 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Apr 16, 2026This paper presents an overview of the NTIRE 2026 Challenge on Video Saliency Prediction. The goal of the challenge participants was to develop automatic saliency map prediction methods for the provided video sequences. The novel dataset of 2,000 diverse videos with an open license was prepared for this challenge. The fixations and corresponding saliency maps were collected using crowdsourced mouse tracking and contain viewing data from over 5,000 assessors. Evaluation was performed on a subset of 800 test videos using generally accepted quality metrics. The challenge attracted over 20 teams making submissions, and 7 teams passed the final phase with code review. All data used in this challenge is made publicly available - https://github.com/msu-video-group/NTIRE26_Saliency_Prediction.
AI-MASLD Metabolic Dysfunction and Information Steatosis of Large Language Models in Unstructured Clinical Narratives
Dec 12, 2025This study aims to simulate real-world clinical scenarios to systematically evaluate the ability of Large Language Models (LLMs) to extract core medical information from patient chief complaints laden with noise and redundancy, and to verify whether they exhibit a functional decline analogous to Metabolic Dysfunction-Associated Steatotic Liver Disease (MASLD). We employed a cross-sectional analysis design based on standardized medical probes, selecting four mainstream LLMs as research subjects: GPT-4o, Gemini 2.5, DeepSeek 3.1, and Qwen3-Max. An evaluation system comprising twenty medical probes across five core dimensions was used to simulate a genuine clinical communication environment. All probes had gold-standard answers defined by clinical experts and were assessed via a double-blind, inverse rating scale by two independent clinicians. The results show that all tested models exhibited functional defects to varying degrees, with Qwen3-Max demonstrating the best overall performance and Gemini 2.5 the worst. Under conditions of extreme noise, most models experienced a functional collapse. Notably, GPT-4o made a severe misjudgment in the risk assessment for pulmonary embolism (PE) secondary to deep vein thrombosis (DVT). This research is the first to empirically confirm that LLMs exhibit features resembling metabolic dysfunction when processing clinical information, proposing the innovative concept of "AI-Metabolic Dysfunction-Associated Steatotic Liver Disease (AI-MASLD)". These findings offer a crucial safety warning for the application of Artificial Intelligence (AI) in healthcare, emphasizing that current LLMs must be used as auxiliary tools under human expert supervision, as there remains a significant gap between their theoretical knowledge and practical clinical application.
RETuning: Upgrading Inference-Time Scaling for Stock Movement Prediction with Large Language Models
Oct 24, 2025Recently, large language models (LLMs) have demonstrated outstanding reasoning capabilities on mathematical and coding tasks. However, their application to financial tasks-especially the most fundamental task of stock movement prediction-remains underexplored. We study a three-class classification problem (up, hold, down) and, by analyzing existing reasoning responses, observe that: (1) LLMs follow analysts' opinions rather than exhibit a systematic, independent analytical logic (CoTs). (2) LLMs list summaries from different sources without weighing adversarial evidence, yet such counterevidence is crucial for reliable prediction. It shows that the model does not make good use of its reasoning ability to complete the task. To address this, we propose Reflective Evidence Tuning (RETuning), a cold-start method prior to reinforcement learning, to enhance prediction ability. While generating CoT, RETuning encourages dynamically constructing an analytical framework from diverse information sources, organizing and scoring evidence for price up or down based on that framework-rather than on contextual viewpoints-and finally reflecting to derive the prediction. This approach maximally aligns the model with its learned analytical framework, ensuring independent logical reasoning and reducing undue influence from context. We also build a large-scale dataset spanning all of 2024 for 5,123 A-share stocks, with long contexts (32K tokens) and over 200K samples. In addition to price and news, it incorporates analysts' opinions, quantitative reports, fundamental data, macroeconomic indicators, and similar stocks. Experiments show that RETuning successfully unlocks the model's reasoning ability in the financial domain. Inference-time scaling still works even after 6 months or on out-of-distribution stocks, since the models gain valuable insights about stock movement prediction.
