 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Half-Frame-Rate Adaptive Learnable Operator for Lightweight STFT-Based Speech Enhancement
Jun 10, 2026STFT-based speech enhancement typically adopts overlapping analysis frames. While overlap is essential for stable STFT processing, it makes adjacent frames highly correlated, causing redundant computation in lightweight models. We propose Half-frame-rate Adaptive Learnable Operator (HALO), a causal plug-in module that halves the internal frame rate without altering the STFT procedure. Broadly applicable to many lightweight models, HALO applies adaptive rate reduction before the backbone and restoration afterward, reconstructing the full-rate spectrum on the original STFT grid. Both reduction and restoration are implemented with lightweight dynamic convolutions. By halving the processed frame rate, HALO reduces backbone compute cost with no added algorithmic latency, freeing budget for channel widening. Experiments on the DNS3 dataset show consistent gains across diverse lightweight models under matched complexity, demonstrating the effectiveness of reducing overlap-induced redundancy.
FSC-Net: Integrating Fast Fourier Convolutions and Progressive Learning for Speech Bandwidth Extension
Jun 05, 2026Speech bandwidth extension (BWE) aims to reconstruct high-fidelity wideband audio from narrowband inputs. While recent approaches have made significant progress, they often struggle to reconstruct realistic high-frequency phase and harmonic structures, leading to perceptual artifacts. In this paper, we propose FSC-Net (Full-Spectrum Context Network), a parameter-efficient architecture designed to explicitly model cross-band harmonic dependencies. By integrating Fast Fourier Convolutions (FFCs) into a complex spectral mapping framework, FSC-Net expands its receptive field to the entire spectrum, capturing long-range frequency interactions effectively. To address the ill-posed nature of high-frequency generation, our novel frequency-progressive learning curriculum guides the network to reconstruct spectral details from coarse to fine. Experimental results on the VCTK and unseen EARS datasets demonstrate that FSC-Net delivers consistently strong reconstruction quality and generalization, particularly in the challenging VCTK 4 kHz-to-48 kHz task. Compared to scaled-up baselines, our model attains leading LSD and PESQ scores while maintaining a highly compact parameter footprint (1.54 M).
Decoding Stimulus Reconstruction-Based Auditory Attention Robustly in Unbalanced EEG Datasets
May 25, 2026In the past decade, numerous studies have applied deep neural networks (DNNs) to decode auditory attention (AAD) from Electroencephalogram (EEG) signals via stimulus reconstruction. However, the influence of dataset balance on the decoding performance of stimulus reconstruction-based AAD remains unexplored. In this study, three publicly available EEG-AAD datasets - KUL, DTU, and NJU cEEGrid - are used to construct both balanced and unbalanced experimental conditions. We hypothesize and demonstrate that stimulus reconstruction-based DNN decoders tend to produce overestimated decoding performance on unbalanced datasets. To address this issue, we propose a leave-one-paired-envelope-out (LOPEO) cross-validation protocol. Experimental results confirm that LOPEO effectively prevents inflated decoding accuracy on unbalanced datasets. While balanced datasets are generally preferred in experimental design, LOPEO provides a principled evaluation framework for unbalanced datasets that have already been published, filling an important gap in the field.
UniPASE: A Generative Model for Universal Speech Enhancement with High Fidelity and Low Hallucinations
Apr 16, 2026Universal speech enhancement (USE) aims to restore speech signals from diverse distortions across multiple sampling rates. We propose UniPASE, an extension of the low-hallucination PASE framework tailored for USE. At its core is DeWavLM-Omni, a unified representation-level enhancement module fine-tuned from WavLM via knowledge distillation on a large-scale supervised multi-distortion dataset. This module directly converts degraded waveforms into clean and linguistically faithful phonetic representations, ensuring robust enhancement with minimal linguistic hallucination. Based on these enhanced phonetic representations, an Adapter generates enhanced acoustic representations containing rich acoustic details, which a neural Vocoder uses to reconstruct corresponding high-fidelity 16-kHz waveforms. A PostNet then converts the waveforms to 48~kHz before resampling them to their original rates, enabling seamless handling of inputs and outputs at multiple sampling rates. Experimental results on several evaluation datasets, covering sub-tasks and full tasks, demonstrate that UniPASE achieves superior or competitive performance compared with existing state-of-the-art models. The proposed model also serves as the backbone of our submission to the URGENT 2026 Challenge, which achieved 1st place in the objective evaluation. The source code and audio demos are available at https://github.com/xiaobin-rong/unipase/.
