 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperPrompt: Prompt-based Task-Conditioning of Transformers
Mar 01, 2022

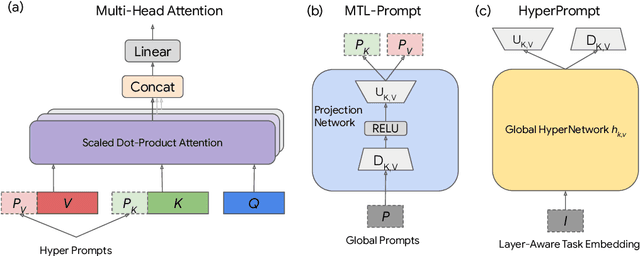
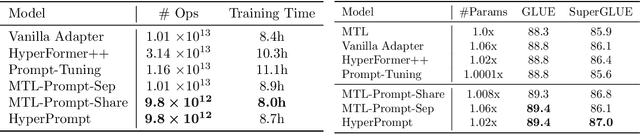
Prompt-Tuning is a new paradigm for finetuning pre-trained language models in a parameter-efficient way. Here, we explore the use of HyperNetworks to generate hyper-prompts: we propose HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers. The hyper-prompts are end-to-end learnable via generation by a HyperNetwork. HyperPrompt allows the network to learn task-specific feature maps where the hyper-prompts serve as task global memories for the queries to attend to, at the same time enabling flexible information sharing among tasks. We show that HyperPrompt is competitive against strong multi-task learning baselines with as few as $0.14\%$ of additional task-conditioning parameters, achieving great parameter and computational efficiency. Through extensive empirical experiments, we demonstrate that HyperPrompt can achieve superior performances over strong T5 multi-task learning baselines and parameter-efficient adapter variants including Prompt-Tuning and HyperFormer++ on Natural Language Understanding benchmarks of GLUE and SuperGLUE across many model sizes.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021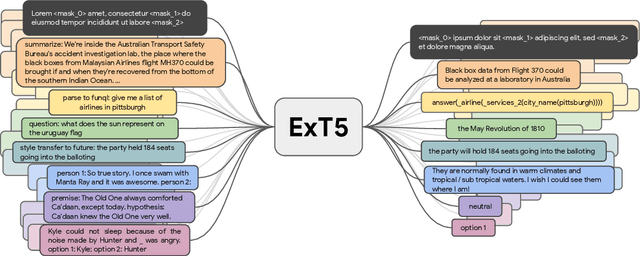
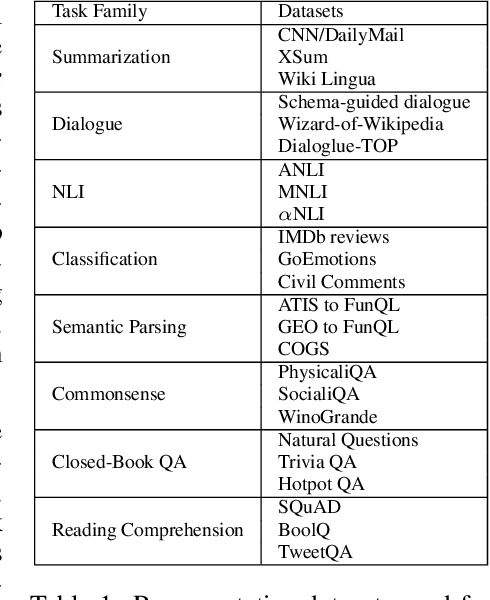
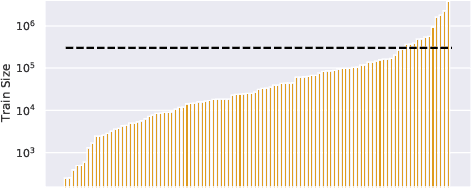
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
How Reliable are Model Diagnostics?
