 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsisGuard: Aligning Safety Deliberation with Policy Enforcement in LLM Guardrails
May 29, 2026Reasoning-based LLM guardrails improve safety moderation by generating explicit rationales before issuing final decisions. However, their rationales do not always lead to faithful enforcement: a model may recognize a harmful intent in its reasoning but still predict a safe label, or issue an unsafe decision without policy-grounded justification. We identify this safety-critical failure mode as the deliberation-to-enforcement gap. Unlike general chain-of-thought faithfulness, guardrail reliability requires policy execution consistency: the generated reasoning should be grounded in the safety policy, and the final decision should be entailed by that reasoning. We propose ConsisGuard, a consistency-aware framework for reasoning-based LLM guardrails. ConsisGuard performs Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment, aligning the internal coupling between safety deliberation and decision enforcement. Experiments on prompt and response harmfulness detection benchmarks show that ConsisGuard improves detection performance while reducing policy execution failures. These results suggest that reliable reasoning-based guardrails require accurate faithful execution of safety policies.
Robust and Generalizable Safety Steering for Text-to-Image Diffusion Transformers
May 28, 2026Diffusion Transformers have become a powerful backbone for text-to-image generation, but their layered and cross-modal generation process makes safety control fundamentally different from prompt-level filtering or output-level detection. Harmful semantics may be weakly expressed in text representations, progressively bound to visual latents, and finally entangled with rendering dynamics. As a result, safety steering at a fixed layer can be unstable, and a steering mechanism learned from known risks may not transfer reliably to a shifted target risk domain. We propose SafeDIG, a safety steering framework that formulates DiT safety adaptation as position-aware sparse feature transfer. SafeDIG first constructs Sparse Autoencoders over functionally distinct DiT intervention positions and uses robustness-aware pre-training routing to prioritize intervention sites that are expected to remain stable under source-target risk shift. It then separates transferable safety features from domain-specific activation geometry by freezing the SAE encoder as a reusable sparse safety dictionary and adapting only the decoder to the target-domain activation manifold. During inference, SafeDIG combines Blend and Repel operations to steer unsafe activations toward transferred safety manifolds or away from harmful sparse directions. Experiments on FLUX.1 Dev and Stable Diffusion 3.5 Large show that SafeDIG consistently reduces target-domain and overall unsafe generation rates while preserving source-domain safety and image quality.
Make LLM Learn to Synthesize from Streaming Experiences through Feedback
May 28, 2026Large language models (LLMs) have been widely adopted for synthetic data generation, significantly reducing annotation costs. However, most existing studies treat synthesis as a set of isolated tasks and overlook a more fundamental question: whether a model can learn to synthesize by accumulating experience from past tasks and transferring it to future ones. In this work, we introduce StreamSynth, a new setting in which synthesis tasks arrive sequentially and experience from historical tasks provides informative signals for future synthesis. To address this setting, we propose SynLearner, a general framework that enables synthesis models to acquire reusable synthesis experience over a task stream. Instead of generating data independently for each task, SynLearner encourages the model to explore diverse synthesis patterns, learn from feedback, and balance sample quality with set-level diversity as tasks evolve. Extensive experiments across multiple benchmarks show that SynLearner effectively leverages experience from earlier tasks to improve synthesis performance on later ones, exhibiting consistent cross-task transferability. These findings provide evidence for the feasibility of StreamSynth and highlight synthetic data generation as an experience-driven process that can benefit from task streams.
Superintelligent Retrieval Agent: The Next Frontier of Information Retrieval
May 07, 2026Retrieval-augmented agents are increasingly the interface to large organizational knowledge bases, yet most still treat retrieval as a black box: they issue exploratory queries, inspect returned snippets, and iteratively reformulate until useful evidence emerges. This approach resembles how a newcomer searches an unfamiliar database rather than how an expert navigates it with strong priors about terminology and likely evidence, and results in unnecessary retrieval rounds, increased latency, and poor recall. We introduce \textit{SuperIntelligent Retrieval Agent} (SIRA), which defines \emph{superintelligence} in retrieval as the ability to compress multi-round exploratory search into a single corpus-discriminative retrieval action. SIRA does not merely ask what terms are relevant to the query; it asks which terms are likely to separate the desired evidence from corpus-level confusers. On the corpus side, an LLM enriches each document offline with missing search vocabulary; on the query side, it predicts evidence vocabulary omitted by the query; and document-frequency statistics as a tool call to filter proposed terms that are absent, overly common, or unlikely to create retrieval margin. The final retrieval step is a single weighted BM25 call combining the original query with the validated expansion. Across ten BEIR benchmarks and downstream question-answering tasks, SIRA achieves the significantly superior performance outperforming dense retrievers and state-of-the-art multi-round agentic baselines, demonstrating that one well-formed lexical query, guided by LLM cognition and lightweight corpus statistics, can exceed substantially more expensive multi-round search while remaining interpretable, training-free, and efficient.
