 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cost-Accuracy Trade-offs in Multimodal Search Relevance Judgements
Oct 25, 2024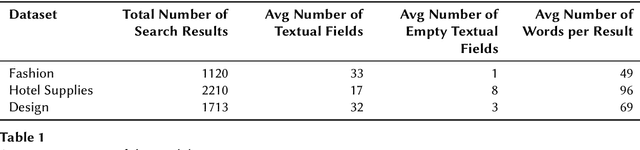

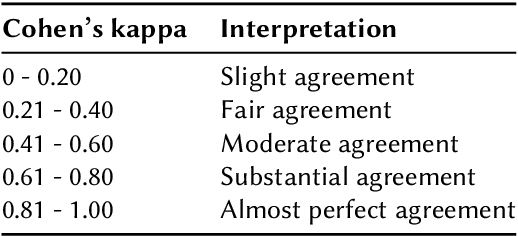
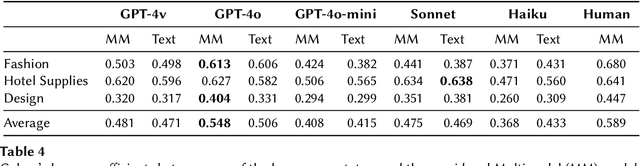
Large Language Models (LLMs) have demonstrated potential as effective search relevance evaluators. However, there is a lack of comprehensive guidance on which models consistently perform optimally across various contexts or within specific use cases. In this paper, we assess several LLMs and Multimodal Language Models (MLLMs) in terms of their alignment with human judgments across multiple multimodal search scenarios. Our analysis investigates the trade-offs between cost and accuracy, highlighting that model performance varies significantly depending on the context. Interestingly, in smaller models, the inclusion of a visual component may hinder performance rather than enhance it. These findings highlight the complexities involved in selecting the most appropriate model for practical applications.
Evaluating Entity Disambiguation and the Role of Popularity in Retrieval-Based NLP
Jun 12, 2021



Retrieval is a core component for open-domain NLP tasks. In open-domain tasks, multiple entities can share a name, making disambiguation an inherent yet under-explored problem. We propose an evaluation benchmark for assessing the entity disambiguation capabilities of these retrievers, which we call Ambiguous Entity Retrieval (AmbER) sets. We define an AmbER set as a collection of entities that share a name along with queries about those entities. By covering the set of entities for polysemous names, AmbER sets act as a challenging test of entity disambiguation. We create AmbER sets for three popular open-domain tasks: fact checking, slot filling, and question answering, and evaluate a diverse set of retrievers. We find that the retrievers exhibit popularity bias, significantly under-performing on rarer entities that share a name, e.g., they are twice as likely to retrieve erroneous documents on queries for the less popular entity under the same name. These experiments on AmbER sets show their utility as an evaluation tool and highlight the weaknesses of popular retrieval systems.
Overton: A Data System for Monitoring and Improving Machine-Learned Products
Sep 07, 2019



We describe a system called Overton, whose main design goal is to support engineers in building, monitoring, and improving production machine learning systems. Key challenges engineers face are monitoring fine-grained quality, diagnosing errors in sophisticated applications, and handling contradictory or incomplete supervision data. Overton automates the life cycle of model construction, deployment, and monitoring by providing a set of novel high-level, declarative abstractions. Overton's vision is to shift developers to these higher-level tasks instead of lower-level machine learning tasks. In fact, using Overton, engineers can build deep-learning-based applications without writing any code in frameworks like TensorFlow. For over a year, Overton has been used in production to support multiple applications in both near-real-time applications and back-of-house processing. In that time, Overton-based applications have answered billions of queries in multiple languages and processed trillions of records reducing errors 1.7-2.9 times versus production systems.