 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompGAIL: Learning Realistic Traffic Behaviors with Decomposed Multi-Agent Generative Adversarial Imitation Learning
Oct 08, 2025



Realistic traffic simulation is critical for the development of autonomous driving systems and urban mobility planning, yet existing imitation learning approaches often fail to model realistic traffic behaviors. Behavior cloning suffers from covariate shift, while Generative Adversarial Imitation Learning (GAIL) is notoriously unstable in multi-agent settings. We identify a key source of this instability: irrelevant interaction misguidance, where a discriminator penalizes an ego vehicle's realistic behavior due to unrealistic interactions among its neighbors. To address this, we propose Decomposed Multi-agent GAIL (DecompGAIL), which explicitly decomposes realism into ego-map and ego-neighbor components, filtering out misleading neighbor: neighbor and neighbor: map interactions. We further introduce a social PPO objective that augments ego rewards with distance-weighted neighborhood rewards, encouraging overall realism across agents. Integrated into a lightweight SMART-based backbone, DecompGAIL achieves state-of-the-art performance on the WOMD Sim Agents 2025 benchmark.
KuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation
Aug 07, 2025
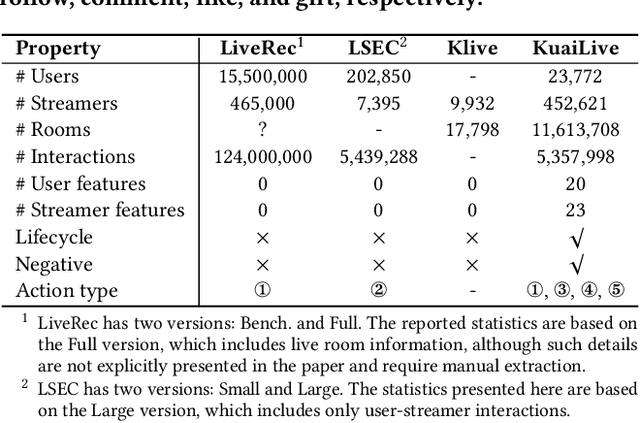

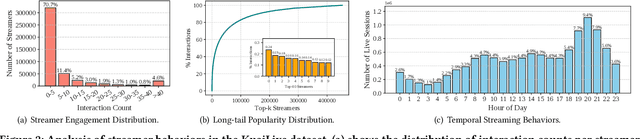
Live streaming platforms have become a dominant form of online content consumption, offering dynamically evolving content, real-time interactions, and highly engaging user experiences. These unique characteristics introduce new challenges that differentiate live streaming recommendation from traditional recommendation settings and have garnered increasing attention from industry in recent years. However, research progress in academia has been hindered by the lack of publicly available datasets that accurately reflect the dynamic nature of live streaming environments. To address this gap, we introduce KuaiLive, the first real-time, interactive dataset collected from Kuaishou, a leading live streaming platform in China with over 400 million daily active users. The dataset records the interaction logs of 23,772 users and 452,621 streamers over a 21-day period. Compared to existing datasets, KuaiLive offers several advantages: it includes precise live room start and end timestamps, multiple types of real-time user interactions (click, comment, like, gift), and rich side information features for both users and streamers. These features enable more realistic simulation of dynamic candidate items and better modeling of user and streamer behaviors. We conduct a thorough analysis of KuaiLive from multiple perspectives and evaluate several representative recommendation methods on it, establishing a strong benchmark for future research. KuaiLive can support a wide range of tasks in the live streaming domain, such as top-K recommendation, click-through rate prediction, watch time prediction, and gift price prediction. Moreover, its fine-grained behavioral data also enables research on multi-behavior modeling, multi-task learning, and fairness-aware recommendation. The dataset and related resources are publicly available at https://imgkkk574.github.io/KuaiLive.