DecompGAIL: Learning Realistic Traffic Behaviors with Decomposed Multi-Agent Generative Adversarial Imitation Learning
Oct 08, 2025



Realistic traffic simulation is critical for the development of autonomous driving systems and urban mobility planning, yet existing imitation learning approaches often fail to model realistic traffic behaviors. Behavior cloning suffers from covariate shift, while Generative Adversarial Imitation Learning (GAIL) is notoriously unstable in multi-agent settings. We identify a key source of this instability: irrelevant interaction misguidance, where a discriminator penalizes an ego vehicle's realistic behavior due to unrealistic interactions among its neighbors. To address this, we propose Decomposed Multi-agent GAIL (DecompGAIL), which explicitly decomposes realism into ego-map and ego-neighbor components, filtering out misleading neighbor: neighbor and neighbor: map interactions. We further introduce a social PPO objective that augments ego rewards with distance-weighted neighborhood rewards, encouraging overall realism across agents. Integrated into a lightweight SMART-based backbone, DecompGAIL achieves state-of-the-art performance on the WOMD Sim Agents 2025 benchmark.
GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation
Sep 26, 2025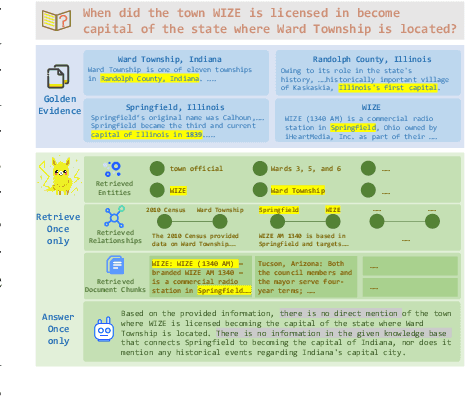
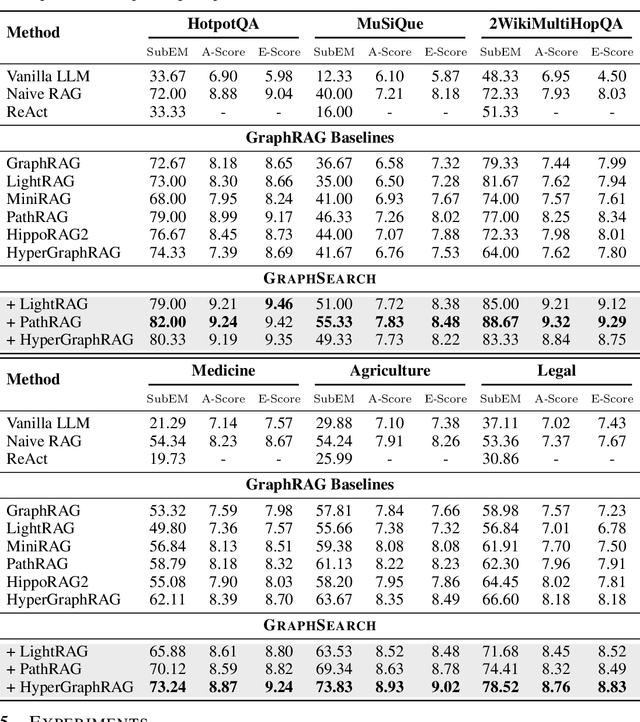

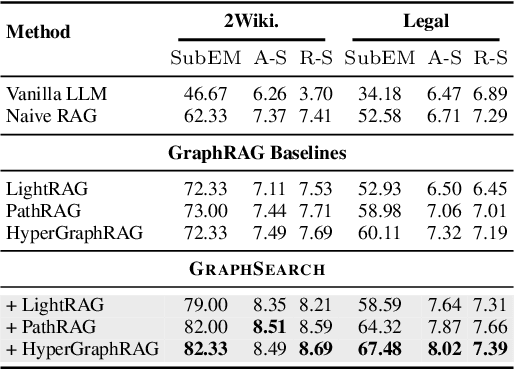
Graph Retrieval-Augmented Generation (GraphRAG) enhances factual reasoning in LLMs by structurally modeling knowledge through graph-based representations. However, existing GraphRAG approaches face two core limitations: shallow retrieval that fails to surface all critical evidence, and inefficient utilization of pre-constructed structural graph data, which hinders effective reasoning from complex queries. To address these challenges, we propose \textsc{GraphSearch}, a novel agentic deep searching workflow with dual-channel retrieval for GraphRAG. \textsc{GraphSearch} organizes the retrieval process into a modular framework comprising six modules, enabling multi-turn interactions and iterative reasoning. Furthermore, \textsc{GraphSearch} adopts a dual-channel retrieval strategy that issues semantic queries over chunk-based text data and relational queries over structural graph data, enabling comprehensive utilization of both modalities and their complementary strengths. Experimental results across six multi-hop RAG benchmarks demonstrate that \textsc{GraphSearch} consistently improves answer accuracy and generation quality over the traditional strategy, confirming \textsc{GraphSearch} as a promising direction for advancing graph retrieval-augmented generation.
CCrepairBench: A High-Fidelity Benchmark and Reinforcement Learning Framework for C++ Compilation Repair
Sep 19, 2025



