 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Personalized Page Content Ranking Using Customer Representation
May 09, 2023On E-commerce stores (Amazon, eBay etc.) there are rich recommendation content to help shoppers shopping more efficiently. However given numerous products, it's crucial to select most relevant content to reduce the burden of information overload. We introduced a content ranking service powered by a linear causal bandit algorithm to rank and select content for each shopper under each context. The algorithm mainly leverages aggregated customer behavior features, and ignores single shopper level past activities. We study the problem of inferring shoppers interest from historical activities. We propose a deep learning based bandit algorithm that incorporates historical shopping behavior, customer latent shopping goals, and the correlation between customers and content categories. This model produces more personalized content ranking measured by 12.08% nDCG lift. In the online A/B test setting, the model improved 0.02% annualized commercial impact measured by our business metric, validating its effectiveness.
Implicit Entity Linking in Tweets
Jul 26, 2017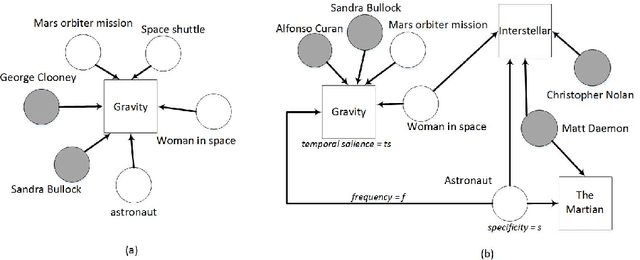
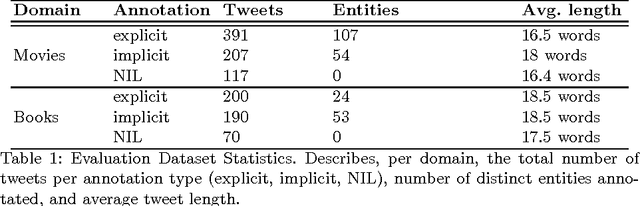


Over the years, Twitter has become one of the largest communication platforms providing key data to various applications such as brand monitoring, trend detection, among others. Entity linking is one of the major tasks in natural language understanding from tweets and it associates entity mentions in text to corresponding entries in knowledge bases in order to provide unambiguous interpretation and additional con- text. State-of-the-art techniques have focused on linking explicitly mentioned entities in tweets with reasonable success. However, we argue that in addition to explicit mentions i.e. The movie Gravity was more ex- pensive than the mars orbiter mission entities (movie Gravity) can also be mentioned implicitly i.e. This new space movie is crazy. you must watch it!. This paper introduces the problem of implicit entity linking in tweets. We propose an approach that models the entities by exploiting their factual and contextual knowledge. We demonstrate how to use these models to perform implicit entity linking on a ground truth dataset with 397 tweets from two domains, namely, Movie and Book. Specifically, we show: 1) the importance of linking implicit entities and its value addition to the standard entity linking task, and 2) the importance of exploiting contextual knowledge associated with an entity for linking their implicit mentions. We also make the ground truth dataset publicly available to foster the research in this new research area.
Knowledge will Propel Machine Understanding of Content: Extrapolating from Current Examples
Jul 14, 2017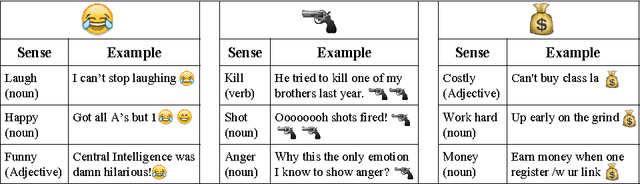
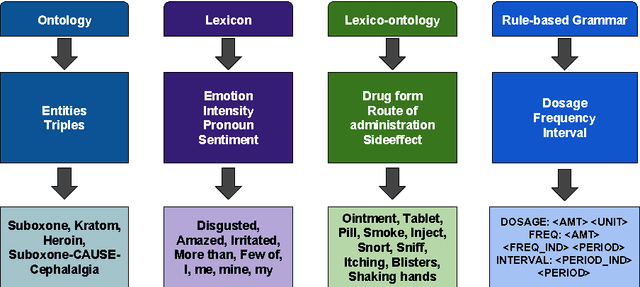
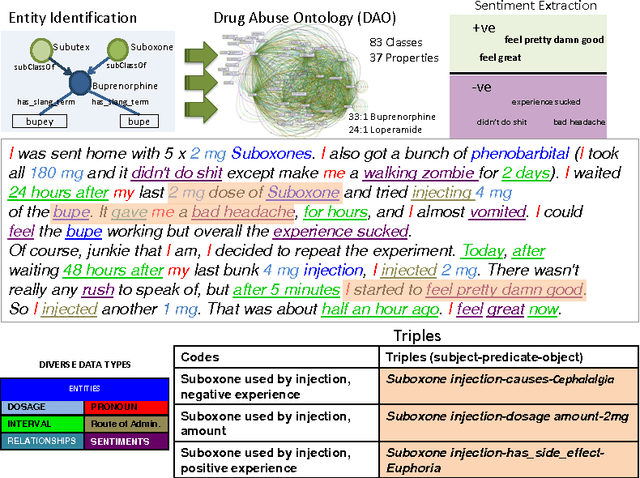
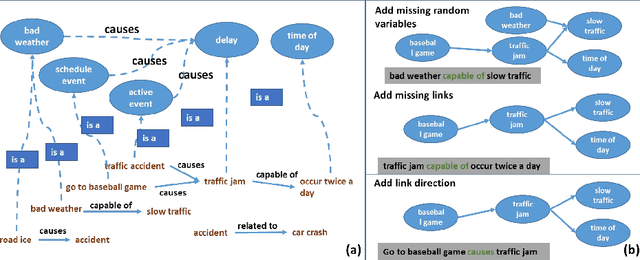
Machine Learning has been a big success story during the AI resurgence. One particular stand out success relates to learning from a massive amount of data. In spite of early assertions of the unreasonable effectiveness of data, there is increasing recognition for utilizing knowledge whenever it is available or can be created purposefully. In this paper, we discuss the indispensable role of knowledge for deeper understanding of content where (i) large amounts of training data are unavailable, (ii) the objects to be recognized are complex, (e.g., implicit entities and highly subjective content), and (iii) applications need to use complementary or related data in multiple modalities/media. What brings us to the cusp of rapid progress is our ability to (a) create relevant and reliable knowledge and (b) carefully exploit knowledge to enhance ML/NLP techniques. Using diverse examples, we seek to foretell unprecedented progress in our ability for deeper understanding and exploitation of multimodal data and continued incorporation of knowledge in learning techniques.