Reinforced Refinement with Self-Aware Expansion for End-to-End Autonomous Driving
Jun 11, 2025



End-to-end autonomous driving has emerged as a promising paradigm for directly mapping sensor inputs to planning maneuvers using learning-based modular integrations. However, existing imitation learning (IL)-based models suffer from generalization to hard cases, and a lack of corrective feedback loop under post-deployment. While reinforcement learning (RL) offers a potential solution to tackle hard cases with optimality, it is often hindered by overfitting to specific driving cases, resulting in catastrophic forgetting of generalizable knowledge and sample inefficiency. To overcome these challenges, we propose Reinforced Refinement with Self-aware Expansion (R2SE), a novel learning pipeline that constantly refines hard domain while keeping generalizable driving policy for model-agnostic end-to-end driving systems. Through reinforcement fine-tuning and policy expansion that facilitates continuous improvement, R2SE features three key components: 1) Generalist Pretraining with hard-case allocation trains a generalist imitation learning (IL) driving system while dynamically identifying failure-prone cases for targeted refinement; 2) Residual Reinforced Specialist Fine-tuning optimizes residual corrections using reinforcement learning (RL) to improve performance in hard case domain while preserving global driving knowledge; 3) Self-aware Adapter Expansion dynamically integrates specialist policies back into the generalist model, enhancing continuous performance improvement. Experimental results in closed-loop simulation and real-world datasets demonstrate improvements in generalization, safety, and long-horizon policy robustness over state-of-the-art E2E systems, highlighting the effectiveness of reinforce refinement for scalable autonomous driving.
iPad: Iterative Proposal-centric End-to-End Autonomous Driving
May 21, 2025End-to-end (E2E) autonomous driving systems offer a promising alternative to traditional modular pipelines by reducing information loss and error accumulation, with significant potential to enhance both mobility and safety. However, most existing E2E approaches directly generate plans based on dense bird's-eye view (BEV) grid features, leading to inefficiency and limited planning awareness. To address these limitations, we propose iterative Proposal-centric autonomous driving (iPad), a novel framework that places proposals - a set of candidate future plans - at the center of feature extraction and auxiliary tasks. Central to iPad is ProFormer, a BEV encoder that iteratively refines proposals and their associated features through proposal-anchored attention, effectively fusing multi-view image data. Additionally, we introduce two lightweight, proposal-centric auxiliary tasks - mapping and prediction - that improve planning quality with minimal computational overhead. Extensive experiments on the NAVSIM and CARLA Bench2Drive benchmarks demonstrate that iPad achieves state-of-the-art performance while being significantly more efficient than prior leading methods.
CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving
Feb 27, 2025Trajectory planning is vital for autonomous driving, ensuring safe and efficient navigation in complex environments. While recent learning-based methods, particularly reinforcement learning (RL), have shown promise in specific scenarios, RL planners struggle with training inefficiencies and managing large-scale, real-world driving scenarios. In this paper, we introduce \textbf{CarPlanner}, a \textbf{C}onsistent \textbf{a}uto-\textbf{r}egressive \textbf{Planner} that uses RL to generate multi-modal trajectories. The auto-regressive structure enables efficient large-scale RL training, while the incorporation of consistency ensures stable policy learning by maintaining coherent temporal consistency across time steps. Moreover, CarPlanner employs a generation-selection framework with an expert-guided reward function and an invariant-view module, simplifying RL training and enhancing policy performance. Extensive analysis demonstrates that our proposed RL framework effectively addresses the challenges of training efficiency and performance enhancement, positioning CarPlanner as a promising solution for trajectory planning in autonomous driving. To the best of our knowledge, we are the first to demonstrate that the RL-based planner can surpass both IL- and rule-based state-of-the-arts (SOTAs) on the challenging large-scale real-world dataset nuPlan. Our proposed CarPlanner surpasses RL-, IL-, and rule-based SOTA approaches within this demanding dataset.