GAP-URGENet: A Generative-Predictive Fusion Framework for Universal Speech Enhancement
Apr 02, 2026We introduce GAP-URGENet, a generative-predictive fusion framework developed for Track 1 of the ICASSP 2026 URGENT Challenge. The system integrates a generative branch, which performs full-stack speech restoration in a self-supervised representation domain and reconstructs the waveform via a neural vocoder, along with a predictive branch that performs spectrogram-domain enhancement, providing complementary cues. Outputs from both branches are fused by a post-processing module, which also performs bandwidth extension to generate the enhanced waveform at 48 kHz, later downsampled to the original sampling rate. This generative-predictive fusion improves robustness and perceptual quality, achieving top performance in the blind-test phase and ranking 1st in the objective evaluation. Audio examples are available at https://xiaobin-rong.github.io/gap-urgenet_demo.
StuPASE: Towards Low-Hallucination Studio-Quality Generative Speech Enhancement
Mar 10, 2026Achieving high perceptual quality without hallucination remains a challenge in generative speech enhancement (SE). A representative approach, PASE, is robust to hallucination but has limited perceptual quality under adverse conditions. We propose StuPASE, built upon PASE to achieve studio-level quality while retaining its low-hallucination property. First, we show that finetuning PASE with dry targets rather than targets containing simulated early reflections substantially improves dereverberation. Second, to address performance limitations under strong additive noise, we replace the GAN-based generative module in PASE with a flow-matching module, enabling studio-quality generation even under highly challenging conditions. Experiments demonstrate that StuPASE consistently produces perceptually high-quality speech while maintaining low hallucination, outperforming state-of-the-art SE methods. Audio demos are available at: https://xiaobin-rong.github.io/stupase_demo/.
Decoding Speech Envelopes from Electroencephalogram with a Contrastive Pearson Correlation Coefficient Loss
Jan 29, 2026Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals have enabled continuous auditory attention decoding (AAD) in multi-speaker environments. Most Deep Neural Network (DNN)-based envelope reconstruction models are trained to maximize the Pearson correlation coefficients (PCC) between the attended envelope and the reconstructed envelope (attended PCC). While the difference between the attended PCC and the unattended PCC plays an essential role in auditory attention decoding, existing methods often focus on maximizing the attended PCC. We therefore propose a contrastive PCC loss which represents the difference between the attended PCC and the unattended PCC. The proposed approach is evaluated on three public EEG AAD datasets using four DNN architectures. Across many settings, the proposed objective improves envelope separability and AAD accuracy, while also revealing dataset- and architecture-dependent failure cases.
VoCodec: An Efficient Lightweight Low-Bitrate Speech Codec
Jan 19, 2026Recent advancements in end-to-end neural speech codecs enable compressing audio at extremely low bitrates while maintaining high-fidelity reconstruction. Meanwhile, low computational complexity and low latency are crucial for real-time communication. In this paper, we propose VoCodec, a speech codec model featuring a computational complexity of only 349.29M multiply-accumulate operations per second (MACs/s) and a latency of 30 ms. With the competitive vocoder Vocos as its backbone, the proposed model ranked fourth on Track 1 in the 2025 LRAC Challenge and achieved the highest subjective evaluation score (MUSHRA) on the clean speech test set. Additionally, we cascade a lightweight neural network at the front end to extend its capability of speech enhancement. Experimental results demonstrate that the two systems achieve competitive performance across multiple evaluation metrics. Speech samples can be found at https://acceleration123.github.io/.
SPECTRE: Spectral Pre-training Embeddings with Cylindrical Temporal Rotary Position Encoding for Fine-Grained sEMG-Based Movement Decoding
Dec 27, 2025Decoding fine-grained movement from non-invasive surface Electromyography (sEMG) is a challenge for prosthetic control due to signal non-stationarity and low signal-to-noise ratios. Generic self-supervised learning (SSL) frameworks often yield suboptimal results on sEMG as they attempt to reconstruct noisy raw signals and lack the inductive bias to model the cylindrical topology of electrode arrays. To overcome these limitations, we introduce SPECTRE, a domain-specific SSL framework. SPECTRE features two primary contributions: a physiologically-grounded pre-training task and a novel positional encoding. The pre-training involves masked prediction of discrete pseudo-labels from clustered Short-Time Fourier Transform (STFT) representations, compelling the model to learn robust, physiologically relevant frequency patterns. Additionally, our Cylindrical Rotary Position Embedding (CyRoPE) factorizes embeddings along linear temporal and annular spatial dimensions, explicitly modeling the forearm sensor topology to capture muscle synergies. Evaluations on multiple datasets, including challenging data from individuals with amputation, demonstrate that SPECTRE establishes a new state-of-the-art for movement decoding, significantly outperforming both supervised baselines and generic SSL approaches. Ablation studies validate the critical roles of both spectral pre-training and CyRoPE. SPECTRE provides a robust foundation for practical myoelectric interfaces capable of handling real-world sEMG complexities.
