 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning using Human-Aligned Reward Labeling for Autonomous Emergency Braking in Occluded Pedestrian Crossing
Paper and Code
Apr 11, 2025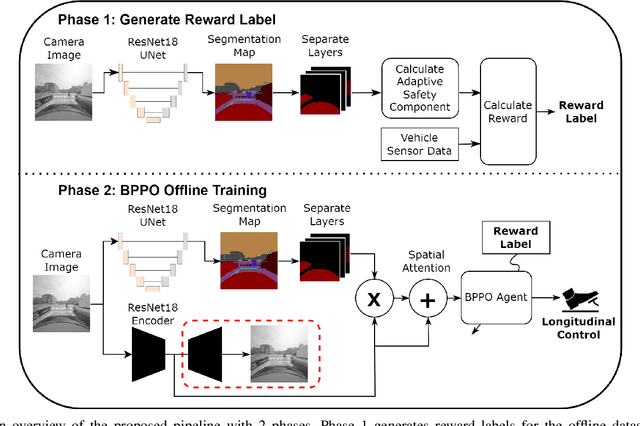

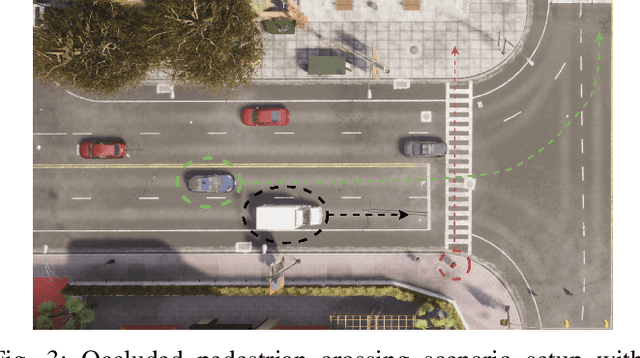
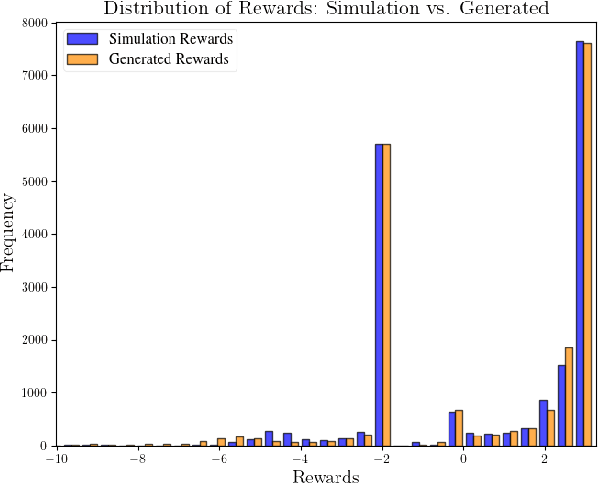
Effective leveraging of real-world driving datasets is crucial for enhancing the training of autonomous driving systems. While Offline Reinforcement Learning enables the training of autonomous vehicles using such data, most available datasets lack meaningful reward labels. Reward labeling is essential as it provides feedback for the learning algorithm to distinguish between desirable and undesirable behaviors, thereby improving policy performance. This paper presents a novel pipeline for generating human-aligned reward labels. The proposed approach addresses the challenge of absent reward signals in real-world datasets by generating labels that reflect human judgment and safety considerations. The pipeline incorporates an adaptive safety component, activated by analyzing semantic segmentation maps, allowing the autonomous vehicle to prioritize safety over efficiency in potential collision scenarios. The proposed pipeline is applied to an occluded pedestrian crossing scenario with varying levels of pedestrian traffic, using synthetic and simulation data. The results indicate that the generated reward labels closely match the simulation reward labels. When used to train the driving policy using Behavior Proximal Policy Optimisation, the results are competitive with other baselines. This demonstrates the effectiveness of our method in producing reliable and human-aligned reward signals, facilitating the training of autonomous driving systems through Reinforcement Learning outside of simulation environments and in alignment with human values.