LASIL: Learner-Aware Supervised Imitation Learning For Long-term Microscopic Traffic Simulation
Apr 08, 2024



Microscopic traffic simulation plays a crucial role in transportation engineering by providing insights into individual vehicle behavior and overall traffic flow. However, creating a realistic simulator that accurately replicates human driving behaviors in various traffic conditions presents significant challenges. Traditional simulators relying on heuristic models often fail to deliver accurate simulations due to the complexity of real-world traffic environments. Due to the covariate shift issue, existing imitation learning-based simulators often fail to generate stable long-term simulations. In this paper, we propose a novel approach called learner-aware supervised imitation learning to address the covariate shift problem in multi-agent imitation learning. By leveraging a variational autoencoder simultaneously modeling the expert and learner state distribution, our approach augments expert states such that the augmented state is aware of learner state distribution. Our method, applied to urban traffic simulation, demonstrates significant improvements over existing state-of-the-art baselines in both short-term microscopic and long-term macroscopic realism when evaluated on the real-world dataset pNEUMA.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Long-term Microscopic Traffic Simulation with History-Masked Multi-agent Imitation Learning
Jun 10, 2023



A realistic long-term microscopic traffic simulator is necessary for understanding how microscopic changes affect traffic patterns at a larger scale. Traditional simulators that model human driving behavior with heuristic rules often fail to achieve accurate simulations due to real-world traffic complexity. To overcome this challenge, researchers have