 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA k-space approach to modeling multi-channel parametric array loudspeaker systems
Jul 30, 2025Multi-channel parametric array loudspeaker (MCPAL) systems offer enhanced flexibility and promise for generating highly directional audio beams in real-world applications. However, efficient and accurate prediction of their generated sound fields remains a major challenge due to the complex nonlinear behavior and multi-channel signal processing involved. To overcome this obstacle, we propose a k-space approach for modeling arbitrary MCPAL systems arranged on a baffled planar surface. In our method, the linear ultrasound field is first solved using the angular spectrum approach, and the quasilinear audio sound field is subsequently computed efficiently in k-space. By leveraging three-dimensional fast Fourier transforms, our approach not only achieves high computational and memory efficiency but also maintains accuracy without relying on the paraxial approximation. For typical configurations studied, the proposed method demonstrates a speed-up of more than four orders of magnitude compared to the direct integration method. Our proposed approach paved the way for simulating and designing advanced MCPAL systems.
Generating Localized Audible Zones Using a Single-Channel Parametric Loudspeaker
Apr 24, 2025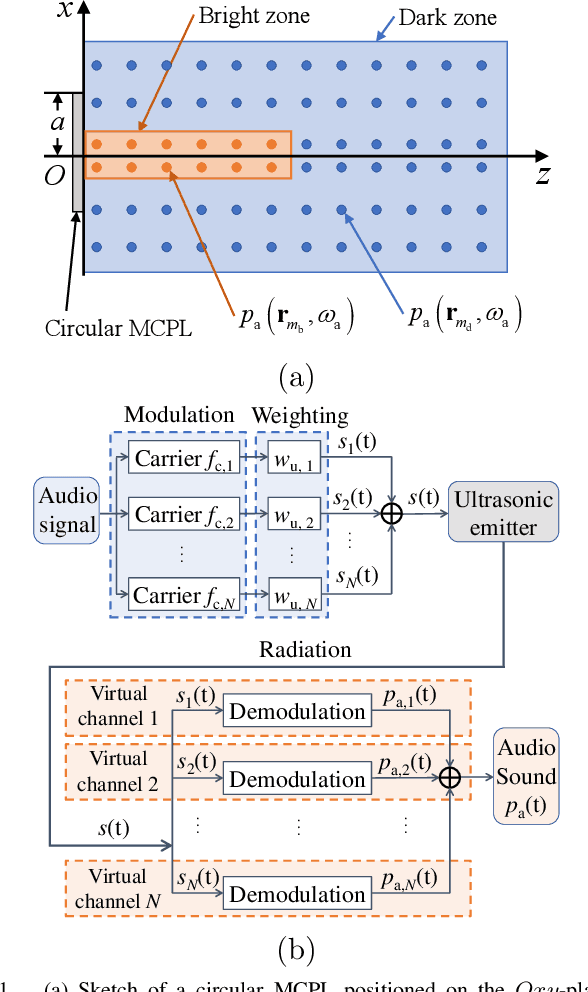
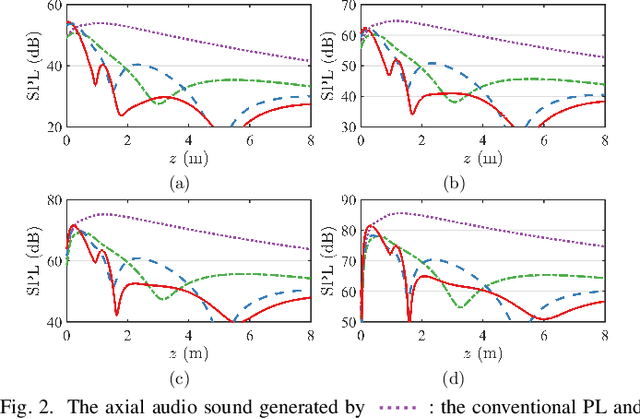
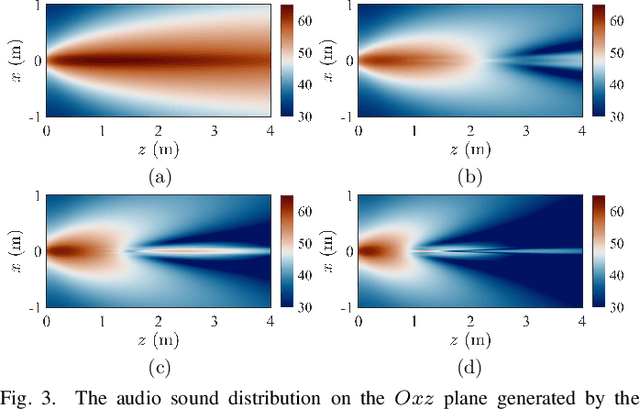
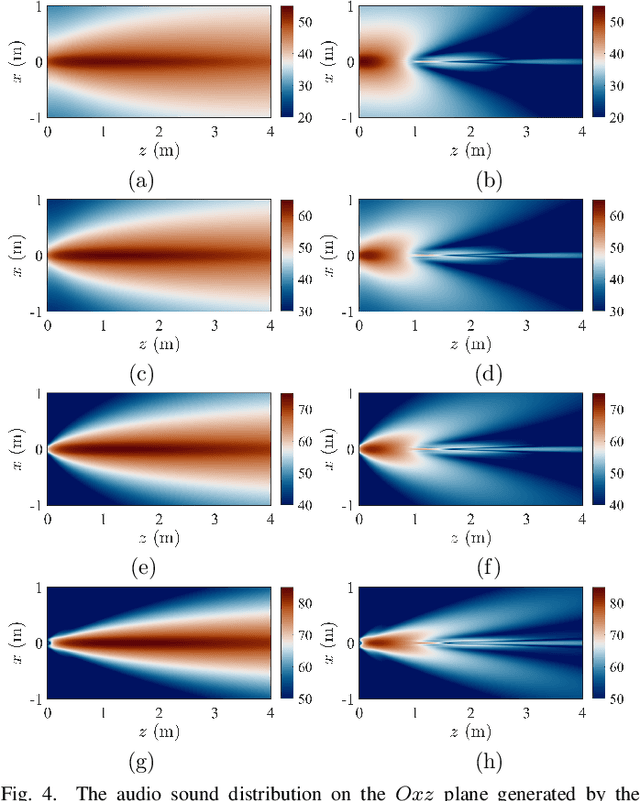
Advanced sound zone control (SZC) techniques typically rely on massive multi-channel loudspeaker arrays to create high-contrast personal sound zones, making single-loudspeaker SZC seem impossible. In this Letter, we challenge this paradigm by introducing the multi-carrier parametric loudspeaker (MCPL), which enables SZC using only a single loudspeaker. In our approach, distinct