The automated repair of C++ compilation errors presents a significant challenge, the resolution of which is critical for developer productivity. Progress in this domain is constrained by two primary factors: the scarcity of large-scale, high-fidelity datasets and the limitations of conventional supervised methods, which often fail to generate semantically correct patches.This paper addresses these gaps by introducing a comprehensive framework with three core contributions. First, we present CCrepair, a novel, large-scale C++ compilation error dataset constructed through a sophisticated generate-and-verify pipeline. Second, we propose a Reinforcement Learning (RL) paradigm guided by a hybrid reward signal, shifting the focus from mere compilability to the semantic quality of the fix. Finally, we establish the robust, two-stage evaluation system providing this signal, centered on an LLM-as-a-Judge whose reliability has been rigorously validated against the collective judgments of a panel of human experts. This integrated approach aligns the training objective with generating high-quality, non-trivial patches that are both syntactically and semantically correct. The effectiveness of our approach was demonstrated experimentally. Our RL-trained Qwen2.5-1.5B-Instruct model achieved performance comparable to a Qwen2.5-14B-Instruct model, validating the efficiency of our training paradigm. Our work provides the research community with a valuable new dataset and a more effective paradigm for training and evaluating robust compilation repair models, paving the way for more practical and reliable automated programming assistants.
Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning
Aug 13, 2025Large language models (LLMs) demonstrate remarkable reasoning capabilities in tasks such as algorithmic coding and mathematical problem-solving. Recent methods have improved reasoning through expanded corpus and multistage training combining reinforcement learning and supervised fine-tuning. Although some methods suggest that small but targeted dataset can incentivize reasoning via only distillation, a reasoning scaling laws is still taking shape, increasing computational costs. To address this, we propose a data-efficient distillation framework (DED) that optimizes the Pareto frontier of reasoning distillation. Inspired by the on-policy learning and diverse roll-out strategies of reinforcement learning, the key idea of our approach is threefold: (1) We identify that benchmark scores alone do not determine an effective teacher model. Through comprehensive comparisons of leading reasoning LLMs, we develop a method to select an optimal teacher model. (2) While scaling distillation can enhance reasoning, it often degrades out-of-domain performance. A carefully curated, smaller corpus achieves a balanced trade-off between in-domain and out-of-domain capabilities. (3) Diverse reasoning trajectories encourage the student model to develop robust reasoning skills. We validate our method through evaluations on mathematical reasoning (AIME 2024/2025, MATH-500) and code generation (LiveCodeBench), achieving state-of-the-art results with only 0.8k carefully curated examples, bypassing the need for extensive scaling. Our systematic analysis demonstrates that DED outperforms existing methods by considering factors beyond superficial hardness, token length, or teacher model capability. This work offers a practical and efficient pathway to advanced reasoning while preserving general capabilities.