turned to neural networks, which are trained through imitation learning from human driver demonstrations. However, existing learning-based microscopic simulators often fail to generate stable long-term simulations due to the \textit{covariate shift} issue. To address this, we propose a history-masked multi-agent imitation learning method that removes all vehicles' historical trajectory information and applies perturbation to their current positions during learning. We apply our approach specifically to the urban traffic simulation problem and evaluate it on the real-world large-scale pNEUMA dataset, achieving better short-term microscopic and long-term macroscopic similarity to real-world data than state-of-the-art baselines.
CCIL: Context-conditioned imitation learning for urban driving
May 04, 2023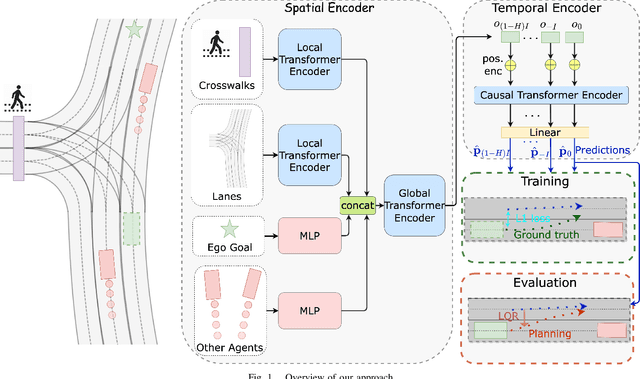
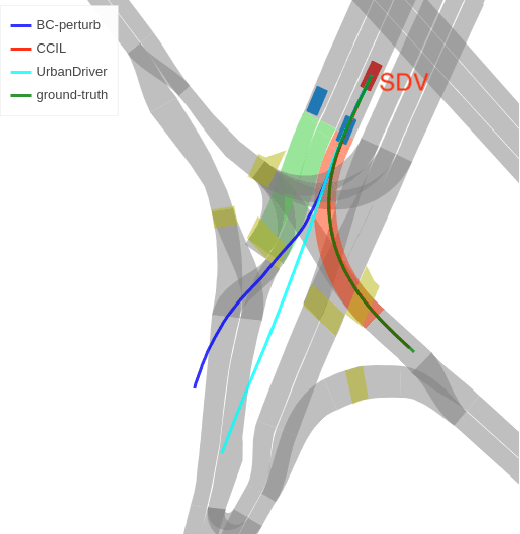
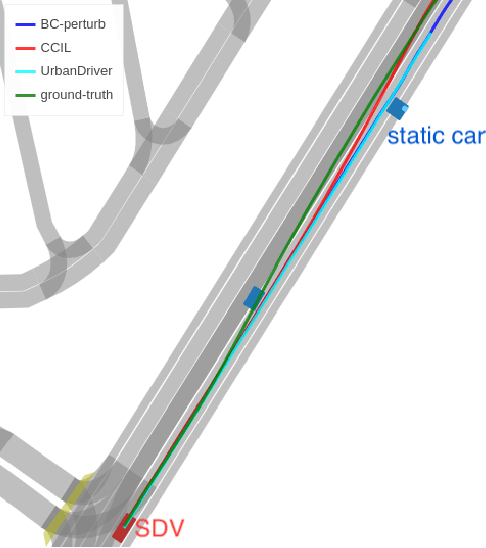
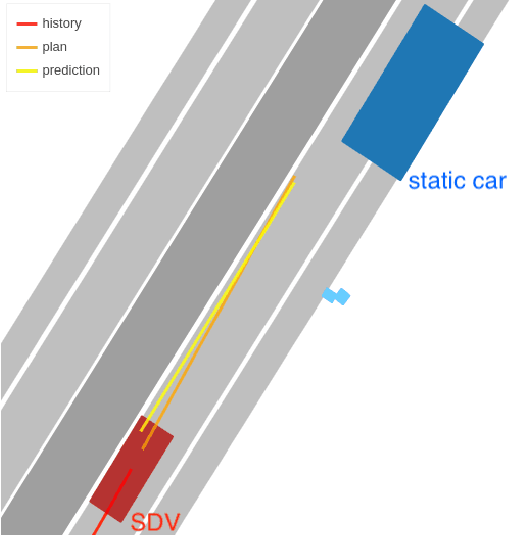
Imitation learning holds great promise for addressing the complex task of autonomous urban driving, as experienced human drivers can navigate highly challenging scenarios with ease. While behavior cloning is a widely used imitation learning approach in autonomous driving due to its exemption from risky online interactions, it suffers from the covariate shift issue. To address this limitation, we propose a context-conditioned imitation learning approach that employs a policy to map the context state into the ego vehicle's future trajectory, rather than relying on the traditional formulation of both ego and context states to predict the ego action. Additionally, to reduce the implicit ego information in the coordinate system, we design an ego-perturbed goal-oriented coordinate system. The origin of this coordinate system is the ego vehicle's position plus a zero mean Gaussian perturbation, and the x-axis direction points towards its goal position. Our experiments on the real-world large-scale Lyft and nuPlan datasets show that our method significantly outperforms state-of-the-art approaches.
