 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving
Feb 27, 2025Trajectory planning is vital for autonomous driving, ensuring safe and efficient navigation in complex environments. While recent learning-based methods, particularly reinforcement learning (RL), have shown promise in specific scenarios, RL planners struggle with training inefficiencies and managing large-scale, real-world driving scenarios. In this paper, we introduce \textbf{CarPlanner}, a \textbf{C}onsistent \textbf{a}uto-\textbf{r}egressive \textbf{Planner} that uses RL to generate multi-modal trajectories. The auto-regressive structure enables efficient large-scale RL training, while the incorporation of consistency ensures stable policy learning by maintaining coherent temporal consistency across time steps. Moreover, CarPlanner employs a generation-selection framework with an expert-guided reward function and an invariant-view module, simplifying RL training and enhancing policy performance. Extensive analysis demonstrates that our proposed RL framework effectively addresses the challenges of training efficiency and performance enhancement, positioning CarPlanner as a promising solution for trajectory planning in autonomous driving. To the best of our knowledge, we are the first to demonstrate that the RL-based planner can surpass both IL- and rule-based state-of-the-arts (SOTAs) on the challenging large-scale real-world dataset nuPlan. Our proposed CarPlanner surpasses RL-, IL-, and rule-based SOTA approaches within this demanding dataset.
LASIL: Learner-Aware Supervised Imitation Learning For Long-term Microscopic Traffic Simulation
Apr 08, 2024



Microscopic traffic simulation plays a crucial role in transportation engineering by providing insights into individual vehicle behavior and overall traffic flow. However, creating a realistic simulator that accurately replicates human driving behaviors in various traffic conditions presents significant challenges. Traditional simulators relying on heuristic models often fail to deliver accurate simulations due to the complexity of real-world traffic environments. Due to the covariate shift issue, existing imitation learning-based simulators often fail to generate stable long-term simulations. In this paper, we propose a novel approach called learner-aware supervised imitation learning to address the covariate shift problem in multi-agent imitation learning. By leveraging a variational autoencoder simultaneously modeling the expert and learner state distribution, our approach augments expert states such that the augmented state is aware of learner state distribution. Our method, applied to urban traffic simulation, demonstrates significant improvements over existing state-of-the-art baselines in both short-term microscopic and long-term macroscopic realism when evaluated on the real-world dataset pNEUMA.
PUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022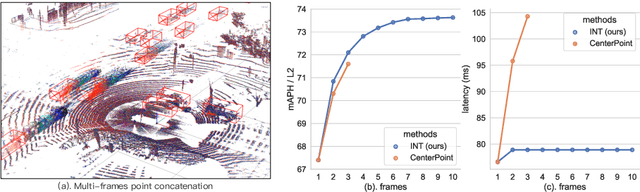
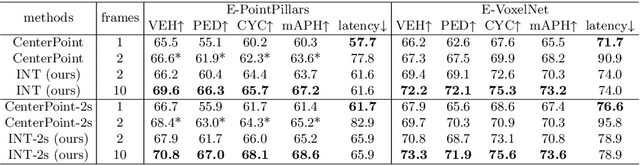
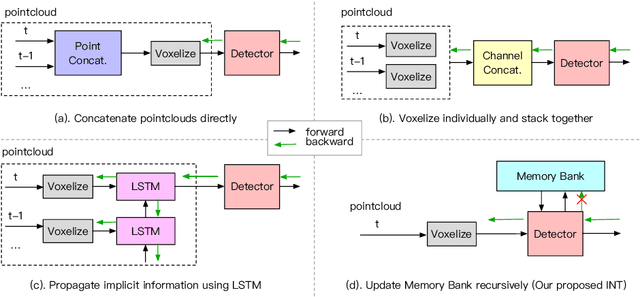
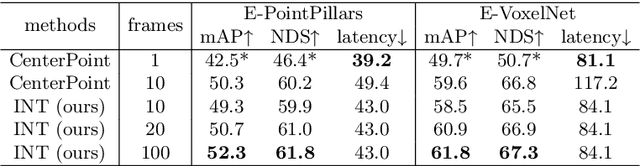
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.
DeepInteraction: 3D Object Detection via Modality Interaction
Aug 24, 2022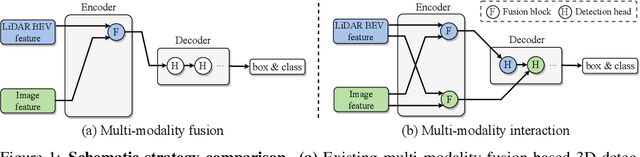



