how current fusion approaches fail to capture nuanced cross-modal interactions, particularly in cases involving benign confounders. Our findings provide crucial insights for developing more robust hate detection systems and highlight the need for modality-specific architectural considerations. The code is available at https://github.com/gak97/Video-vs-Meme-Hate.