 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Sensitivity in LLMs: A Tiered Evaluation of Contextual Bias via Behavioral Profiling and Mechanistic Interpretability
May 04, 2026Large language models (LLMs) are increasingly deployed in settings that require nuanced ethical reasoning, yet existing bias evaluations treat model outputs as simply "biased" or "unbiased." This binary framing misses the gradual, context-sensitive way bias actually emerges. We address this gap in two stages: behavioral profiling and mechanistic validation. In the behavioral stage, we introduce the Moral Sensitivity Index (MSI), a metric that quantifies the probability of biased output across a graduated, seven-tier stress test ranging from abstract numerical problems to scenarios rooted in historical and socioeconomic injustice. Evaluating four leading models (Claude 3.5, Qwen 3.5, Llama 3, and Gemini 1.5), we identify distinct behavioral signatures shaped by alignment design: for instance, Gemini 1.5 reaches 72.7% MSI by Tier 5 under socioeconomic framing, while Claude exhibits sharp suppression consistent with identity-based safety training. We then verify these behavioral patterns mechanistically. We select criminal-bias scenarios, which produced the highest MSI scores across models, as probes and apply logit lens, attention analysis, activation patching, and semantic probing to a controlled set of six models spanning three capability tiers: small language models (SLMs), instruction-tuned base models, and reasoning-distilled variants. Circuit-level analysis reveals a U-curve of bias: SLMs exhibit strong criminal bias; scaling to instruction-tuned models eliminates it; reasoning distillation reintroduces bias to SLM-like levels despite identical parameter counts, suggesting distillation compresses reasoning traces in ways that reactivate shallow statistical associations. Critically, the socially loaded cues that drive high MSI scores activate the same bias-driving circuits identified mechanistically, providing cross-stage validation.
