 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning
Jun 13, 2025Continual multimodal instruction tuning is crucial for adapting Multimodal Large Language Models (MLLMs) to evolving tasks. However, most existing methods adopt a fixed architecture, struggling with adapting to new tasks due to static model capacity. We propose to evolve the architecture under parameter budgets for dynamic task adaptation, which remains unexplored and imposes two challenges: 1) task architecture conflict, where different tasks require varying layer-wise adaptations, and 2) modality imbalance, where different tasks rely unevenly on modalities, leading to unbalanced updates. To address these challenges, we propose a novel Dynamic Mixture of Curriculum LoRA Experts (D-MoLE) method, which automatically evolves MLLM's architecture with controlled parameter budgets to continually adapt to new tasks while retaining previously learned knowledge. Specifically, we propose a dynamic layer-wise expert allocator, which automatically allocates LoRA experts across layers to resolve architecture conflicts, and routes instructions layer-wisely to facilitate knowledge sharing among experts. Then, we propose a gradient-based inter-modal continual curriculum, which adjusts the update ratio of each module in MLLM based on the difficulty of each modality within the task to alleviate the modality imbalance problem. Extensive experiments show that D-MoLE significantly outperforms state-of-the-art baselines, achieving a 15% average improvement over the best baseline. To the best of our knowledge, this is the first study of continual learning for MLLMs from an architectural perspective.
Towards Multi-modal Graph Large Language Model
Jun 11, 2025Multi-modal graphs, which integrate diverse multi-modal features and relations, are ubiquitous in real-world applications. However, existing multi-modal graph learning methods are typically trained from scratch for specific graph data and tasks, failing to generalize across various multi-modal graph data and tasks. To bridge this gap, we explore the potential of Multi-modal Graph Large Language Models (MG-LLM) to unify and generalize across diverse multi-modal graph data and tasks. We propose a unified framework of multi-modal graph data, task, and model, discovering the inherent multi-granularity and multi-scale characteristics in multi-modal graphs. Specifically, we present five key desired characteristics for MG-LLM: 1) unified space for multi-modal structures and attributes, 2) capability of handling diverse multi-modal graph tasks, 3) multi-modal graph in-context learning, 4) multi-modal graph interaction with natural language, and 5) multi-modal graph reasoning. We then elaborate on the key challenges, review related works, and highlight promising future research directions towards realizing these ambitious characteristics. Finally, we summarize existing multi-modal graph datasets pertinent for model training. We believe this paper can contribute to the ongoing advancement of the research towards MG-LLM for generalization across multi-modal graph data and tasks.
Modular Machine Learning: An Indispensable Path towards New-Generation Large Language Models
