 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLA: Cross-Modal Low-rank Adaptation for Multimodal Downstream Tasks
Apr 01, 2026Foundation models have revolutionized AI, but adapting them efficiently for multimodal tasks, particularly in dual-stream architectures composed of unimodal encoders, such as DINO and BERT, remains a significant challenge. Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) enable lightweight adaptation, yet they operate in isolation within each modality, limiting their ability in capturing cross-modal interactions. In this paper, we take a step in bridging this gap with Cross-Modal Low-Rank Adaptation (CoLA), a novel PEFT framework that extends LoRA by introducing a dedicated inter-modal adaptation pathway alongside the standard intra-modal one. This dual-path design enables CoLA to adapt unimodal foundation models to multimodal tasks effectively, without interference between modality-specific and cross-modal learning. We evaluate CoLA across a range of vision-language (RefCOCO, RefCOCO+, RefCOCOg) and audio-visual (AVE, AVS) benchmarks, where it consistently outperforms LORA, achieving a relative gain of around 3\% and 2\%, respectively, while maintaining parameter efficiency. Notably, CoLA enables the first multi-task PEFT framework for visual grounding, bridging a key gap in efficient multimodal adaptation.
Domain Adaptation Without the Compute Burden for Efficient Whole Slide Image Analysis
Mar 16, 2026Computational methods on analyzing Whole Slide Images (WSIs) enable early diagnosis and treatments by supporting pathologists in detection and classification of tumors. However, the extremely high resolution of WSIs makes end-to-end training impractical compared to typical image analysis tasks. To address this, most approaches use pre-trained feature extractors to obtain fixed representations of whole slides, which are then combined with Multiple Instance Learning (MIL) for downstream tasks. These feature extractors are typically pre-trained on natural image datasets such as ImageNet, which fail to capture domain-specific characteristics. Although domain-specific pre-training on histopathology data yields more relevant feature representations, it remains computationally expensive and fail to capture task-specific characteristics within the domain. To address the computational cost and lack of task-specificity in domain-specific pre-training, we propose EfficientWSI (eWSI), a careful integration of Parameter-Efficient-Fine-Tuning (PEFT) and Multiple Instance Learning (MIL) that enables end-to-end training on WSI tasks. We evaluate eWSI on seven WSI-level tasks over Camelyon16, TCGA and BRACS datasets. Our results show that eWSI when applied with ImageNet feature extractors yields strong classification performance, matching or outperforming MILs with in-domain feature extractors, alleviating the need for extensive in-domain pre-training. Furthermore, when eWSI is applied with in-domain feature extractors, it further improves classification performance in most cases, demonstrating its ability to capture task-specific information where beneficial. Our findings suggest that eWSI provides a task-targeted, computationally efficient path for WSI tasks, offering a promising direction for task-specific learning in computational pathology.
DC-ViT: Modulating Spatial and Channel Interactions for Multi-Channel Images
Mar 15, 2026Training and evaluation in multi-channel imaging (MCI) remains challenging due to heterogeneous channel configurations arising from varying staining protocols, sensor types, and acquisition settings. This heterogeneity limits the applicability of fixed-channel encoders commonly used in general computer vision. Recent Multi-Channel Vision Transformers (MC-ViTs) address this by enabling flexible channel inputs, typically by jointly encoding patch tokens from all channels within a unified attention space. However, unrestricted token interactions across channels can lead to feature dilution, reducing the ability to preserve channel-specific semantics that are critical in MCI data. To address this, we propose Decoupled Vision Transformer (DC-ViT), which explicitly regulates information sharing using Decoupled Self-Attention (DSA), which decomposes token updates into two complementary pathways: spatial updates that model intra-channel structure, and channel-wise updates that adaptively integrate cross-channel information. This decoupling mitigates informational collapse while allowing selective inter-channel interaction. To further exploit these enhanced channel-specific representations, we introduce Decoupled Aggregation (DAG), which allows the model to learn task-specific channel importances. Extensive experiments across three MCI benchmarks demonstrate consistent improvements over existing MC-ViT approaches.
Surface-based Manipulation Using Tunable Compliant Porous-Elastic Soft Sensing
Feb 24, 2026There is a growing need for soft robotic platforms that perform gentle, precise handling of a wide variety of objects. Existing surface-based manipulation systems, however, lack the compliance and tactile feedback needed for delicate handling. This work introduces the COmpliant Porous-Elastic Soft Sensing (COPESS) integrated with inductive sensors for adaptive object manipulation and localised sensing. The design features a tunable lattice layer that simultaneously modulates mechanical compliance and sensing performance. By adjusting lattice geometry, both stiffness and sensor response can be tailored to handle objects with varying mechanical properties. Experiments demonstrate that by easily adjusting one parameter, the lattice density, from 7 % to 20 %, it is possible to significantly alter the sensitivity and operational force range (about -23x and 9x, respectively). This approach establishes a blueprint for creating adaptive, sensorized surfaces where mechanical and sensory properties are co-optimized, enabling passive, yet programmable, delicate manipulation.