If Pigs Could Fly... Can LLMs Logically Reason Through Counterfactuals?
May 28, 2025Large Language Models (LLMs) demonstrate impressive reasoning capabilities in familiar contexts, but struggle when the context conflicts with their parametric knowledge. To investigate this phenomenon, we introduce CounterLogic, a dataset containing 1,800 examples across 9 logical schemas, explicitly designed to evaluate logical reasoning through counterfactual (hypothetical knowledge-conflicting) scenarios. Our systematic evaluation of 11 LLMs across 6 different datasets reveals a consistent performance degradation, with accuracies dropping by 27% on average when reasoning through counterfactual information. We propose Self-Segregate, a prompting method enabling metacognitive awareness (explicitly identifying knowledge conflicts) before reasoning. Our method dramatically narrows the average performance gaps from 27% to just 11%, while significantly increasing the overall accuracy (+7.5%). We discuss the implications of these findings and draw parallels to human cognitive processes, particularly on how humans disambiguate conflicting information during reasoning tasks. Our findings offer practical insights for understanding and enhancing LLMs reasoning capabilities in real-world applications, especially where models must logically reason independently of their factual knowledge.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023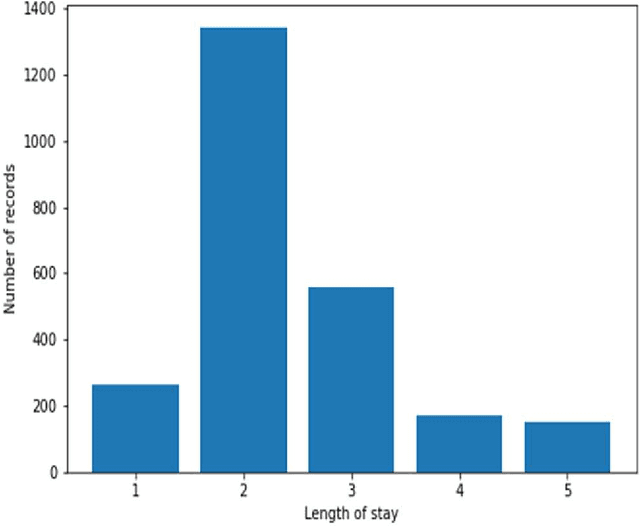
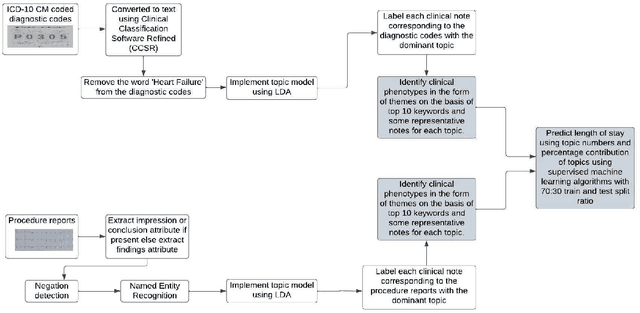
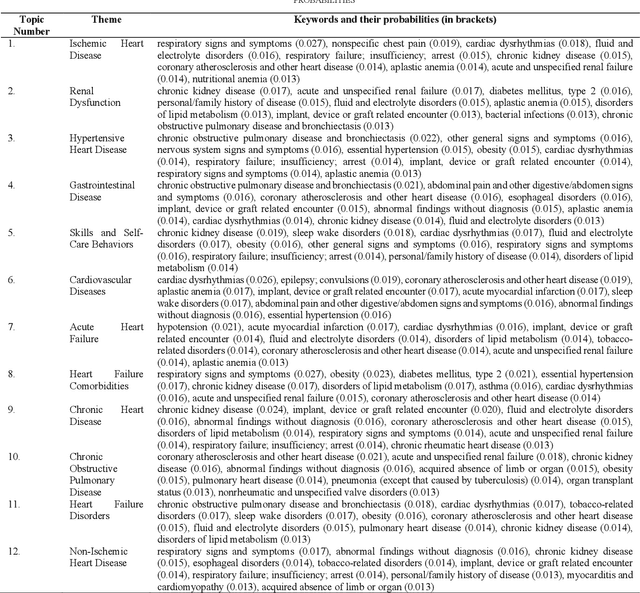
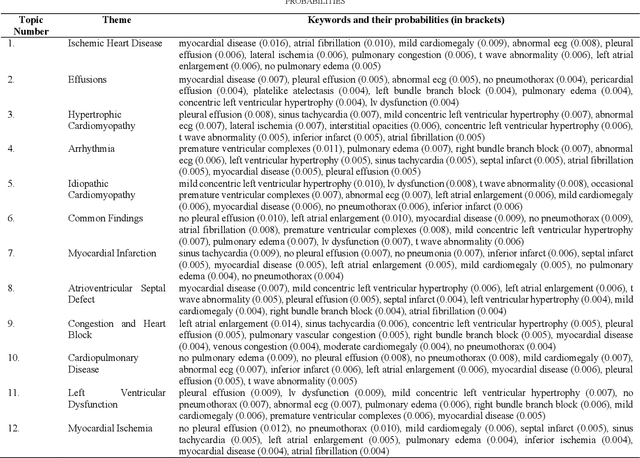
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.