Slack More, Predict Better: Proximal Relaxation for Probabilistic Latent Variable Model-based Soft Sensors
Mar 12, 2026Nonlinear Probabilistic Latent Variable Models (NPLVMs) are a cornerstone of soft sensor modeling due to their capacity for uncertainty delineation. However, conventional NPLVMs are trained using amortized variational inference, where neural networks parameterize the variational posterior. While facilitating model implementation, this parameterization converts the distributional optimization problem within an infinite-dimensional function space to parameter optimization within a finite-dimensional parameter space, which introduces an approximation error gap, thereby degrading soft sensor modeling accuracy. To alleviate this issue, we introduce KProxNPLVM, a novel NPLVM that pivots to relaxing the objective itself and improving the NPLVM's performance. Specifically, we first prove the approximation error induced by the conventional approach. Based on this, we design the Wasserstein distance as the proximal operator to relax the learning objective, yielding a new variational inference strategy derived from solving this relaxed optimization problem. Based on this foundation, we provide a rigorous derivation of KProxNPLVM's optimization implementation, prove the convergence of our algorithm can finally sidestep the approximation error, and propose the KProxNPLVM by summarizing the abovementioned content. Finally, extensive experiments on synthetic and real-world industrial datasets are conducted to demonstrate the efficacy of the proposed KProxNPLVM.
Scout Before You Attend: Sketch-and-Walk Sparse Attention for Efficient LLM Inference
Feb 07, 2026Self-attention dominates the computational and memory cost of long-context LLM inference across both prefill and decode phases. To address this challenge, we introduce Sketch&Walk Attention, a training-free sparse attention method that determines sparsity with lightweight sketches and deterministic walk. Sketch&Walk applies Hadamard sketching to get inexpensive approximations of attention scores, then aggregates these estimates across layers via a walk mechanism that captures attention influence beyond direct interactions between tokens. The accumulated walk scores are used to select top-k attention blocks, enabling dynamic sparsity with a single training-free algorithm that applies uniformly to both the prefill and decode phases, together with custom sparse attention kernels. Across a wide range of models and tasks, Sketch&Walk maintains near-lossless accuracy at 20% attention density and can slightly outperform dense attention in some settings, while achieving up to 6x inference speedup.
Redefining Machine Simultaneous Interpretation: From Incremental Translation to Human-Like Strategies
Jan 16, 2026Simultaneous Machine Translation (SiMT) requires high-quality translations under strict real-time constraints, which traditional policies with only READ/WRITE actions cannot fully address. We extend the action space of SiMT with four adaptive actions: Sentence_Cut, Drop, Partial_Summarization and Pronominalization, which enable real-time restructuring, omission, and simplification while preserving semantic fidelity. We adapt these actions in a large language model (LLM) framework and construct training references through action-aware prompting. To evaluate both quality and word-level monotonicity, we further develop a latency-aware TTS pipeline that maps textual outputs to speech with realistic timing. Experiments on the ACL60/60 English-Chinese, English-German and English-Japanese benchmarks show that our framework consistently improves semantic metrics and achieves lower delay compared to reference translations and salami-based baselines. Notably, combining Drop and Sentence_Cut leads to consistent improvements in the balance between fluency and latency. These results demonstrate that enriching the action space of LLM-based SiMT provides a promising direction for bridging the gap between human and machine interpretation.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
SASST: Leveraging Syntax-Aware Chunking and LLMs for Simultaneous Speech Translation
Aug 11, 2025This work proposes a grammar-based chunking strategy that segments input streams into semantically complete units by parsing dependency relations (e.g., noun phrase boundaries, verb-object structures) and punctuation features. The method ensures chunk coherence and minimizes semantic fragmentation. Building on this mechanism, we present SASST (Syntax-Aware Simultaneous Speech Translation), an end-to-end framework integrating frozen Whisper encoder and decoder-only LLM. The unified architecture dynamically outputs translation tokens or <WAIT> symbols to jointly optimize translation timing and content, with target-side reordering addressing word-order divergence. Experiments on CoVoST2 multilingual corpus En-{De, Zh, Ja} demonstrate significant translation quality improvements across languages and validate the effectiveness of syntactic structures in LLM-driven SimulST systems.
LiDARDustX: A LiDAR Dataset for Dusty Unstructured Road Environments
May 28, 2025

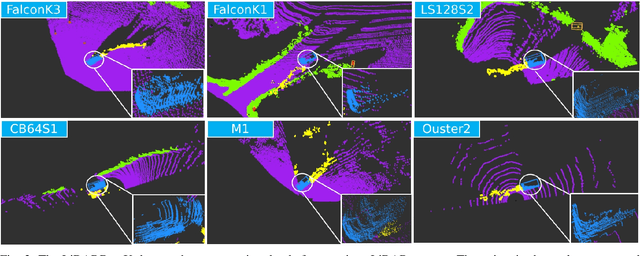

Autonomous driving datasets are essential for validating the progress of intelligent vehicle algorithms, which include localization, perception, and prediction. However, existing datasets are predominantly focused on structured urban environments, which limits the exploration of unstructured and specialized scenarios, particularly those characterized by significant dust levels. This paper introduces the LiDARDustX dataset, which is specifically designed for perception tasks under high-dust conditions, such as those encountered in mining areas. The LiDARDustX dataset consists of 30,000 LiDAR frames captured by six different LiDAR sensors, each accompanied by 3D bounding box annotations and point cloud semantic segmentation. Notably, over 80% of the dataset comprises dust-affected scenes. By utilizing this dataset, we have established a benchmark for evaluating the performance of state-of-the-art 3D detection and segmentation algorithms. Additionally, we have analyzed the impact of dust on perception accuracy and delved into the causes of these effects. The data and further information can be accessed at: https://github.com/vincentweikey/LiDARDustX.