Hybrid Batch Normalisation: Resolving the Dilemma of Batch Normalisation in Federated Learning
May 28, 2025Batch Normalisation (BN) is widely used in conventional deep neural network training to harmonise the input-output distributions for each batch of data. However, federated learning, a distributed learning paradigm, faces the challenge of dealing with non-independent and identically distributed data among the client nodes. Due to the lack of a coherent methodology for updating BN statistical parameters, standard BN degrades the federated learning performance. To this end, it is urgent to explore an alternative normalisation solution for federated learning. In this work, we resolve the dilemma of the BN layer in federated learning by developing a customised normalisation approach, Hybrid Batch Normalisation (HBN). HBN separates the update of statistical parameters (i.e. , means and variances used for evaluation) from that of learnable parameters (i.e. , parameters that require gradient updates), obtaining unbiased estimates of global statistical parameters in distributed scenarios. In contrast with the existing solutions, we emphasise the supportive power of global statistics for federated learning. The HBN layer introduces a learnable hybrid distribution factor, allowing each computing node to adaptively mix the statistical parameters of the current batch with the global statistics. Our HBN can serve as a powerful plugin to advance federated learning performance. It reflects promising merits across a wide range of federated learning settings, especially for small batch sizes and heterogeneous data.
Select2Reason: Efficient Instruction-Tuning Data Selection for Long-CoT Reasoning
May 22, 2025A practical approach to activate long chain-of-thoughts reasoning ability in pre-trained large language models is to perform supervised fine-tuning on instruction datasets synthesized by strong Large Reasoning Models such as DeepSeek-R1, offering a cost-effective alternative to reinforcement learning. However, large-scale instruction sets with more than 100k samples incur significant training overhead, while effective strategies for automatic long-CoT instruction selection still remain unexplored. In this work, we propose Select2Reason, a novel and efficient instruction-tuning data selection framework for long-CoT reasoning. From the perspective of emergence of rethinking behaviors like self-correction and backtracking, we investigate common metrics that may determine the quality of long-CoT reasoning instructions. Select2Reason leverages a quantifier to estimate difficulty of question and jointly incorporates a reasoning trace length-based heuristic through a weighted scheme for ranking to prioritize high-utility examples. Empirical results on OpenR1-Math-220k demonstrate that fine-tuning LLM on only 10% of the data selected by Select2Reason achieves performance competitive with or superior to full-data tuning and open-source baseline OpenR1-Qwen-7B across three competition-level and six comprehensive mathematical benchmarks. Further experiments highlight the scalability in varying data size, efficiency during inference, and its adaptability to other instruction pools with minimal cost.
iPad: Iterative Proposal-centric End-to-End Autonomous Driving
May 21, 2025End-to-end (E2E) autonomous driving systems offer a promising alternative to traditional modular pipelines by reducing information loss and error accumulation, with significant potential to enhance both mobility and safety. However, most existing E2E approaches directly generate plans based on dense bird's-eye view (BEV) grid features, leading to inefficiency and limited planning awareness. To address these limitations, we propose iterative Proposal-centric autonomous driving (iPad), a novel framework that places proposals - a set of candidate future plans - at the center of feature extraction and auxiliary tasks. Central to iPad is ProFormer, a BEV encoder that iteratively refines proposals and their associated features through proposal-anchored attention, effectively fusing multi-view image data. Additionally, we introduce two lightweight, proposal-centric auxiliary tasks - mapping and prediction - that improve planning quality with minimal computational overhead. Extensive experiments on the NAVSIM and CARLA Bench2Drive benchmarks demonstrate that iPad achieves state-of-the-art performance while being significantly more efficient than prior leading methods.