audio signals are modulated onto separate ultrasonic carrier waves at different frequencies and combined into a single composite signal. This signal is emitted by a single-channel ultrasonic transducer, and through nonlinear demodulation in air, the audio signals interact to virtually form multi-channel outputs. This novel capability allows the application of existing SZC algorithms originally designed for multi-channel loudspeaker arrays. Simulations validate the effectiveness of our proposed single-channel MCPL, demonstrating its potential as a promising alternative to traditional multi-loudspeaker systems for achieving high-contrast SZC. Our work opens new avenues for simplifying SZC systems without compromising performance.
Overton: A Data System for Monitoring and Improving Machine-Learned Products
Sep 07, 2019



We describe a system called Overton, whose main design goal is to support engineers in building, monitoring, and improving production machine learning systems. Key challenges engineers face are monitoring fine-grained quality, diagnosing errors in sophisticated applications, and handling contradictory or incomplete supervision data. Overton automates the life cycle of model construction, deployment, and monitoring by providing a set of novel high-level, declarative abstractions. Overton's vision is to shift developers to these higher-level tasks instead of lower-level machine learning tasks. In fact, using Overton, engineers can build deep-learning-based applications without writing any code in frameworks like TensorFlow. For over a year, Overton has been used in production to support multiple applications in both near-real-time applications and back-of-house processing. In that time, Overton-based applications have answered billions of queries in multiple languages and processed trillions of records reducing errors 1.7-2.9 times versus production systems.