PASE: Leveraging the Phonological Prior of WavLM for Low-Hallucination Generative Speech Enhancement
Nov 17, 2025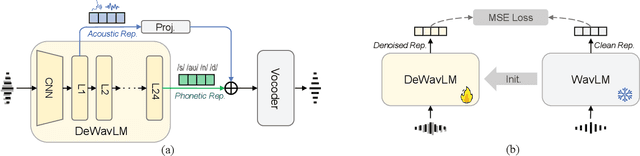
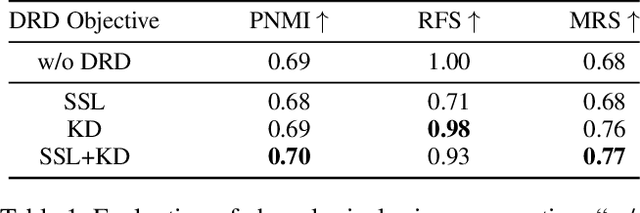
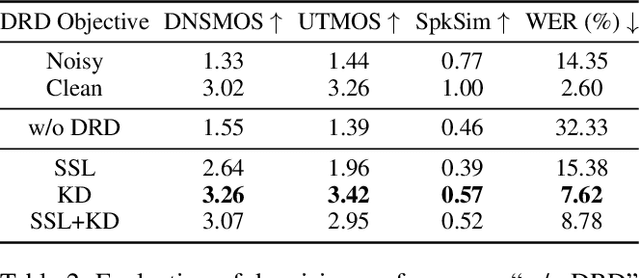
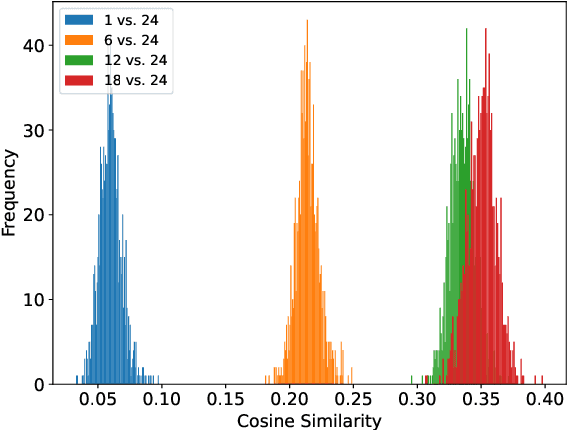
Generative models have shown remarkable performance in speech enhancement (SE), achieving superior perceptual quality over traditional discriminative approaches. However, existing generative SE approaches often overlook the risk of hallucination under severe noise, leading to incorrect spoken content or inconsistent speaker characteristics, which we term linguistic and acoustic hallucinations, respectively. We argue that linguistic hallucination stems from models' failure to constrain valid phonological structures and it is a more fundamental challenge. While language models (LMs) are well-suited for capturing the underlying speech structure through modeling the distribution of discrete tokens, existing approaches are limited in learning from noise-corrupted representations, which can lead to contaminated priors and hallucinations. To overcome these limitations, we propose the Phonologically Anchored Speech Enhancer (PASE), a generative SE framework that leverages the robust phonological prior embedded in the pre-trained WavLM model to mitigate hallucinations. First, we adapt WavLM into a denoising expert via representation distillation to clean its final-layer features. Guided by the model's intrinsic phonological prior, this process enables robust denoising while minimizing linguistic hallucinations. To further reduce acoustic hallucinations, we train the vocoder with a dual-stream representation: the high-level phonetic representation provides clean linguistic content, while a low-level acoustic representation retains speaker identity and prosody. Experimental results demonstrate that PASE not only surpasses state-of-the-art discriminative models in perceptual quality, but also significantly outperforms prior generative models with substantially lower linguistic and acoustic hallucinations.