 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionRegister: Every Infrared and Visible Image Fusion Deserves Registration
Mar 08, 2026Spatial registration across different visual modalities is a critical but formidable step in multi-modality image fusion for real-world perception. Although several methods are proposed to address this issue, the existing registration-based fusion methods typically require extensive pre-registration operations, limiting their efficiency. To overcome these limitations, a general cross-modality registration method guided by visual priors is proposed for infrared and visible image fusion task, termed FusionRegister. Firstly, FusionRegister achieves robustness by learning cross-modality misregistration representations rather than forcing alignment of all differences, ensuring stable outputs even under challenging input conditions. Moreover, FusionRegister demonstrates strong generality by operating directly on fused results, where misregistration is explicitly represented and effectively handled, enabling seamless integration with diverse fusion methods while preserving their intrinsic properties. In addition, its efficiency is further enhanced by serving the backbone fusion method as a natural visual prior provider, which guides the registration process to focus only on mismatch regions, thereby avoiding redundant operations. Extensive experiments on three datasets demonstrate that FusionRegister not only inherits the fusion quality of state-of-the-art methods, but also delivers superior detail alignment and robustness, making it highly suitable for infrared and visible image fusion method. The code will be available at https://github.com/bociic/FusionRegister.
Revisiting Generative Infrared and Visible Image Fusion Based on Human Cognitive Laws
Oct 30, 2025Existing infrared and visible image fusion methods often face the dilemma of balancing modal information. Generative fusion methods reconstruct fused images by learning from data distributions, but their generative capabilities remain limited. Moreover, the lack of interpretability in modal information selection further affects the reliability and consistency of fusion results in complex scenarios. This manuscript revisits the essence of generative image fusion under the inspiration of human cognitive laws and proposes a novel infrared and visible image fusion method, termed HCLFuse. First, HCLFuse investigates the quantification theory of information mapping in unsupervised fusion networks, which leads to the design of a multi-scale mask-regulated variational bottleneck encoder. This encoder applies posterior probability modeling and information decomposition to extract accurate and concise low-level modal information, thereby supporting the generation of high-fidelity structural details. Furthermore, the probabilistic generative capability of the diffusion model is integrated with physical laws, forming a time-varying physical guidance mechanism that adaptively regulates the generation process at different stages, thereby enhancing the ability of the model to perceive the intrinsic structure of data and reducing dependence on data quality. Experimental results show that the proposed method achieves state-of-the-art fusion performance in qualitative and quantitative evaluations across multiple datasets and significantly improves semantic segmentation metrics. This fully demonstrates the advantages of this generative image fusion method, drawing inspiration from human cognition, in enhancing structural consistency and detail quality.
OCCO: LVM-guided Infrared and Visible Image Fusion Framework based on Object-aware and Contextual COntrastive Learning
Mar 24, 2025Image fusion is a crucial technique in the field of computer vision, and its goal is to generate high-quality fused images and improve the performance of downstream tasks. However, existing fusion methods struggle to balance these two factors. Achieving high quality in fused images may result in lower performance in downstream visual tasks, and vice versa. To address this drawback, a novel LVM (large vision model)-guided fusion framework with Object-aware and Contextual COntrastive learning is proposed, termed as OCCO. The pre-trained LVM is utilized to provide semantic guidance, allowing the network to focus solely on fusion tasks while emphasizing learning salient semantic features in form of contrastive learning. Additionally, a novel feature interaction fusion network is also designed to resolve information conflicts in fusion images caused by modality differences. By learning the distinction between positive samples and negative samples in the latent feature space (contextual space), the integrity of target information in fused image is improved, thereby benefiting downstream performance. Finally, compared with eight state-of-the-art methods on four datasets, the effectiveness of the proposed method is validated, and exceptional performance is also demonstrated on downstream visual task.
