 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionRegister: Every Infrared and Visible Image Fusion Deserves Registration
Mar 08, 2026Spatial registration across different visual modalities is a critical but formidable step in multi-modality image fusion for real-world perception. Although several methods are proposed to address this issue, the existing registration-based fusion methods typically require extensive pre-registration operations, limiting their efficiency. To overcome these limitations, a general cross-modality registration method guided by visual priors is proposed for infrared and visible image fusion task, termed FusionRegister. Firstly, FusionRegister achieves robustness by learning cross-modality misregistration representations rather than forcing alignment of all differences, ensuring stable outputs even under challenging input conditions. Moreover, FusionRegister demonstrates strong generality by operating directly on fused results, where misregistration is explicitly represented and effectively handled, enabling seamless integration with diverse fusion methods while preserving their intrinsic properties. In addition, its efficiency is further enhanced by serving the backbone fusion method as a natural visual prior provider, which guides the registration process to focus only on mismatch regions, thereby avoiding redundant operations. Extensive experiments on three datasets demonstrate that FusionRegister not only inherits the fusion quality of state-of-the-art methods, but also delivers superior detail alignment and robustness, making it highly suitable for infrared and visible image fusion method. The code will be available at https://github.com/bociic/FusionRegister.
NN-ResDMD: Learning Koopman Representations for Complex Dynamics with Spectral Residuals
Jan 01, 2025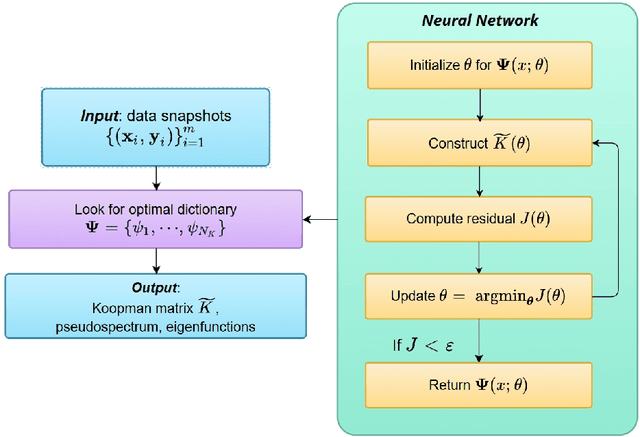

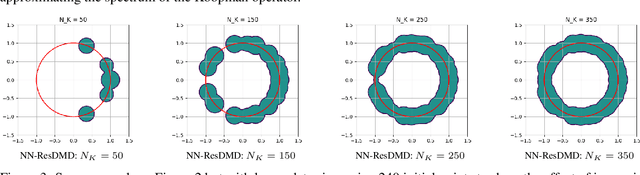

Analyzing long-term behaviors in high-dimensional nonlinear dynamical systems remains a significant challenge. The Koopman operator framework has emerged as a powerful tool to address this issue by providing a globally linear perspective on nonlinear dynamics. However, existing methods for approximating the Koopman operator and its spectral components, particularly in large-scale systems, often lack robust theoretical guarantees. Residual Dynamic Mode Decomposition (ResDMD) introduces a spectral residual measure to assess the convergence of the estimated Koopman spectrum, which helps filter out spurious spectral components. Nevertheless, it depends on pre-computed spectra, thereby inheriting their inaccuracies. To overcome its limitations, we introduce the Neural Network-ResDMD (NN-ResDMD), a method that directly estimates Koopman spectral components by minimizing the spectral residual. By leveraging neural networks, NN-ResDMD automatically identifies the optimal basis functions of the Koopman invariant subspace, eliminating the need for manual selection and improving the reliability of the analysis. Experiments on physical and biological systems demonstrate that NN-ResDMD significantly improves both accuracy and scalability, making it an effective tool for analyzing complex dynamical systems.
CDeFuse: Continuous Decomposition for Infrared and Visible Image Fusion
Jun 07, 2024As a common image processing technique, image decomposition is often used to extract complementary information between modalities. In current decomposition-based image fusion methods, typically, source images are decomposed into three parts at single scale (i.e., visible-exclusive part, infrared-exclusive part, and common part) and lacking interaction between modalities during the decomposition process. These results in the inability of fusion images to effectively focus on finer complementary information between modalities at various scales. To address the above issue, a novel decomposition mechanism, Continuous Decomposition Fusion (CDeFuse), is proposed. Firstly, CDeFuse extends the original three-part decomposition to a more general K-part decomposition at each scale through similarity constraints to fuse multi-scale information and achieve a finer representation of decomposition features. Secondly, a Continuous Decomposition Module (CDM) is introduced to assist K-part decomposition. Its core component, State Transformer (ST), efficiently captures complementary information between modalities by utilizing multi-head self-attention mechanism. Finally, a novel decomposition loss function and the corresponding computational optimization strategy are utilized to ensure the smooth progress of the decomposition process while maintaining linear growth in time complexity with the number of decomposition results K. Extensive experiments demonstrate that our CDeFuse achieves comparable performance compared to previous methods. The code will be publicly available.
CoMoFusion: Fast and High-quality Fusion of Infrared and Visible Image with Consistency Model
May 31, 2024Generative models are widely utilized to model the distribution of fused images in the field of infrared and visible image fusion. However, current generative models based fusion methods often suffer from unstable training and slow inference speed. To tackle this problem, a novel fusion method based on consistency model is proposed, termed as CoMoFusion, which can generate the high-quality images and achieve fast image inference speed. In specific, the consistency model is used to construct multi-modal joint features in the latent space with the forward and reverse process. Then, the infrared and visible features extracted by the trained consistency model are fed into fusion module to generate the final fused image. In order to enhance the texture and salient information of fused images, a novel loss based on pixel value selection is also designed. Extensive experiments on public datasets illustrate that our method obtains the SOTA fusion performance compared with the existing fusion methods.
WavePF: A Novel Fusion Approach based on Wavelet-guided Pooling for Infrared and Visible Images
May 27, 2023



Infrared and visible image fusion aims to generate synthetic images simultaneously containing salient features and rich texture details, which can be used to boost downstream tasks. However, existing fusion methods are suffering from the issues of texture loss and edge information deficiency, which result in suboptimal fusion results. Meanwhile, the straight-forward up-sampling operator can not well preserve the source information from multi-scale features. To address these issues, a novel fusion network based on the wavelet-guided pooling (wave-pooling) manner is proposed, termed as WavePF. Specifically, a wave-pooling based encoder is designed to extract multi-scale image and detail features of source images at the same time. In addition, the spatial attention model is used to aggregate these salient features. After that, the fused features will be reconstructed by the decoder, in which the up-sampling operator is replaced by the wave-pooling reversed operation. Different from the common max-pooling technique, image features after the wave-pooling layer can retain abundant details information, which can benefit the fusion process. In this case, rich texture details and multi-scale information can be maintained during the reconstruction phase. The experimental results demonstrate that our method exhibits superior fusion performance over the state-of-the-arts on multiple image fusion benchmarks