Existing top-performance 3D object detectors typically rely on the multi-modal fusion strategy. This design is however fundamentally restricted due to overlooking the modality-specific useful information and finally hampering the model performance. To address this limitation, in this work we introduce a novel modality interaction strategy where individual per-modality representations are learned and maintained throughout for enabling their unique characteristics to be exploited during object detection. To realize this proposed strategy, we design a DeepInteraction architecture characterized by a multi-modal representational interaction encoder and a multi-modal predictive interaction decoder. Experiments on the large-scale nuScenes dataset show that our proposed method surpasses all prior arts often by a large margin. Crucially, our method is ranked at the first position at the highly competitive nuScenes object detection leaderboard.
PolarFormer: Multi-camera 3D Object Detection with Polar Transformers
Jul 12, 2022
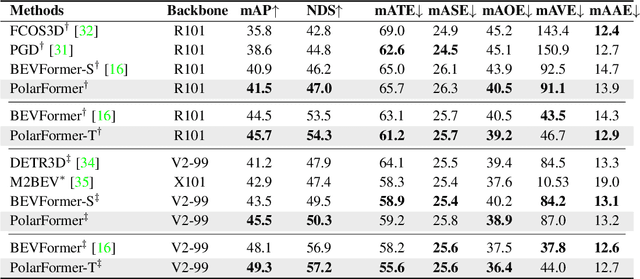
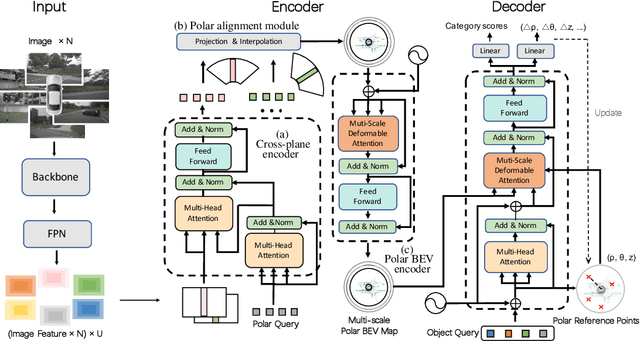
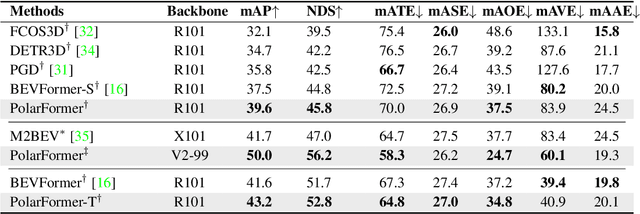
3D object detection in autonomous driving aims to reason "what" and "where" the objects of interest present in a 3D world. Following the conventional wisdom of previous 2D object detection, existing methods often adopt the canonical Cartesian coordinate system with perpendicular axis. However, we conjugate that this does not fit the nature of the ego car's perspective, as each onboard camera perceives the world in shape of wedge intrinsic to the imaging geometry with radical (non-perpendicular) axis. Hence, in this paper we advocate the exploitation of the Polar coordinate system and propose a new Polar Transformer (PolarFormer) for more accurate 3D object detection in the bird's-eye-view (BEV) taking as input only multi-camera 2D images. Specifically, we design a cross attention based Polar detection head without restriction to the shape of input structure to deal with irregular Polar grids. For tackling the unconstrained object scale variations along Polar's distance dimension, we further introduce a multi-scalePolar representation learning strategy. As a result, our model can make best use of the Polar representation rasterized via attending to the corresponding image observation in a sequence-to-sequence fashion subject to the geometric constraints. Thorough experiments on the nuScenes dataset demonstrate that our PolarFormer outperforms significantly state-of-the-art 3D object detection alternatives, as well as yielding competitive performance on BEV semantic segmentation task.
Interest Point Detection based on Adaptive Ternary Coding
Dec 31, 2018
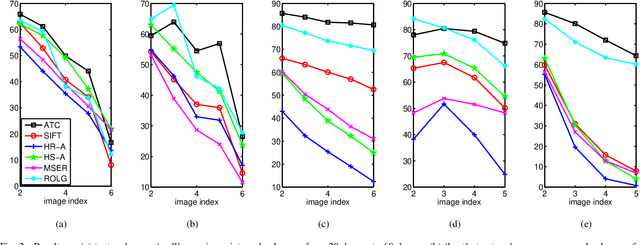


In this paper, an adaptive pixel ternary coding mechanism is proposed and a contrast invariant and noise resistant interest point detector is developed on the basis of this mechanism. Every pixel in a local region is adaptively encoded into one of the three statuses: bright, uncertain and dark. The blob significance of the local region is measured by the spatial distribution of the bright and dark pixels. Interest points are extracted from this blob significance measurement. By labeling the statuses of ternary bright, uncertain, and dark, the proposed detector shows more robustness to image noise and quantization errors. Moreover, the adaptive strategy for the ternary cording, which relies on two thresholds that automatically converge to the median of the local region in measurement, enables this coding to be insensitive to the image local contrast. As a result, the proposed detector is invariant to illumination changes. The state-of-the-art results are achieved on the standard datasets, and also in the face recognition application.
DCI: Discriminative and Contrast Invertible Descriptor
Dec 31, 2018
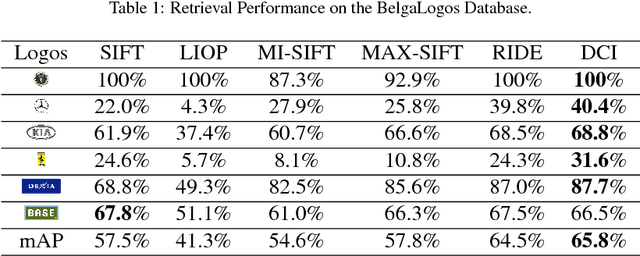


Local feature descriptors have been widely used in fine-grained visual object search thanks to their robustness in scale and rotation variation and cluttered background. However, the performance of such descriptors drops under severe illumination changes. In this paper, we proposed a Discriminative and Contrast Invertible (DCI) local feature descriptor. In order to increase the discriminative ability of the descriptor under illumination changes, a Laplace gradient based histogram is proposed. A robust contrast flipping estimate is proposed based on the divergence of a local region. Experiments on fine-grained object recognition and retrieval applications demonstrate the superior performance of DCI descriptor to others.