Scaling Inference for Markov Logic with a Task-Decomposition Approach
Mar 12, 2012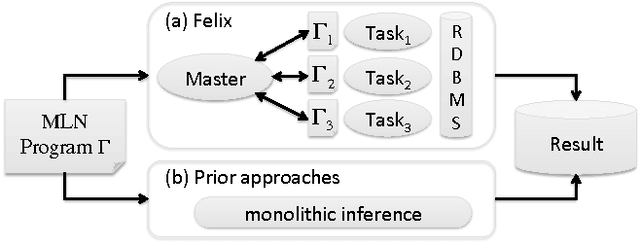



Motivated by applications in large-scale knowledge base construction, we study the problem of scaling up a sophisticated statistical inference framework called Markov Logic Networks (MLNs). Our approach, Felix, uses the idea of Lagrangian relaxation from mathematical programming to decompose a program into smaller tasks while preserving the joint-inference property of the original MLN. The advantage is that we can use highly scalable specialized algorithms for common tasks such as classification and coreference. We propose an architecture to support Lagrangian relaxation in an RDBMS which we show enables scalable joint inference for MLNs. We empirically validate that Felix is significantly more scalable and efficient than prior approaches to MLN inference by constructing a knowledge base from 1.8M documents as part of the TAC challenge. We show that Felix scales and achieves state-of-the-art quality numbers. In contrast, prior approaches do not scale even to a subset of the corpus that is three orders of magnitude smaller.
HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
Nov 11, 2011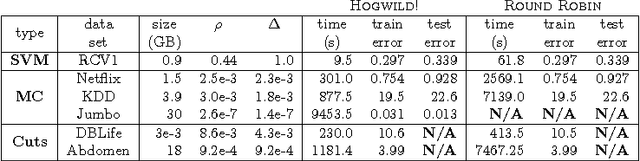
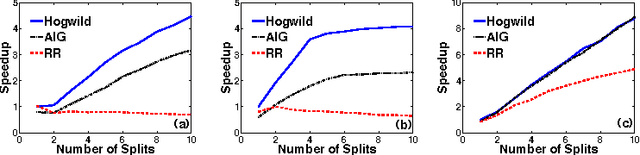
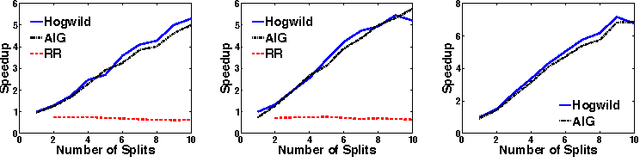
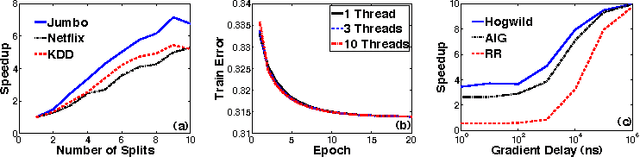
Stochastic Gradient Descent (SGD) is a popular algorithm that can achieve state-of-the-art performance on a variety of machine learning tasks. Several researchers have recently proposed schemes to parallelize SGD, but all require performance-destroying memory locking and synchronization. This work aims to show using novel theoretical analysis, algorithms, and implementation that SGD can be implemented without any locking. We present an update scheme called HOGWILD! which allows processors access to shared memory with the possibility of overwriting each other's work. We show that when the associated optimization problem is sparse, meaning most gradient updates only modify small parts of the decision variable, then HOGWILD! achieves a nearly optimal rate of convergence. We demonstrate experimentally that HOGWILD! outperforms alternative schemes that use locking by an order of magnitude.