 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cost-Accuracy Trade-offs in Multimodal Search Relevance Judgements
Paper and Code
Oct 25, 2024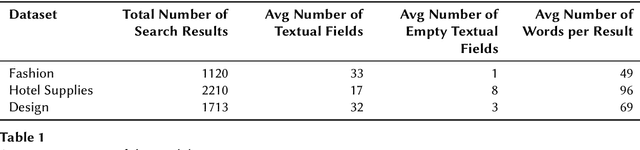

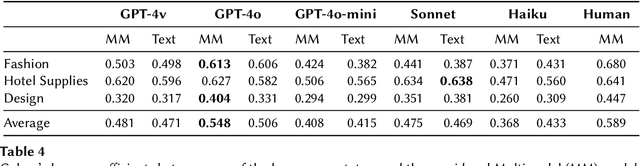
Large Language Models (LLMs) have demonstrated potential as effective search relevance evaluators. However, there is a lack of comprehensive guidance on which models consistently perform optimally across various contexts or within specific use cases. In this paper, we assess several LLMs and Multimodal Language Models (MLLMs) in terms of their alignment with human judgments across multiple multimodal search scenarios. Our analysis investigates the trade-offs between cost and accuracy, highlighting that model performance varies significantly depending on the context. Interestingly, in smaller models, the inclusion of a visual component may hinder performance rather than enhance it. These findings highlight the complexities involved in selecting the most appropriate model for practical applications.