Apr 28, 2025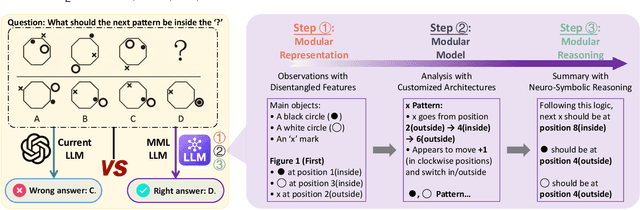
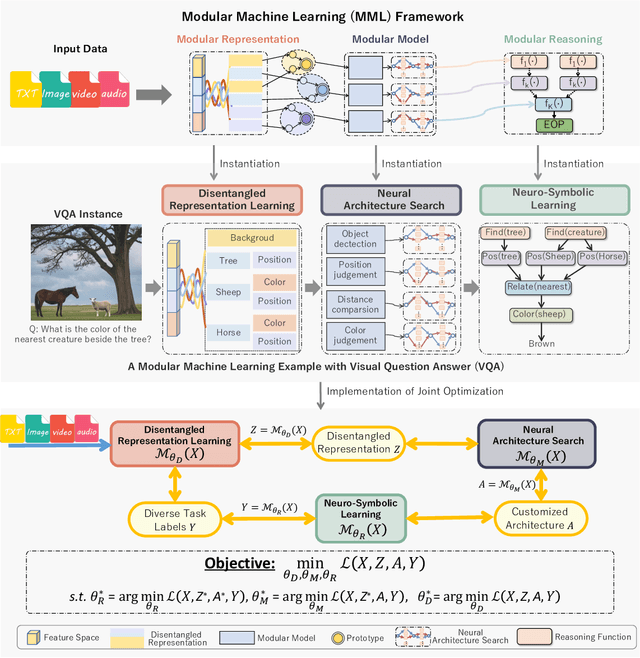
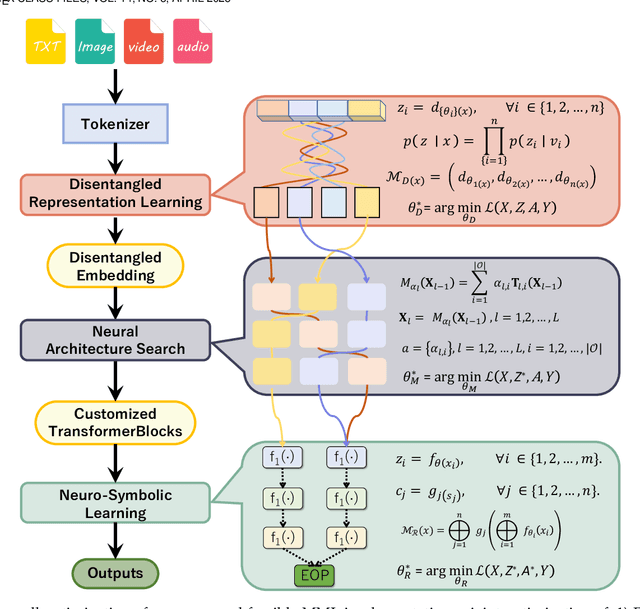
Large language models (LLMs) have dramatically advanced machine learning research including natural language processing, computer vision, data mining, etc., yet they still exhibit critical limitations in reasoning, factual consistency, and interpretability. In this paper, we introduce a novel learning paradigm -- Modular Machine Learning (MML) -- as an essential approach toward new-generation LLMs. MML decomposes the complex structure of LLMs into three interdependent components: modular representation, modular model, and modular reasoning, aiming to enhance LLMs' capability of counterfactual reasoning, mitigating hallucinations, as well as promoting fairness, safety, and transparency. Specifically, the proposed MML paradigm can: i) clarify the internal working mechanism of LLMs through the disentanglement of semantic components; ii) allow for flexible and task-adaptive model design; iii) enable interpretable and logic-driven decision-making process. We present a feasible implementation of MML-based LLMs via leveraging advanced techniques such as disentangled representation learning, neural architecture search and neuro-symbolic learning. We critically identify key challenges, such as the integration of continuous neural and discrete symbolic processes, joint optimization, and computational scalability, present promising future research directions that deserve further exploration. Ultimately, the integration of the MML paradigm with LLMs has the potential to bridge the gap between statistical (deep) learning and formal (logical) reasoning, thereby paving the way for robust, adaptable, and trustworthy AI systems across a wide range of real-world applications.
OCCO: LVM-guided Infrared and Visible Image Fusion Framework based on Object-aware and Contextual COntrastive Learning
Mar 24, 2025Image fusion is a crucial technique in the field of computer vision, and its goal is to generate high-quality fused images and improve the performance of downstream tasks. However, existing fusion methods struggle to balance these two factors. Achieving high quality in fused images may result in lower performance in downstream visual tasks, and vice versa. To address this drawback, a novel LVM (large vision model)-guided fusion framework with Object-aware and Contextual COntrastive learning is proposed, termed as OCCO. The pre-trained LVM is utilized to provide semantic guidance, allowing the network to focus solely on fusion tasks while emphasizing learning salient semantic features in form of contrastive learning. Additionally, a novel feature interaction fusion network is also designed to resolve information conflicts in fusion images caused by modality differences. By learning the distinction between positive samples and negative samples in the latent feature space (contextual space), the integrity of target information in fused image is improved, thereby benefiting downstream performance. Finally, compared with eight state-of-the-art methods on four datasets, the effectiveness of the proposed method is validated, and exceptional performance is also demonstrated on downstream visual task.