End-to-End Trajectory Distribution Prediction Based on Occupancy Grid Maps
Mar 31, 2022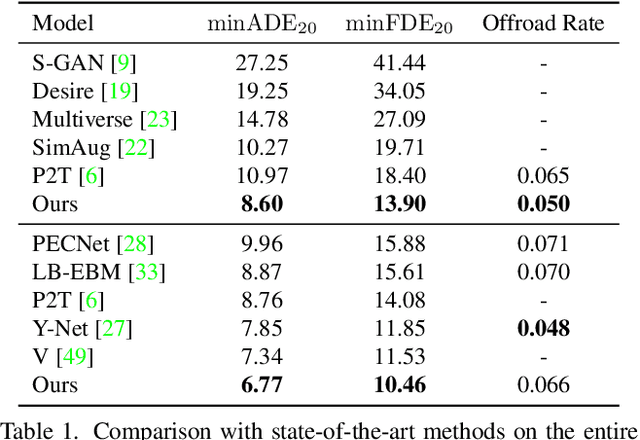
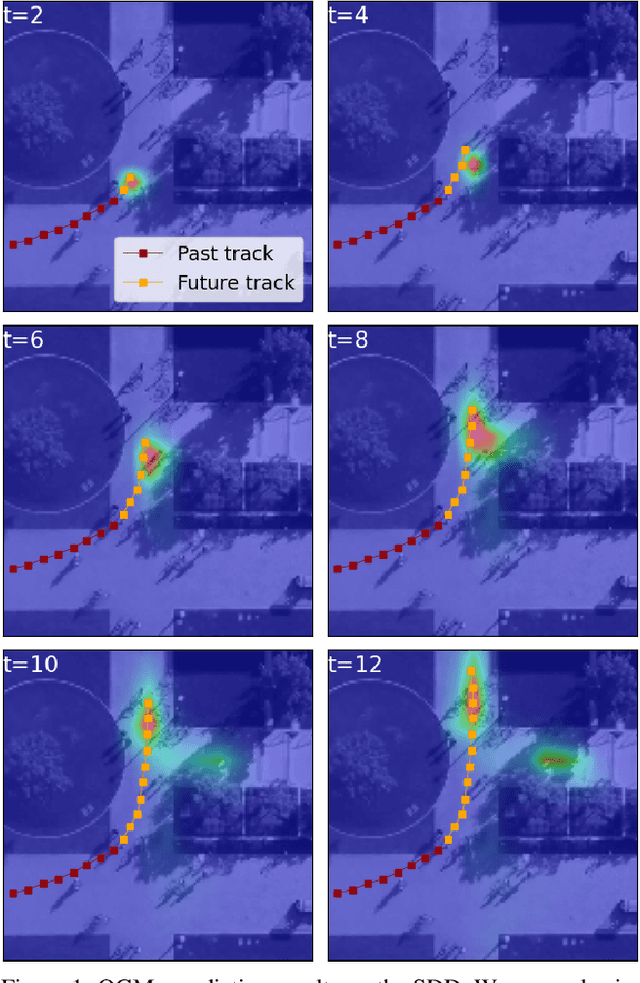
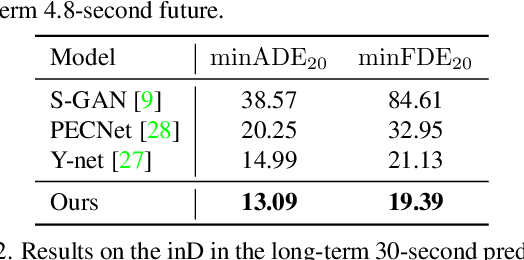
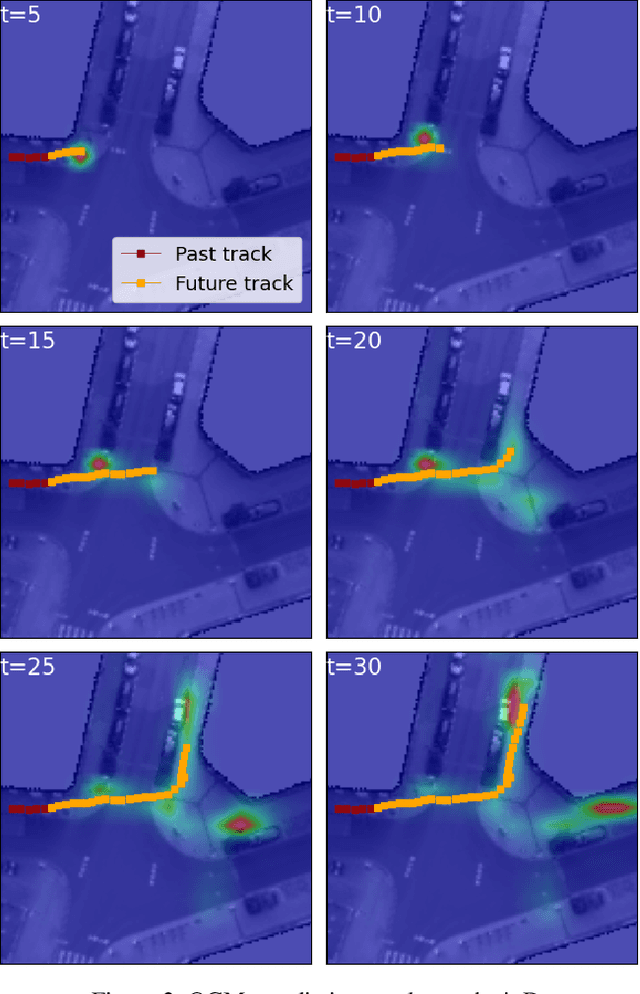
In this paper, we aim to forecast a future trajectory distribution of a moving agent in the real world, given the social scene images and historical trajectories. Yet, it is a challenging task because the ground-truth distribution is unknown and unobservable, while only one of its samples can be applied for supervising model learning, which is prone to bias. Most recent works focus on predicting diverse trajectories in order to cover all modes of the real distribution, but they may despise the precision and thus give too much credit to unrealistic predictions. To address the issue, we learn the distribution with symmetric cross-entropy using occupancy grid maps as an explicit and scene-compliant approximation to the ground-truth distribution, which can effectively penalize unlikely predictions. In specific, we present an inverse reinforcement learning based multi-modal trajectory distribution forecasting framework that learns to plan by an approximate value iteration network in an end-to-end manner. Besides, based on the predicted distribution, we generate a small set of representative trajectories through a differentiable Transformer-based network, whose attention mechanism helps to model the relations of trajectories. In experiments, our method achieves state-of-the-art performance on the Stanford Drone Dataset and Intersection Drone Dataset.