Channel-Aware Probing for Multi-Channel Imaging
Feb 13, 2026Training and evaluating vision encoders on Multi-Channel Imaging (MCI) data remains challenging as channel configurations vary across datasets, preventing fixed-channel training and limiting reuse of pre-trained encoders on new channel settings. Prior work trains MCI encoders but typically evaluates them via full fine-tuning, leaving probing with frozen pre-trained encoders comparatively underexplored. Existing studies that perform probing largely focus on improving representations, rather than how to best leverage fixed representations for downstream tasks. Although the latter problem has been studied in other domains, directly transferring those strategies to MCI yields weak results, even worse than training from scratch. We therefore propose Channel-Aware Probing (CAP), which exploits the intrinsic inter-channel diversity in MCI datasets by controlling feature flow at both the encoder and probe levels. CAP uses Independent Feature Encoding (IFE) to encode each channel separately, and Decoupled Pooling (DCP) to pool within channels before aggregating across channels. Across three MCI benchmarks, CAP consistently improves probing performance over the default probing protocol, matches fine-tuning from scratch, and largely reduces the gap to full fine-tuning from the same MCI pre-trained checkpoints. Code can be found in https://github.com/umarikkar/CAP.
RAIGen: Rare Attribute Identification in Text-to-Image Generative Models
Feb 06, 2026Text-to-image diffusion models achieve impressive generation quality but inherit and amplify training-data biases, skewing coverage of semantic attributes. Prior work addresses this in two ways. Closed-set approaches mitigate biases in predefined fairness categories (e.g., gender, race), assuming socially salient minority attributes are known a priori. Open-set approaches frame the task as bias identification, highlighting majority attributes that dominate outputs. Both overlook a complementary task: uncovering rare or minority features underrepresented in the data distribution (social, cultural, or stylistic) yet still encoded in model representations. We introduce RAIGen, the first framework, to our knowledge, for un-supervised rare-attribute discovery in diffusion models. RAIGen leverages Matryoshka Sparse Autoencoders and a novel minority metric combining neuron activation frequency with semantic distinctiveness to identify interpretable neurons whose top-activating images reveal underrepresented attributes. Experiments show RAIGen discovers attributes beyond fixed fairness categories in Stable Diffusion, scales to larger models such as SDXL, supports systematic auditing across architectures, and enables targeted amplification of rare attributes during generation.
Qalb: Largest State-of-the-Art Urdu Large Language Model for 230M Speakers with Systematic Continued Pre-training
Jan 13, 2026Despite remarkable progress in large language models, Urdu-a language spoken by over 230 million people-remains critically underrepresented in modern NLP systems. Existing multilingual models demonstrate poor performance on Urdu-specific tasks, struggling with the language's complex morphology, right-to-left Nastaliq script, and rich literary traditions. Even the base LLaMA-3.1 8B-Instruct model shows limited capability in generating fluent, contextually appropriate Urdu text. We introduce Qalb, an Urdu language model developed through a two-stage approach: continued pre-training followed by supervised fine-tuning. Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens. This corpus comprises 1.84 billion tokens of diverse Urdu text-spanning news archives, classical and contemporary literature, government documents, and social media-combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting. We then fine-tune the resulting model on the Alif Urdu-instruct dataset. Through extensive evaluation on Urdu-specific benchmarks, Qalb demonstrates substantial improvements, achieving a weighted average score of 90.34 and outperforming the previous state-of-the-art Alif-1.0-Instruct model (87.1) by 3.24 points, while also surpassing the base LLaMA-3.1 8B-Instruct model by 44.64 points. Qalb achieves state-of-the-art performance with comprehensive evaluation across seven diverse tasks including Classification, Sentiment Analysis, and Reasoning. Our results demonstrate that continued pre-training on diverse, high-quality language data, combined with targeted instruction fine-tuning, effectively adapts foundation models to low-resource languages.
MAGIC-Talk: Motion-aware Audio-Driven Talking Face Generation with Customizable Identity Control
Oct 26, 2025Audio-driven talking face generation has gained significant attention for applications in digital media and virtual avatars. While recent methods improve audio-lip synchronization, they often struggle with temporal consistency, identity preservation, and customization, especially in long video generation. To address these issues, we propose MAGIC-Talk, a one-shot diffusion-based framework for customizable and temporally stable talking face generation. MAGIC-Talk consists of ReferenceNet, which preserves identity and enables fine-grained facial editing via text prompts, and AnimateNet, which enhances motion coherence using structured motion priors. Unlike previous methods requiring multiple reference images or fine-tuning, MAGIC-Talk maintains identity from a single image while ensuring smooth transitions across frames. Additionally, a progressive latent fusion strategy is introduced to improve long-form video quality by reducing motion inconsistencies and flickering. Extensive experiments demonstrate that MAGIC-Talk outperforms state-of-the-art methods in visual quality, identity preservation, and synchronization accuracy, offering a robust solution for talking face generation.
