 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Enhancement Using Vector Semantic Representation and Symbolic Reasoning for Human-Centered Autonomous Emergency Braking
Feb 04, 2026The problem with existing camera-based Deep Reinforcement Learning approaches is twofold: they rarely integrate high-level scene context into the feature representation, and they rely on rigid, fixed reward functions. To address these challenges, this paper proposes a novel pipeline that produces a neuro-symbolic feature representation that encompasses semantic, spatial, and shape information, as well as spatially boosted features of dynamic entities in the scene, with an emphasis on safety-critical road users. It also proposes a Soft First-Order Logic (SFOL) reward function that balances human values via a symbolic reasoning module. Here, semantic and spatial predicates are extracted from segmentation maps and applied to linguistic rules to obtain reward weights. Quantitative experiments in the CARLA simulation environment show that the proposed neuro-symbolic representation and SFOL reward function improved policy robustness and safety-related performance metrics compared to baseline representations and reward formulations across varying traffic densities and occlusion levels. The findings demonstrate that integrating holistic representations and soft reasoning into Reinforcement Learning can support more context-aware and value-aligned decision-making for autonomous driving.
GeoVLM: Improving Automated Vehicle Geolocalisation Using Vision-Language Matching
May 19, 2025Cross-view geo-localisation identifies coarse geographical position of an automated vehicle by matching a ground-level image to a geo-tagged satellite image from a database. Despite the advancements in Cross-view geo-localisation, significant challenges still persist such as similar looking scenes which makes it challenging to find the correct match as the top match. Existing approaches reach high recall rates but they still fail to rank the correct image as the top match. To address this challenge, this paper proposes GeoVLM, a novel approach which uses the zero-shot capabilities of vision language models to enable cross-view geo-localisation using interpretable cross-view language descriptions. GeoVLM is a trainable reranking approach which improves the best match accuracy of cross-view geo-localisation. GeoVLM is evaluated on standard benchmark VIGOR and University-1652 and also through real-life driving environments using Cross-View United Kingdom, a new benchmark dataset introduced in this paper. The results of the paper show that GeoVLM improves retrieval performance of cross-view geo-localisation compared to the state-of-the-art methods with the help of explainable natural language descriptions. The code is available at https://github.com/CAV-Research-Lab/GeoVLM
Offline Reinforcement Learning using Human-Aligned Reward Labeling for Autonomous Emergency Braking in Occluded Pedestrian Crossing
Apr 11, 2025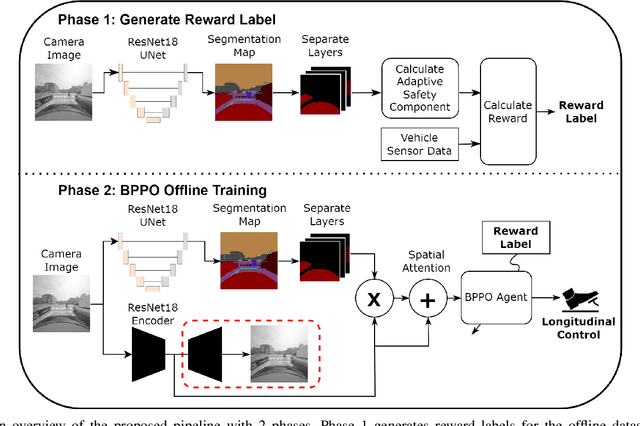