Learning a Unified Degradation-aware Representation Model for Multi-modal Image Fusion
Mar 10, 2025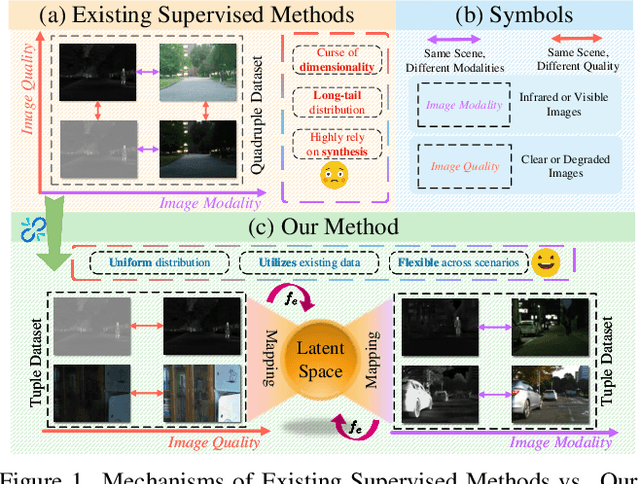
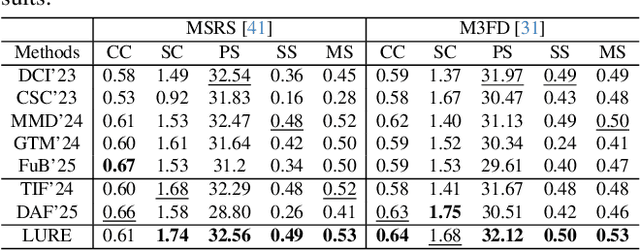
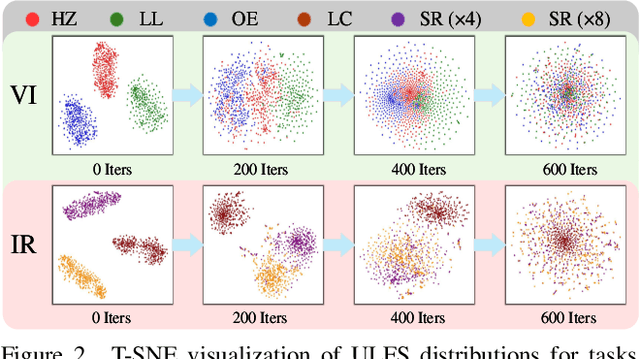
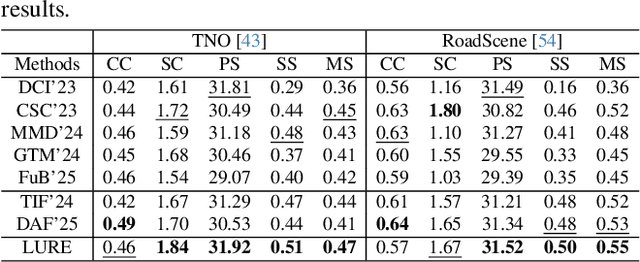
All-in-One Degradation-Aware Fusion Models (ADFMs), a class of multi-modal image fusion models, address complex scenes by mitigating degradations from source images and generating high-quality fused images. Mainstream ADFMs often rely on highly synthetic multi-modal multi-quality images for supervision, limiting their effectiveness in cross-modal and rare degradation scenarios. The inherent relationship among these multi-modal, multi-quality images of the same scene provides explicit supervision for training, but also raises above problems. To address these limitations, we present LURE, a Learning-driven Unified Representation model for infrared and visible Image Fusion, which is degradation-aware. LURE decouples multi-modal multi-quality data at the data level and recouples this relationship in a unified latent feature space (ULFS) by proposing a novel unified loss. This decoupling circumvents data-level limitations of prior models and allows leveraging real-world restoration datasets for training high-quality degradation-aware models, sidestepping above issues. To enhance text-image interaction, we refine image-text interaction and residual structures via Text-Guided Attention (TGA) and an inner residual structure. These enhances text's spatial perception of images and preserve more visual details. Experiments show our method outperforms state-of-the-art (SOTA) methods across general fusion, degradation-aware fusion, and downstream tasks. The code will be publicly available.
Learning Structure-Supporting Dependencies via Keypoint Interactive Transformer for General Mammal Pose Estimation
Feb 25, 2025General mammal pose estimation is an important and challenging task in computer vision, which is essential for understanding mammal behaviour in real-world applications. However, existing studies are at their preliminary research stage, which focus on addressing the problem for only a few specific mammal species. In principle, from specific to general mammal pose estimation, the biggest issue is how to address the huge appearance and pose variances for different species. We argue that given appearance context, instance-level prior and the structural relation among keypoints can serve as complementary evidence. To this end, we propose a Keypoint Interactive Transformer (KIT) to learn instance-level structure-supporting dependencies for general mammal pose estimation. Specifically, our KITPose consists of two coupled components. The first component is to extract keypoint features and generate body part prompts. The features are supervised by a dedicated generalised heatmap regression loss (GHRL). Instead of introducing external visual/text prompts, we devise keypoints clustering to generate body part biases, aligning them with image context to generate corresponding instance-level prompts. Second, we propose a novel interactive transformer that takes feature slices as input tokens without performing spatial splitting. In addition, to enhance the capability of the KIT model, we design an adaptive weight strategy to address the imbalance issue among different keypoints.
CDeFuse: Continuous Decomposition for Infrared and Visible Image Fusion
Jun 07, 2024As a common image processing technique, image decomposition is often used to extract complementary information between modalities. In current decomposition-based image fusion methods, typically, source images are decomposed into three parts at single scale (i.e., visible-exclusive part, infrared-exclusive part, and common part) and lacking interaction between modalities during the decomposition process. These results in the inability of fusion images to effectively focus on finer complementary information between modalities at various scales. To address the above issue, a novel decomposition mechanism, Continuous Decomposition Fusion (CDeFuse), is proposed. Firstly, CDeFuse extends the original three-part decomposition to a more general K-part decomposition at each scale through similarity constraints to fuse multi-scale information and achieve a finer representation of decomposition features. Secondly, a Continuous Decomposition Module (CDM) is introduced to assist K-part decomposition. Its core component, State Transformer (ST), efficiently captures complementary information between modalities by utilizing multi-head self-attention mechanism. Finally, a novel decomposition loss function and the corresponding computational optimization strategy are utilized to ensure the smooth progress of the decomposition process while maintaining linear growth in time complexity with the number of decomposition results K. Extensive experiments demonstrate that our CDeFuse achieves comparable performance compared to previous methods. The code will be publicly available.