RespoDiff: Dual-Module Bottleneck Transformation for Responsible & Faithful T2I Generation
Sep 18, 2025The rapid advancement of diffusion models has enabled high-fidelity and semantically rich text-to-image generation; however, ensuring fairness and safety remains an open challenge. Existing methods typically improve fairness and safety at the expense of semantic fidelity and image quality. In this work, we propose RespoDiff, a novel framework for responsible text-to-image generation that incorporates a dual-module transformation on the intermediate bottleneck representations of diffusion models. Our approach introduces two distinct learnable modules: one focused on capturing and enforcing responsible concepts, such as fairness and safety, and the other dedicated to maintaining semantic alignment with neutral prompts. To facilitate the dual learning process, we introduce a novel score-matching objective that enables effective coordination between the modules. Our method outperforms state-of-the-art methods in responsible generation by ensuring semantic alignment while optimizing both objectives without compromising image fidelity. Our approach improves responsible and semantically coherent generation by 20% across diverse, unseen prompts. Moreover, it integrates seamlessly into large-scale models like SDXL, enhancing fairness and safety. Code will be released upon acceptance.
How Effectively Can Large Language Models Connect SNP Variants and ECG Phenotypes for Cardiovascular Risk Prediction?
Aug 10, 2025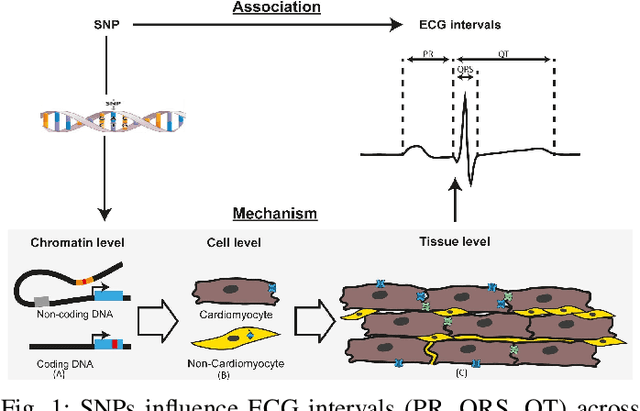
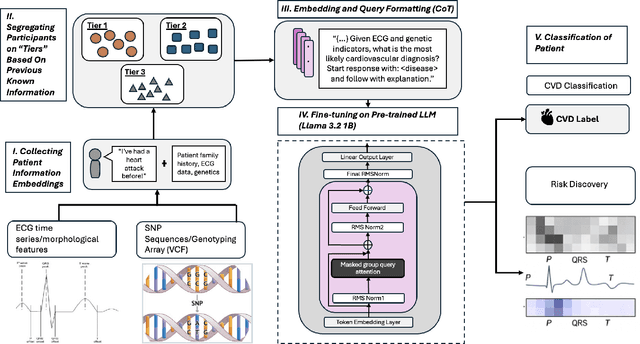
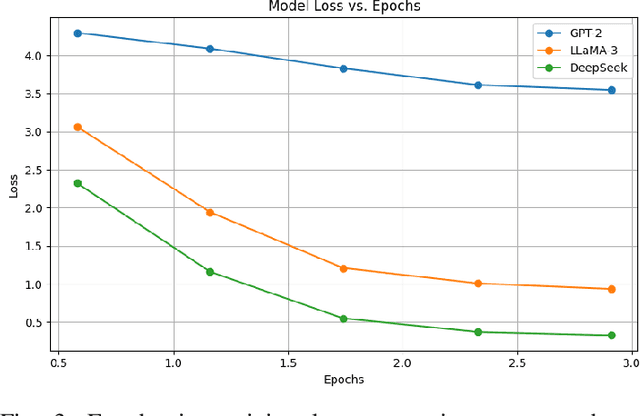
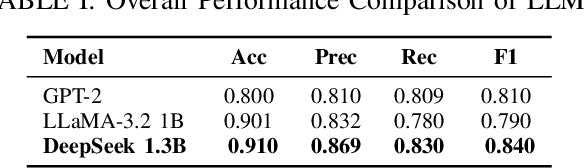
Cardiovascular disease (CVD) prediction remains a tremendous challenge due to its multifactorial etiology and global burden of morbidity and mortality. Despite the growing availability of genomic and electrophysiological data, extracting biologically meaningful insights from such high-dimensional, noisy, and sparsely annotated datasets remains a non-trivial task. Recently, LLMs has been applied effectively to predict structural variations in biological sequences. In this work, we explore the potential of fine-tuned LLMs to predict cardiac diseases and SNPs potentially leading to CVD risk using genetic markers derived from high-throughput genomic profiling. We investigate the effect of genetic patterns associated with cardiac conditions and evaluate how LLMs can learn latent biological relationships from structured and semi-structured genomic data obtained by mapping genetic aspects that are inherited from the family tree. By framing the problem as a Chain of Thought (CoT) reasoning task, the models are prompted to generate disease labels and articulate informed clinical deductions across diverse patient profiles and phenotypes. The findings highlight the promise of LLMs in contributing to early detection, risk assessment, and ultimately, the advancement of personalized medicine in cardiac care.