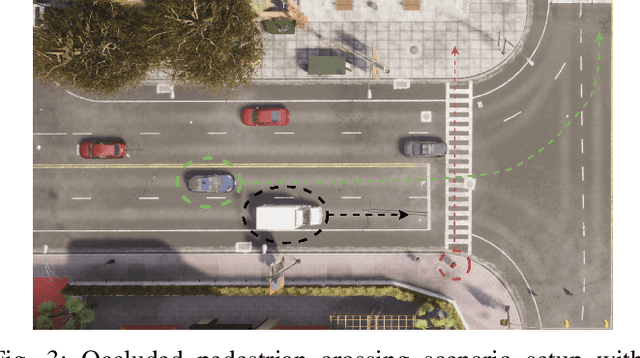
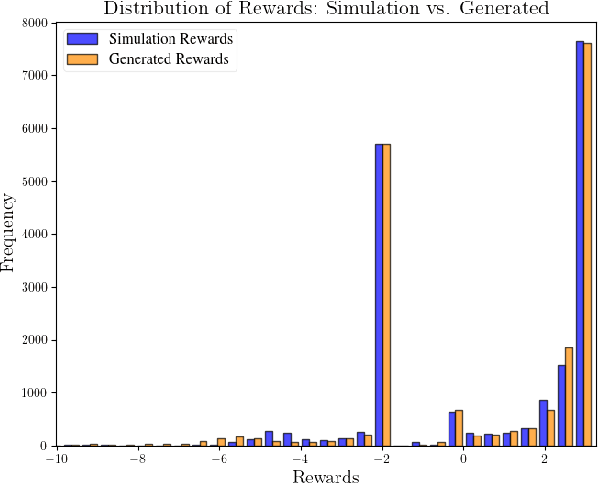
Effective leveraging of real-world driving datasets is crucial for enhancing the training of autonomous driving systems. While Offline Reinforcement Learning enables the training of autonomous vehicles using such data, most available datasets lack meaningful reward labels. Reward labeling is essential as it provides feedback for the learning algorithm to distinguish between desirable and undesirable behaviors, thereby improving policy performance. This paper presents a novel pipeline for generating human-aligned reward labels. The proposed approach addresses the challenge of absent reward signals in real-world datasets by generating labels that reflect human judgment and safety considerations. The pipeline incorporates an adaptive safety component, activated by analyzing semantic segmentation maps, allowing the autonomous vehicle to prioritize safety over efficiency in potential collision scenarios. The proposed pipeline is applied to an occluded pedestrian crossing scenario with varying levels of pedestrian traffic, using synthetic and simulation data. The results indicate that the generated reward labels closely match the simulation reward labels. When used to train the driving policy using Behavior Proximal Policy Optimisation, the results are competitive with other baselines. This demonstrates the effectiveness of our method in producing reliable and human-aligned reward signals, facilitating the training of autonomous driving systems through Reinforcement Learning outside of simulation environments and in alignment with human values.
Neural Lyapunov Function Approximation with Self-Supervised Reinforcement Learning
Mar 19, 2025Control Lyapunov functions are traditionally used to design a controller which ensures convergence to a desired state, yet deriving these functions for nonlinear systems remains a complex challenge. This paper presents a novel, sample-efficient method for neural approximation of nonlinear Lyapunov functions, leveraging self-supervised Reinforcement Learning (RL) to enhance training data generation, particularly for inaccurately represented regions of the state space. The proposed approach employs a data-driven World Model to train Lyapunov functions from off-policy trajectories. The method is validated on both standard and goal-conditioned robotic tasks, demonstrating faster convergence and higher approximation accuracy compared to the state-of-the-art neural Lyapunov approximation baseline. The code is available at: https://github.com/CAV-Research-Lab/SACLA.git
Behavioral Cloning Models Reality Check for Autonomous Driving
Sep 11, 2024


How effective are recent advancements in autonomous vehicle perception systems when applied to real-world autonomous vehicle control? While numerous vision-based autonomous vehicle systems have been trained and evaluated in simulated environments, there is a notable lack of real-world validation for these systems. This paper addresses this gap by presenting the real-world validation of state-of-the-art perception systems that utilize Behavior Cloning (BC) for lateral control, processing raw image data to predict steering commands. The dataset was collected using a scaled research vehicle and tested on various track setups. Experimental results demonstrate that these methods predict steering angles with low error margins in real-time, indicating promising potential for real-world applications.
HighwayLLM: Decision-Making and Navigation in Highway Driving with RL-Informed Language Model
May 22, 2024



Autonomous driving is a complex task which requires advanced decision making and control algorithms. Understanding the rationale behind the autonomous vehicles' decision is crucial to ensure their safe and effective operation on highway driving. This study presents a novel approach, HighwayLLM, which harnesses the reasoning capabilities of large language models (LLMs) to predict the future waypoints for ego-vehicle's navigation. Our approach also utilizes a pre-trained Reinforcement Learning (RL) model to serve as a high-level planner, making decisions on appropriate meta-level actions. The HighwayLLM combines the output from the RL model and the current state information to make safe, collision-free, and explainable predictions for the next states, thereby constructing a trajectory for the ego-vehicle. Subsequently, a PID-based controller guides the vehicle to the waypoints predicted by the LLM agent. This integration of LLM with RL and PID enhances the decision-making process and provides interpretability for highway autonomous driving.
Human-Like Autonomous Driving on Dense Traffic
Oct 03, 2023



This paper proposes a imitation learning model for autonomous driving on highway traffic by mimicking human drivers' driving behaviours. The study utilizes the HighD traffic dataset, which is complex, high-dimensional, and diverse in vehicle variations. Imitation learning is an alternative solution to autonomous highway driving that reduces the sample complexity of learning a challenging task compared to reinforcement learning. However, imitation learning has limitations such as vulnerability to compounding errors in unseen states, poor generalization, and inability to predict outlier driver profiles. To address these issues, the paper proposes mixture density network behaviour cloning model to manage complex and non-linear relationships between inputs and outputs and make more informed decisions about the vehicle's actions. Additional improvement is using collision penalty based on the GAIL model. The paper includes a simulated driving test to demonstrate the effectiveness of the proposed method based on real traffic scenarios and provides conclusions on its potential impact on autonomous driving.
Symbolic Imitation Learning: From Black-Box to Explainable Driving Policies
Sep 27, 2023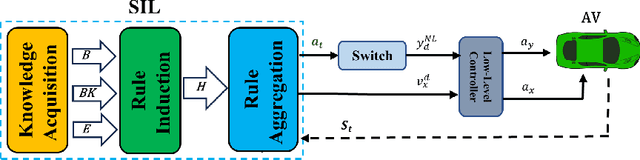
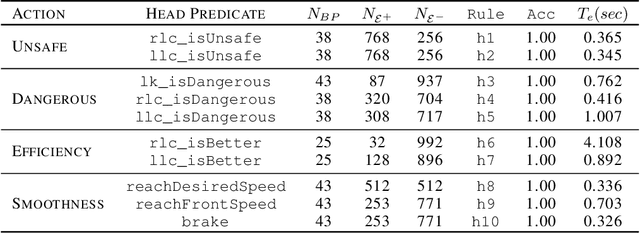