Leveraging Natural Learning Processing to Uncover Themes in Clinical Notes of Patients Admitted for Heart Failure
Apr 14, 2022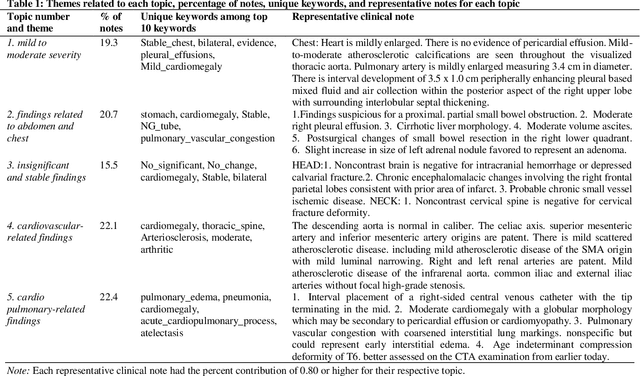
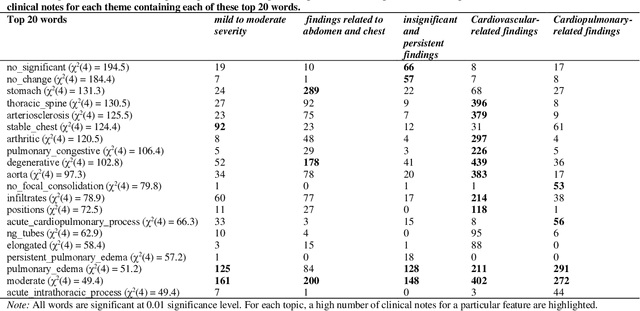
Heart failure occurs when the heart is not able to pump blood and oxygen to support other organs in the body as it should. Treatments include medications and sometimes hospitalization. Patients with heart failure can have both cardiovascular as well as non-cardiovascular comorbidities. Clinical notes of patients with heart failure can be analyzed to gain insight into the topics discussed in these notes and the major comorbidities in these patients. In this regard, we apply machine learning techniques, such as topic modeling, to identify the major themes found in the clinical notes specific to the procedures performed on 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling revealed five hidden themes in these clinical notes, including one related to heart disease comorbidities.
Improving the Factual Accuracy of Abstractive Clinical Text Summarization using Multi-Objective Optimization
Apr 02, 2022
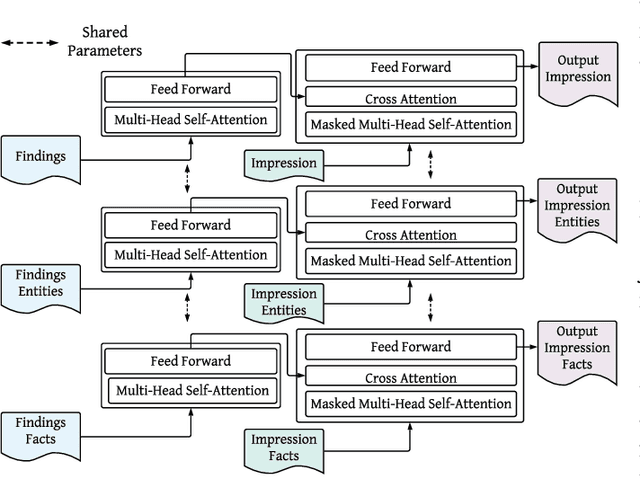

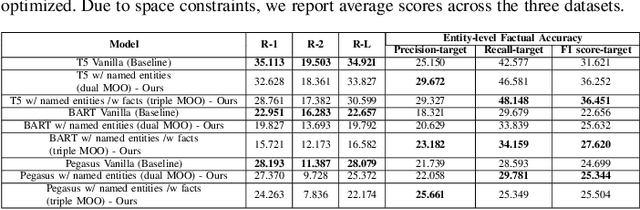
While there has been recent progress in abstractive summarization as applied to different domains including news articles, scientific articles, and blog posts, the application of these techniques to clinical text summarization has been limited. This is primarily due to the lack of large-scale training data and the messy/unstructured nature of clinical notes as opposed to other domains where massive training data come in structured or semi-structured form. Further, one of the least explored and critical components of clinical text summarization is factual accuracy of clinical summaries. This is specifically crucial in the healthcare domain, cardiology in particular, where an accurate summary generation that preserves the facts in the source notes is critical to the well-being of a patient. In this study, we propose a framework for improving the factual accuracy of abstractive summarization of clinical text using knowledge-guided multi-objective optimization. We propose to jointly optimize three cost functions in our proposed architecture during training: generative loss, entity loss and knowledge loss and evaluate the proposed architecture on 1) clinical notes of patients with heart failure (HF), which we collect for this study; and 2) two benchmark datasets, Indiana University Chest X-ray collection (IU X-Ray), and MIMIC-CXR, that are publicly available. We experiment with three transformer encoder-decoder architectures and demonstrate that optimizing different loss functions leads to improved performance in terms of entity-level factual accuracy.