S4Fusion: Saliency-aware Selective State Space Model for Infrared Visible Image Fusion
Jun 03, 2024As one of the tasks in Image Fusion, Infrared and Visible Image Fusion aims to integrate complementary information captured by sensors of different modalities into a single image. The Selective State Space Model (SSSM), known for its ability to capture long-range dependencies, has demonstrated its potential in the field of computer vision. However, in image fusion, current methods underestimate the potential of SSSM in capturing the global spatial information of both modalities. This limitation prevents the simultaneous consideration of the global spatial information from both modalities during interaction, leading to a lack of comprehensive perception of salient targets. Consequently, the fusion results tend to bias towards one modality instead of adaptively preserving salient targets. To address this issue, we propose the Saliency-aware Selective State Space Fusion Model (S4Fusion). In our S4Fusion, the designed Cross-Modal Spatial Awareness Module (CMSA) can simultaneously focus on global spatial information from both modalities while facilitating their interaction, thereby comprehensively capturing complementary information. Additionally, S4Fusion leverages a pre-trained network to perceive uncertainty in the fused images. By minimizing this uncertainty, S4Fusion adaptively highlights salient targets from both images. Extensive experiments demonstrate that our approach produces high-quality images and enhances performance in downstream tasks.
CoMoFusion: Fast and High-quality Fusion of Infrared and Visible Image with Consistency Model
May 31, 2024Generative models are widely utilized to model the distribution of fused images in the field of infrared and visible image fusion. However, current generative models based fusion methods often suffer from unstable training and slow inference speed. To tackle this problem, a novel fusion method based on consistency model is proposed, termed as CoMoFusion, which can generate the high-quality images and achieve fast image inference speed. In specific, the consistency model is used to construct multi-modal joint features in the latent space with the forward and reverse process. Then, the infrared and visible features extracted by the trained consistency model are fed into fusion module to generate the final fused image. In order to enhance the texture and salient information of fused images, a novel loss based on pixel value selection is also designed. Extensive experiments on public datasets illustrate that our method obtains the SOTA fusion performance compared with the existing fusion methods.
WavePF: A Novel Fusion Approach based on Wavelet-guided Pooling for Infrared and Visible Images
May 27, 2023



Infrared and visible image fusion aims to generate synthetic images simultaneously containing salient features and rich texture details, which can be used to boost downstream tasks. However, existing fusion methods are suffering from the issues of texture loss and edge information deficiency, which result in suboptimal fusion results. Meanwhile, the straight-forward up-sampling operator can not well preserve the source information from multi-scale features. To address these issues, a novel fusion network based on the wavelet-guided pooling (wave-pooling) manner is proposed, termed as WavePF. Specifically, a wave-pooling based encoder is designed to extract multi-scale image and detail features of source images at the same time. In addition, the spatial attention model is used to aggregate these salient features. After that, the fused features will be reconstructed by the decoder, in which the up-sampling operator is replaced by the wave-pooling reversed operation. Different from the common max-pooling technique, image features after the wave-pooling layer can retain abundant details information, which can benefit the fusion process. In this case, rich texture details and multi-scale information can be maintained during the reconstruction phase. The experimental results demonstrate that our method exhibits superior fusion performance over the state-of-the-arts on multiple image fusion benchmarks
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023

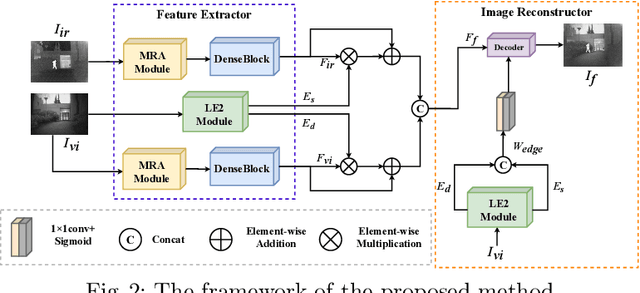
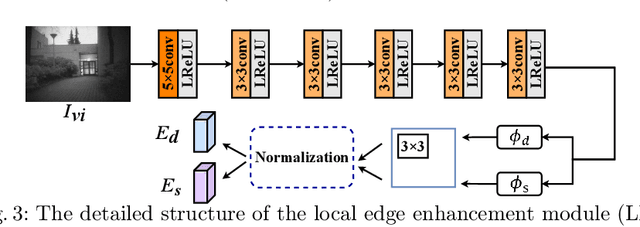
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.