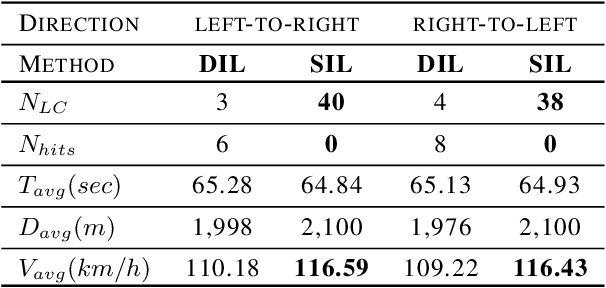
Current methods of imitation learning (IL), primarily based on deep neural networks, offer efficient means for obtaining driving policies from real-world data but suffer from significant limitations in interpretability and generalizability. These shortcomings are particularly concerning in safety-critical applications like autonomous driving. In this paper, we address these limitations by introducing Symbolic Imitation Learning (SIL), a groundbreaking method that employs Inductive Logic Programming (ILP) to learn driving policies which are transparent, explainable and generalisable from available datasets. Utilizing the real-world highD dataset, we subject our method to a rigorous comparative analysis against prevailing neural-network-based IL methods. Our results demonstrate that SIL not only enhances the interpretability of driving policies but also significantly improves their applicability across varied driving situations. Hence, this work offers a novel pathway to more reliable and safer autonomous driving systems, underscoring the potential of integrating ILP into the domain of IL.
Explainable and Trustworthy Traffic Sign Detection for Safe Autonomous Driving: An Inductive Logic Programming Approach
Aug 30, 2023

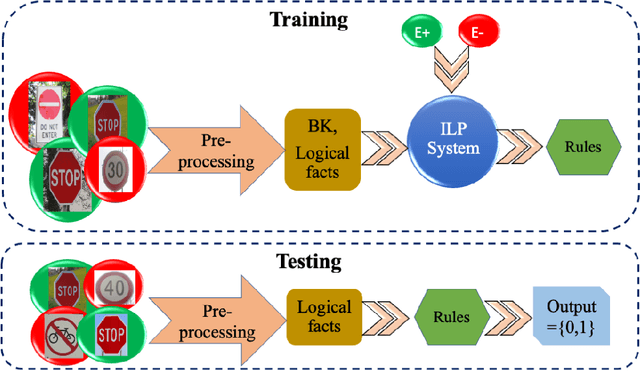

Traffic sign detection is a critical task in the operation of Autonomous Vehicles (AV), as it ensures the safety of all road users. Current DNN-based sign classification systems rely on pixel-level features to detect traffic signs and can be susceptible to adversarial attacks. These attacks involve small, imperceptible changes to a sign that can cause traditional classifiers to misidentify the sign. We propose an Inductive Logic Programming (ILP) based approach for stop sign detection in AVs to address this issue. This method utilises high-level features of a sign, such as its shape, colour, and text, to detect categories of traffic signs. This approach is more robust against adversarial attacks, as it mimics human-like perception and is less susceptible to the limitations of current DNN classifiers. We consider two adversarial attacking methods to evaluate our approach: Robust Physical Perturbation (PR2) and Adversarial Camouflage (AdvCam). These attacks are able to deceive DNN classifiers, causing them to misidentify stop signs as other signs with high confidence. The results show that the proposed ILP-based technique is able to correctly identify all targeted stop signs, even in the presence of PR2 and ADvCam attacks. The proposed learning method is also efficient as it requires minimal training data. Moreover, it is fully explainable, making it possible to debug AVs.
* In Proceedings ICLP 2023, arXiv:2308.14898
Towards Safe Autonomous Driving Policies using a Neuro-Symbolic Deep Reinforcement Learning Approach
Jul 13, 2023



The dynamic nature of driving environments and the presence of diverse road users pose significant challenges for decision-making in autonomous driving. Deep reinforcement learning (DRL) has emerged as a popular approach to tackle this problem. However, the application of existing DRL solutions is mainly confined to simulated environments due to safety concerns, impeding their deployment in real-world. To overcome this limitation, this paper introduces a novel neuro-symbolic model-free DRL approach, called DRL with Symbolic Logics (DRLSL) that combines the strengths of DRL (learning from experience) and symbolic first-order logics (knowledge-driven reasoning) to enable safe learning in real-time interactions of autonomous driving within real environments. This innovative approach provides a means to learn autonomous driving policies by actively engaging with the physical environment while ensuring safety. We have implemented the DRLSL framework in autonomous driving using the highD dataset and demonstrated that our method successfully avoids unsafe actions during both the training and testing phases. Furthermore, our results indicate that DRLSL achieves faster convergence during training and exhibits better generalizability to new driving scenarios compared to traditional DRL methods.