Learning a Unified Degradation-aware Representation Model for Multi-modal Image Fusion
Mar 10, 2025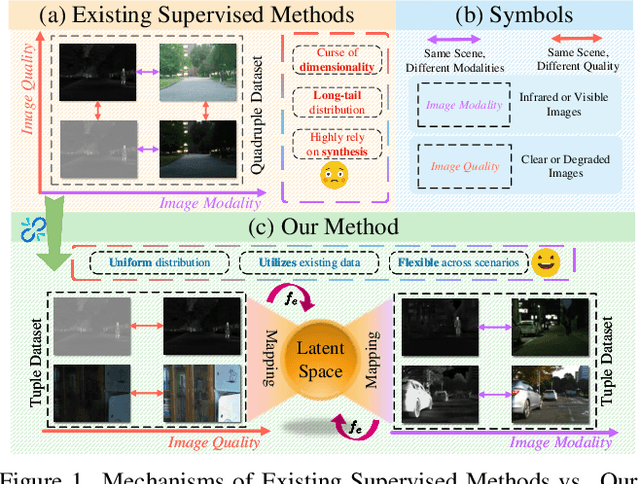
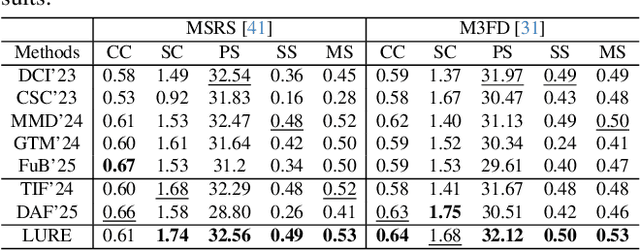
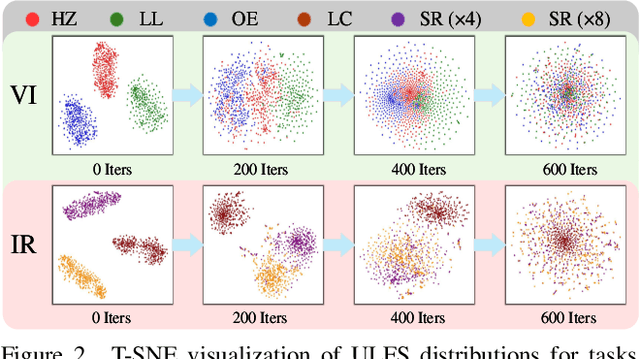
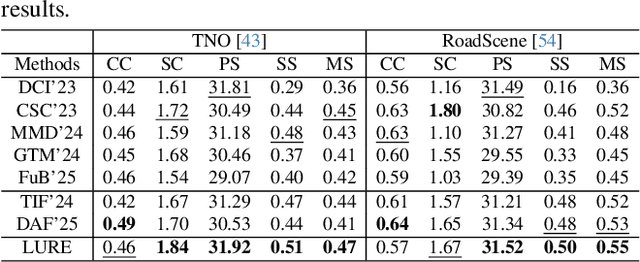
All-in-One Degradation-Aware Fusion Models (ADFMs), a class of multi-modal image fusion models, address complex scenes by mitigating degradations from source images and generating high-quality fused images. Mainstream ADFMs often rely on highly synthetic multi-modal multi-quality images for supervision, limiting their effectiveness in cross-modal and rare degradation scenarios. The inherent relationship among these multi-modal, multi-quality images of the same scene provides explicit supervision for training, but also raises above problems. To address these limitations, we present LURE, a Learning-driven Unified Representation model for infrared and visible Image Fusion, which is degradation-aware. LURE decouples multi-modal multi-quality data at the data level and recouples this relationship in a unified latent feature space (ULFS) by proposing a novel unified loss. This decoupling circumvents data-level limitations of prior models and allows leveraging real-world restoration datasets for training high-quality degradation-aware models, sidestepping above issues. To enhance text-image interaction, we refine image-text interaction and residual structures via Text-Guided Attention (TGA) and an inner residual structure. These enhances text's spatial perception of images and preserve more visual details. Experiments show our method outperforms state-of-the-art (SOTA) methods across general fusion, degradation-aware fusion, and downstream tasks. The code will be publicly available.
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
Feb 27, 2025Advanced image fusion methods mostly prioritise high-level missions, where task interaction struggles with semantic gaps, requiring complex bridging mechanisms. In contrast, we propose to leverage low-level vision tasks from digital photography fusion, allowing for effective feature interaction through pixel-level supervision. This new paradigm provides strong guidance for unsupervised multimodal fusion without relying on abstract semantics, enhancing task-shared feature learning for broader applicability. Owning to the hybrid image features and enhanced universal representations, the proposed GIFNet supports diverse fusion tasks, achieving high performance across both seen and unseen scenarios with a single model. Uniquely, experimental results reveal that our framework also supports single-modality enhancement, offering superior flexibility for practical applications. Our code will be available at https://github.com/AWCXV/GIFNet.
VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding
Oct 11, 2024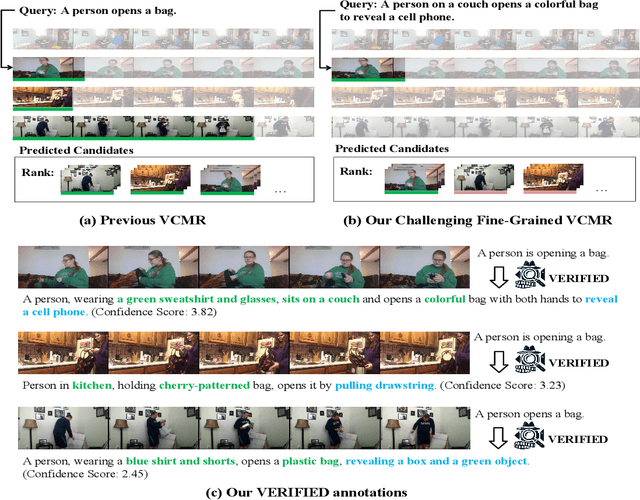



Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding, which hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic \underline{V}id\underline{E}o-text annotation pipeline to generate captions with \underline{R}el\underline{I}able \underline{FI}n\underline{E}-grained statics and \underline{D}ynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR. Code and Datasets are in \href{https://github.com/hlchen23/VERIFIED}{https://github.com/hlchen23/VERIFIED}.
Multi-sentence Video Grounding for Long Video Generation
Jul 18, 2024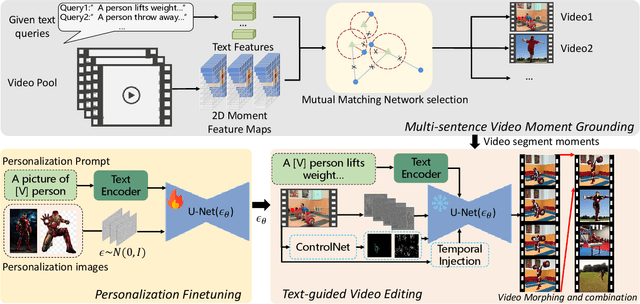



Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Towards Lightweight Graph Neural Network Search with Curriculum Graph Sparsification
Jun 24, 2024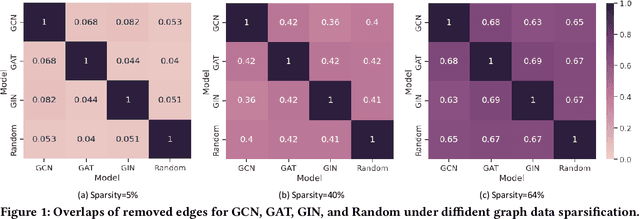

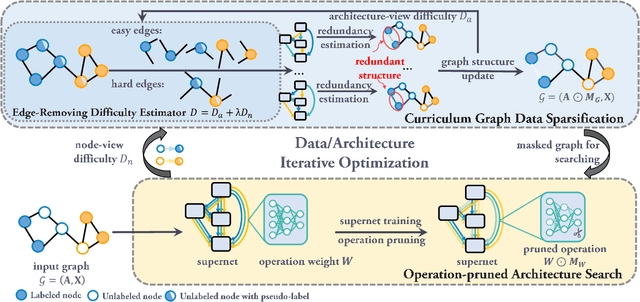
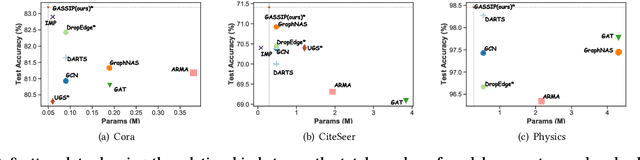
Graph Neural Architecture Search (GNAS) has achieved superior performance on various graph-structured tasks. However, existing GNAS studies overlook the applications of GNAS in resource-constraint scenarios. This paper proposes to design a joint graph data and architecture mechanism, which identifies important sub-architectures via the valuable graph data. To search for optimal lightweight Graph Neural Networks (GNNs), we propose a Lightweight Graph Neural Architecture Search with Graph SparsIfication and Network Pruning (GASSIP) method. In particular, GASSIP comprises an operation-pruned architecture search module to enable efficient lightweight GNN search. Meanwhile, we design a novel curriculum graph data sparsification module with an architecture-aware edge-removing difficulty measurement to help select optimal sub-architectures. With the aid of two differentiable masks, we iteratively optimize these two modules to efficiently search for the optimal lightweight architecture. Extensive experiments on five benchmarks demonstrate the effectiveness of GASSIP. Particularly, our method achieves on-par or even higher node classification performance with half or fewer model parameters of searched GNNs and a sparser graph.