May 12, 2021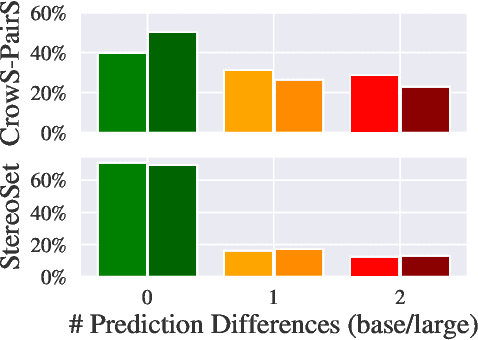
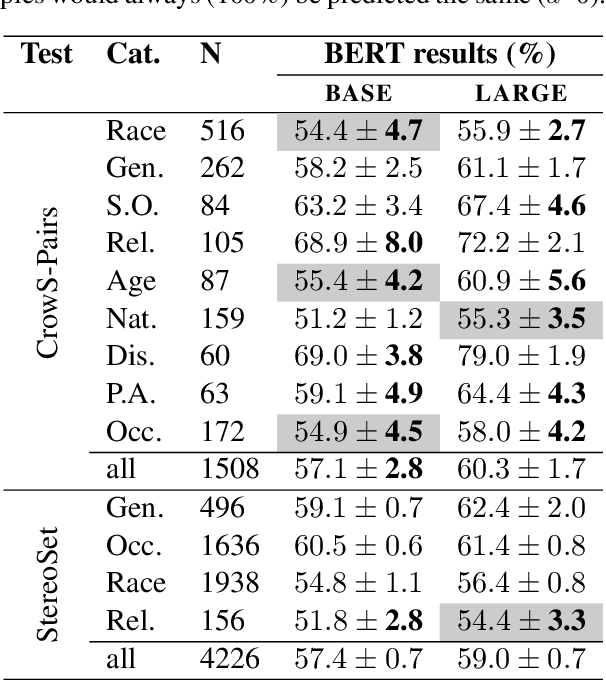
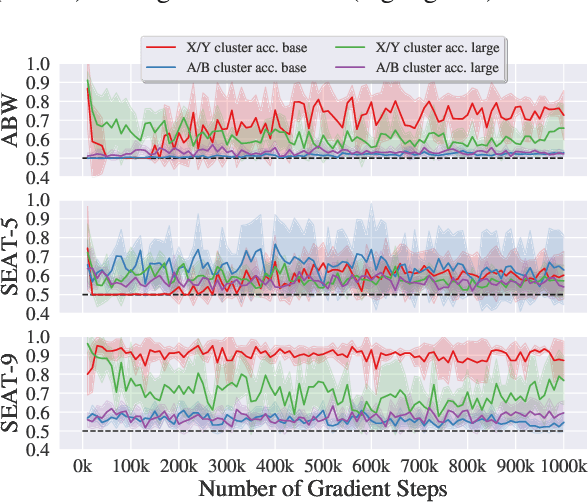

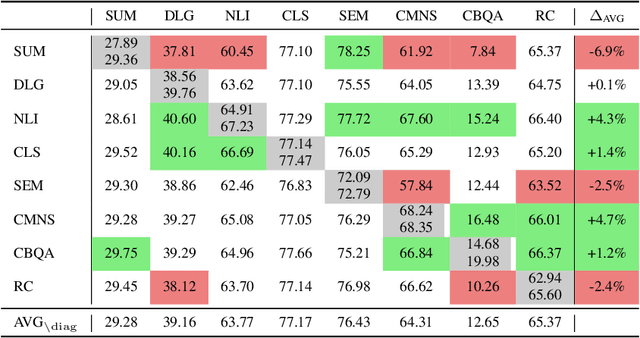
In the pursuit of a deeper understanding of a model's behaviour, there is recent impetus for developing suites of probes aimed at diagnosing models beyond simple metrics like accuracy or BLEU. This paper takes a step back and asks an important and timely question: how reliable are these diagnostics in providing insight into models and training setups? We critically examine three recent diagnostic tests for pre-trained language models, and find that likelihood-based and representation-based model diagnostics are not yet as reliable as previously assumed. Based on our empirical findings, we also formulate recommendations for practitioners and researchers.
Are Pre-trained Convolutions Better than Pre-trained Transformers?
