 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionRegister: Every Infrared and Visible Image Fusion Deserves Registration
Mar 08, 2026Spatial registration across different visual modalities is a critical but formidable step in multi-modality image fusion for real-world perception. Although several methods are proposed to address this issue, the existing registration-based fusion methods typically require extensive pre-registration operations, limiting their efficiency. To overcome these limitations, a general cross-modality registration method guided by visual priors is proposed for infrared and visible image fusion task, termed FusionRegister. Firstly, FusionRegister achieves robustness by learning cross-modality misregistration representations rather than forcing alignment of all differences, ensuring stable outputs even under challenging input conditions. Moreover, FusionRegister demonstrates strong generality by operating directly on fused results, where misregistration is explicitly represented and effectively handled, enabling seamless integration with diverse fusion methods while preserving their intrinsic properties. In addition, its efficiency is further enhanced by serving the backbone fusion method as a natural visual prior provider, which guides the registration process to focus only on mismatch regions, thereby avoiding redundant operations. Extensive experiments on three datasets demonstrate that FusionRegister not only inherits the fusion quality of state-of-the-art methods, but also delivers superior detail alignment and robustness, making it highly suitable for infrared and visible image fusion method. The code will be available at https://github.com/bociic/FusionRegister.
Learning a Unified Degradation-aware Representation Model for Multi-modal Image Fusion
Mar 10, 2025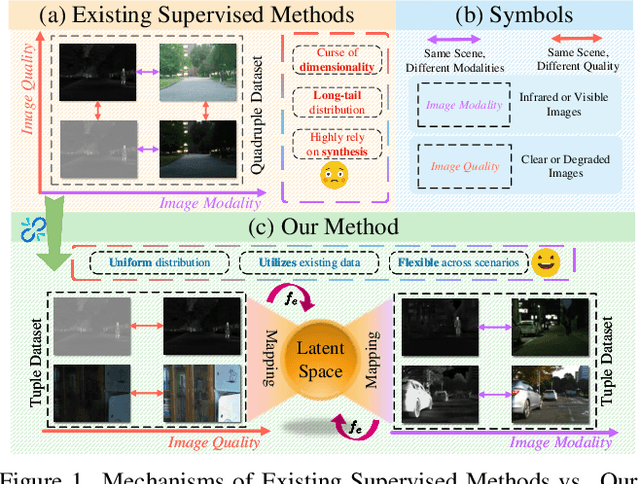
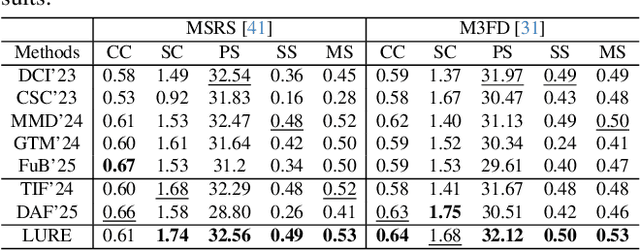
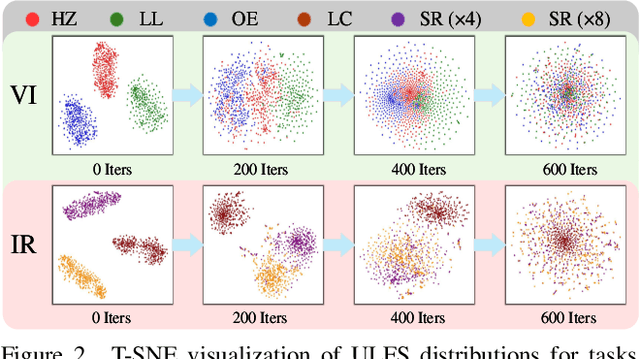
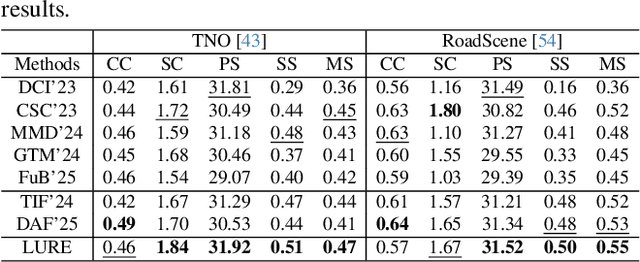
All-in-One Degradation-Aware Fusion Models (ADFMs), a class of multi-modal image fusion models, address complex scenes by mitigating degradations from source images and generating high-quality fused images. Mainstream ADFMs often rely on highly synthetic multi-modal multi-quality images for supervision, limiting their effectiveness in cross-modal and rare degradation scenarios. The inherent relationship among these multi-modal, multi-quality images of the same scene provides explicit supervision for training, but also raises above problems. To address these limitations, we present LURE, a Learning-driven Unified Representation model for infrared and visible Image Fusion, which is degradation-aware. LURE decouples multi-modal multi-quality data at the data level and recouples this relationship in a unified latent feature space (ULFS) by proposing a novel unified loss. This decoupling circumvents data-level limitations of prior models and allows leveraging real-world restoration datasets for training high-quality degradation-aware models, sidestepping above issues. To enhance text-image interaction, we refine image-text interaction and residual structures via Text-Guided Attention (TGA) and an inner residual structure. These enhances text's spatial perception of images and preserve more visual details. Experiments show our method outperforms state-of-the-art (SOTA) methods across general fusion, degradation-aware fusion, and downstream tasks. The code will be publicly available.