Entity-driven Fact-aware Abstractive Summarization of Biomedical Literature
Mar 30, 2022



As part of the large number of scientific articles being published every year, the publication rate of biomedical literature has been increasing. Consequently, there has been considerable effort to harness and summarize the massive amount of biomedical research articles. While transformer-based encoder-decoder models in a vanilla source document-to-summary setting have been extensively studied for abstractive summarization in different domains, their major limitations continue to be entity hallucination (a phenomenon where generated summaries constitute entities not related to or present in source article(s)) and factual inconsistency. This problem is exacerbated in a biomedical setting where named entities and their semantics (which can be captured through a knowledge base) constitute the essence of an article. The use of named entities and facts mined from background knowledge bases pertaining to the named entities to guide abstractive summarization has not been studied in biomedical article summarization literature. In this paper, we propose an entity-driven fact-aware framework for training end-to-end transformer-based encoder-decoder models for abstractive summarization of biomedical articles. We call the proposed approach, whose building block is a transformer-based model, EFAS, Entity-driven Fact-aware Abstractive Summarization. We conduct experiments using five state-of-the-art transformer-based models (two of which are specifically designed for long document summarization) and demonstrate that injecting knowledge into the training/inference phase of these models enables the models to achieve significantly better performance than the standard source document-to-summary setting in terms of entity-level factual accuracy, N-gram novelty, and semantic equivalence while performing comparably on ROUGE metrics. The proposed approach is evaluated on ICD-11-Summ-1000, and PubMed-50k.
The Duality of Data and Knowledge Across the Three Waves of AI
Apr 14, 2021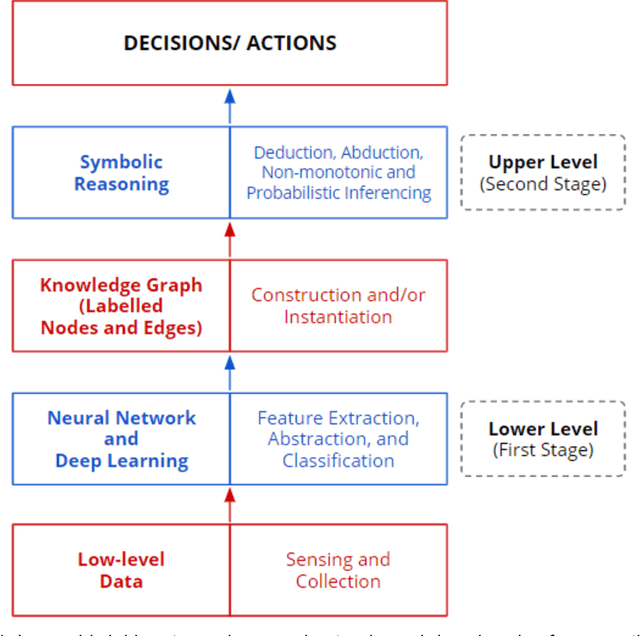
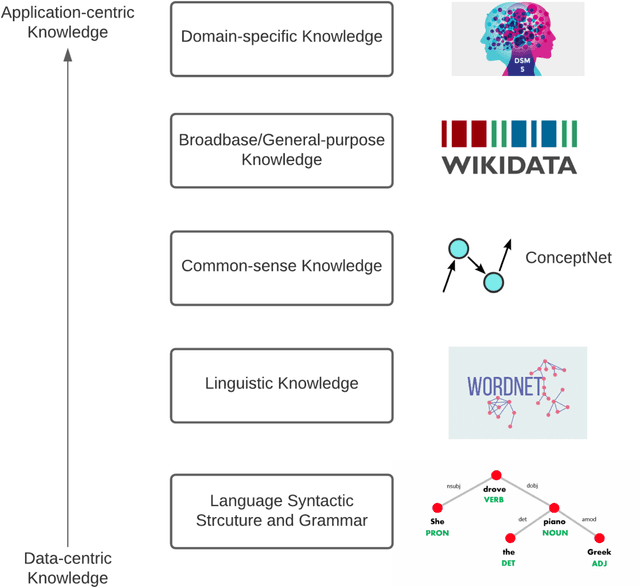
We discuss how over the last 30 to 50 years, Artificial Intelligence (AI) systems that focused only on data have been handicapped, and how knowledge has been critical in developing smarter, intelligent, and more effective systems. In fact, the vast progress in AI can be viewed in terms of the three waves of AI as identified by DARPA. During the first wave, handcrafted knowledge has been at the center-piece, while during the second wave, the data-driven approaches supplanted knowledge. Now we see a strong role and resurgence of knowledge fueling major breakthroughs in the third wave of AI underpinning future intelligent systems as they attempt human-like decision making, and seek