 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Semantic-Oriented Distributional Alignment for Generative Recommendation
Feb 28, 2026Generative recommendation has emerged as a scalable alternative to traditional retrieve-and-rank pipelines by operating in a compact token space. However, existing methods mainly rely on discrete code-level supervision, which leads to information loss and limits the joint optimization between the tokenizer and the generative recommender. In this work, we propose a distribution-level supervision paradigm that leverages probability distributions over multi-layer codebooks as soft and information-rich representations. Building on this idea, we introduce Semantic-Oriented Distributional Alignment (SODA), a plug-and-play contrastive supervision framework based on Bayesian Personalized Ranking, which aligns semantically rich distributions via negative KL divergence while enabling end-to-end differentiable training. Extensive experiments on multiple real-world datasets demonstrate that SODA consistently improves the performance of various generative recommender backbones, validating its effectiveness and generality. Codes will be available upon acceptance.
Evaluating Cost-Accuracy Trade-offs in Multimodal Search Relevance Judgements
Oct 25, 2024

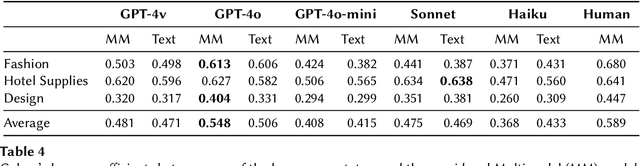
Large Language Models (LLMs) have demonstrated potential as effective search relevance evaluators. However, there is a lack of comprehensive guidance on which models consistently perform optimally across various contexts or within specific use cases. In this paper, we assess several LLMs and Multimodal Language Models (MLLMs) in terms of their alignment with human judgments across multiple multimodal search scenarios. Our analysis investigates the trade-offs between cost and accuracy, highlighting that model performance varies significantly depending on the context. Interestingly, in smaller models, the inclusion of a visual component may hinder performance rather than enhance it. These findings highlight the complexities involved in selecting the most appropriate model for practical applications.
Implicit Entity Linking in Tweets
Jul 26, 2017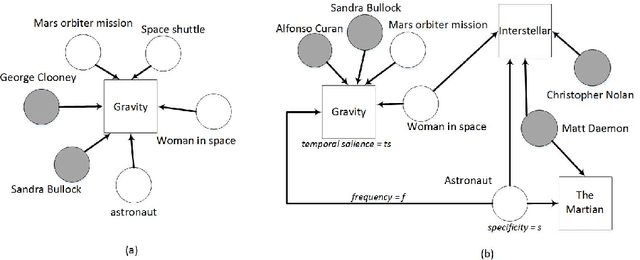
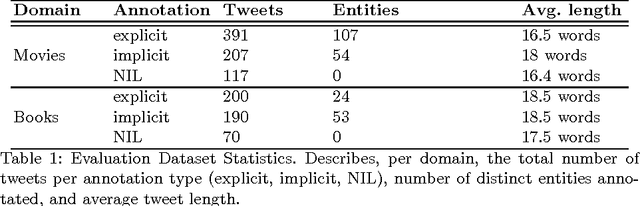


Over the years, Twitter has become one of the largest communication platforms providing key data to various applications such as brand monitoring, trend detection, among others. Entity linking is one of the major tasks in natural language understanding from tweets and it associates entity mentions in text to corresponding entries in knowledge bases in order to provide unambiguous interpretation and additional con- text. State-of-the-art techniques have focused on linking explicitly mentioned entities in tweets with reasonable success. However, we argue that in addition to explicit mentions i.e. The movie Gravity was more ex- pensive than the mars orbiter mission entities (movie Gravity) can also be mentioned implicitly i.e. This new space movie is crazy. you must watch it!. This paper introduces the problem of implicit entity linking in tweets. We propose an approach that models the entities by exploiting their factual and contextual knowledge. We demonstrate how to use these models to perform implicit entity linking on a ground truth dataset with 397 tweets from two domains, namely, Movie and Book. Specifically, we show: 1) the importance of linking implicit entities and its value addition to the standard entity linking task, and 2) the importance of exploiting contextual knowledge associated with an entity for linking their implicit mentions. We also make the ground truth dataset publicly available to foster the research in this new research area.