CDeFuse: Continuous Decomposition for Infrared and Visible Image Fusion
Jun 07, 2024As a common image processing technique, image decomposition is often used to extract complementary information between modalities. In current decomposition-based image fusion methods, typically, source images are decomposed into three parts at single scale (i.e., visible-exclusive part, infrared-exclusive part, and common part) and lacking interaction between modalities during the decomposition process. These results in the inability of fusion images to effectively focus on finer complementary information between modalities at various scales. To address the above issue, a novel decomposition mechanism, Continuous Decomposition Fusion (CDeFuse), is proposed. Firstly, CDeFuse extends the original three-part decomposition to a more general K-part decomposition at each scale through similarity constraints to fuse multi-scale information and achieve a finer representation of decomposition features. Secondly, a Continuous Decomposition Module (CDM) is introduced to assist K-part decomposition. Its core component, State Transformer (ST), efficiently captures complementary information between modalities by utilizing multi-head self-attention mechanism. Finally, a novel decomposition loss function and the corresponding computational optimization strategy are utilized to ensure the smooth progress of the decomposition process while maintaining linear growth in time complexity with the number of decomposition results K. Extensive experiments demonstrate that our CDeFuse achieves comparable performance compared to previous methods. The code will be publicly available.
S4Fusion: Saliency-aware Selective State Space Model for Infrared Visible Image Fusion
Jun 03, 2024As one of the tasks in Image Fusion, Infrared and Visible Image Fusion aims to integrate complementary information captured by sensors of different modalities into a single image. The Selective State Space Model (SSSM), known for its ability to capture long-range dependencies, has demonstrated its potential in the field of computer vision. However, in image fusion, current methods underestimate the potential of SSSM in capturing the global spatial information of both modalities. This limitation prevents the simultaneous consideration of the global spatial information from both modalities during interaction, leading to a lack of comprehensive perception of salient targets. Consequently, the fusion results tend to bias towards one modality instead of adaptively preserving salient targets. To address this issue, we propose the Saliency-aware Selective State Space Fusion Model (S4Fusion). In our S4Fusion, the designed Cross-Modal Spatial Awareness Module (CMSA) can simultaneously focus on global spatial information from both modalities while facilitating their interaction, thereby comprehensively capturing complementary information. Additionally, S4Fusion leverages a pre-trained network to perceive uncertainty in the fused images. By minimizing this uncertainty, S4Fusion adaptively highlights salient targets from both images. Extensive experiments demonstrate that our approach produces high-quality images and enhances performance in downstream tasks.