to become trusted assistants and companions for humans. We find a wider availability of knowledge created from diverse sources, using manual to automated means both by repurposing as well as by extraction. Using knowledge with statistical learning is becoming increasingly indispensable to help make AI systems more transparent and auditable. We will draw a parallel with the role of knowledge and experience in human intelligence based on cognitive science, and discuss emerging neuro-symbolic or hybrid AI systems in which knowledge is the critical enabler for combining capabilities of the data-intensive statistical AI systems with those of symbolic AI systems, resulting in more capable AI systems that support more human-like intelligence.
* A version of this will appear as (cite as): IT Professional Magazine (special section to commemorate the 75th Anniversary of IEEE Computer Society), 23 (3) April-May 2021
Characterization of Time-variant and Time-invariant Assessment of Suicidality on Reddit using C-SSRS
Apr 09, 2021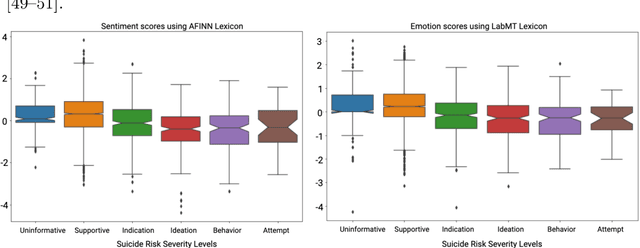
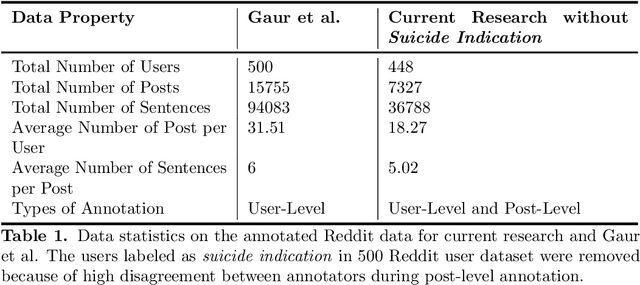
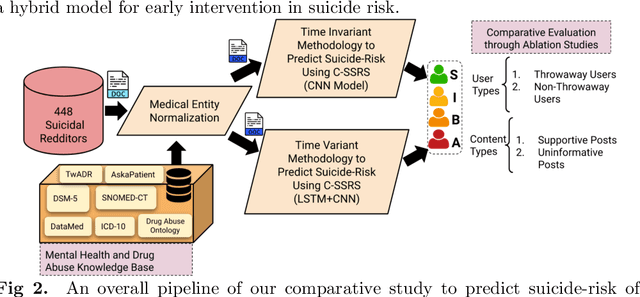

Suicide is the 10th leading cause of death in the U.S (1999-2019). However, predicting when someone will attempt suicide has been nearly impossible. In the modern world, many individuals suffering from mental illness seek emotional support and advice on well-known and easily-accessible social media platforms such as Reddit. While prior artificial intelligence research has demonstrated the ability to extract valuable information from social media on suicidal thoughts and behaviors, these efforts have not considered both severity and temporality of risk. The insights made possible by access to such data have enormous clinical potential - most dramatically envisioned as a trigger to employ timely and targeted interventions (i.e., voluntary and involuntary psychiatric hospitalization) to save lives. In this work, we address this knowledge gap by developing deep learning algorithms to assess suicide risk in terms of severity and temporality from Reddit data based on the Columbia Suicide Severity Rating Scale (C-SSRS). In particular, we employ two deep learning approaches: time-variant and time-invariant modeling, for user-level suicide risk assessment, and evaluate their performance against a clinician-adjudicated gold standard Reddit corpus annotated based on the C-SSRS. Our results suggest that the time-variant approach outperforms the time-invariant method in the assessment of suicide-related ideations and supportive behaviors (AUC:0.78), while the time-invariant model performed better in predicting suicide-related behaviors and suicide attempt (AUC:0.64). The proposed approach can be integrated with clinical diagnostic interviews for improving suicide risk assessments.
COVID-19 and Mental Health/Substance Use Disorders on Reddit: A Longitudinal Study
Nov 20, 2020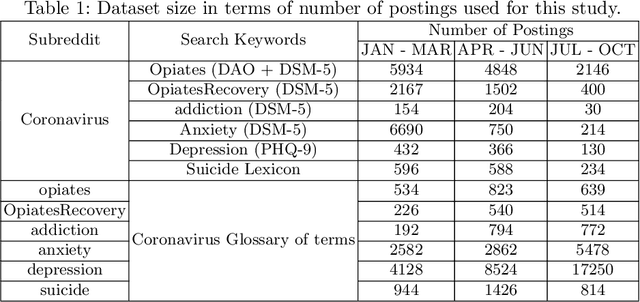
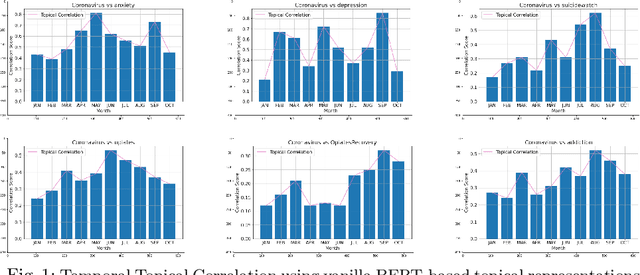
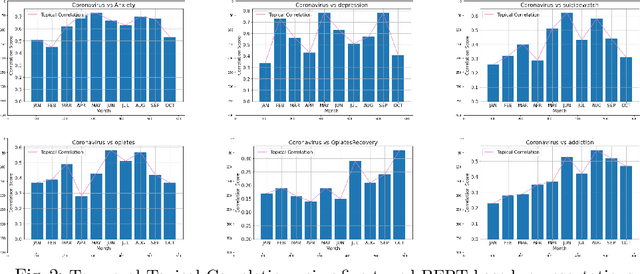

COVID-19 pandemic has adversely and disproportionately impacted people suffering from mental health issues and substance use problems. This has been exacerbated by social isolation during the pandemic and the social stigma associated with mental health and substance use disorders, making people reluctant to share their struggles and seek help. Due to the anonymity and privacy they provide, social media emerged as a convenient medium for people to share their experiences about their day to day struggles. Reddit is a well-recognized social media platform that provides focused and structured forums called subreddits, that users subscribe to and discuss their experiences with others. Temporal assessment of the topical correlation between social media postings about mental health/substance use and postings about Coronavirus is crucial to better understand public sentiment on the pandemic and its evolving impact, especially related to vulnerable populations. In this study, we conduct a longitudinal topical analysis of postings between subreddits r/depression, r/Anxiety, r/SuicideWatch, and r/Coronavirus, and postings between subreddits r/opiates, r/OpiatesRecovery, r/addiction, and r/Coronavirus from January 2020 - October 2020. Our results show a high topical correlation between postings in r/depression and r/Coronavirus in September 2020. Further, the topical correlation between postings on substance use disorders and Coronavirus fluctuates, showing the highest correlation in August 2020. By monitoring these trends from platforms such as Reddit, epidemiologists, and mental health professionals can gain insights into the challenges faced by communities for targeted interventions.
Predicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.