May 07, 2021
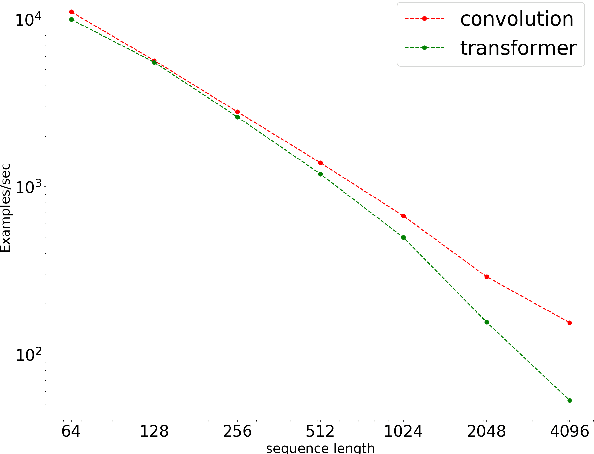

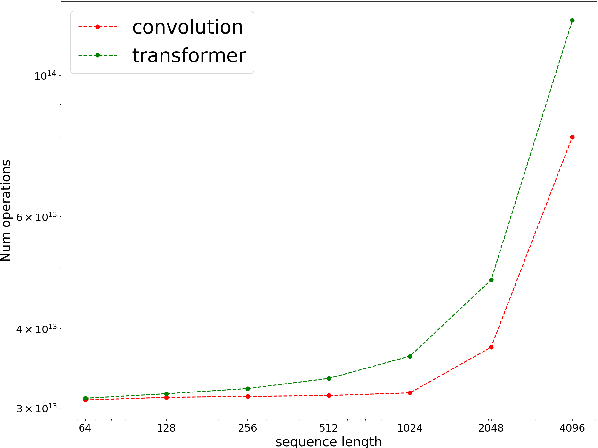
In the era of pre-trained language models, Transformers are the de facto choice of model architectures. While recent research has shown promise in entirely convolutional, or CNN, architectures, they have not been explored using the pre-train-fine-tune paradigm. In the context of language models, are convolutional models competitive to Transformers when pre-trained? This paper investigates this research question and presents several interesting findings. Across an extensive set of experiments on 8 datasets/tasks, we find that CNN-based pre-trained models are competitive and outperform their Transformer counterpart in certain scenarios, albeit with caveats. Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. We believe our research paves the way for a healthy amount of optimism in alternative architectures.
Characterization of Time-variant and Time-invariant Assessment of Suicidality on Reddit using C-SSRS
Apr 09, 2021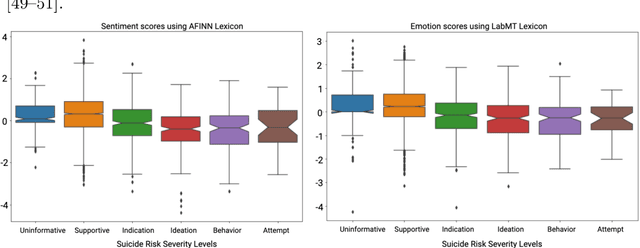
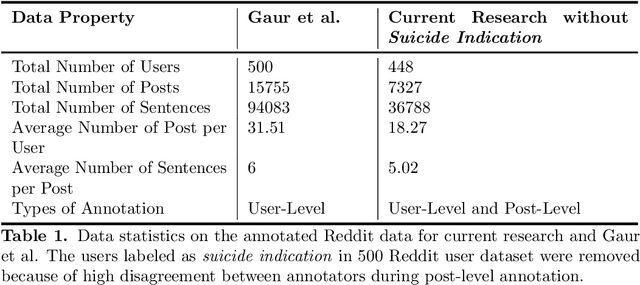
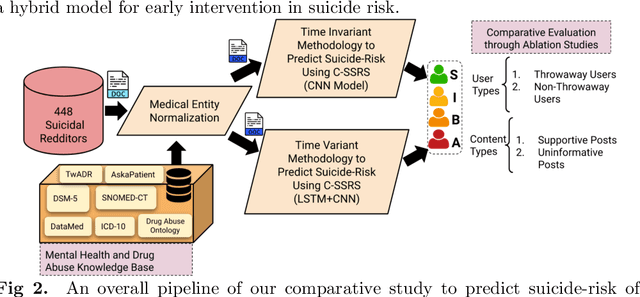

Suicide is the 10th leading cause of death in the U.S (1999-2019). However, predicting when someone will attempt suicide has been nearly impossible. In the modern world, many individuals suffering from mental illness seek emotional support and advice on well-known and easily-accessible social media platforms such as Reddit. While prior artificial intelligence research has demonstrated the ability to extract valuable information from social media on suicidal thoughts and behaviors, these efforts have not considered both severity and temporality of risk. The insights made possible by access to such data have enormous clinical potential - most dramatically envisioned as a trigger to employ timely and targeted interventions (i.e., voluntary and involuntary psychiatric hospitalization) to save lives. In this work, we address this knowledge gap by developing deep learning algorithms to assess suicide risk in terms of severity and temporality from Reddit data based on the Columbia Suicide Severity Rating Scale (C-SSRS). In particular, we employ two deep learning approaches: time-variant and time-invariant modeling, for user-level suicide risk assessment, and evaluate their performance against a clinician-adjudicated gold standard Reddit corpus annotated based on the C-SSRS. Our results suggest that the time-variant approach outperforms the time-invariant method in the assessment of suicide-related ideations and supportive behaviors (AUC:0.78), while the time-invariant model performed better in predicting suicide-related behaviors and suicide attempt (AUC:0.64). The proposed approach can be integrated with clinical diagnostic interviews for improving suicide risk assessments.
OmniNet: Omnidirectional Representations from Transformers
Mar 01, 2021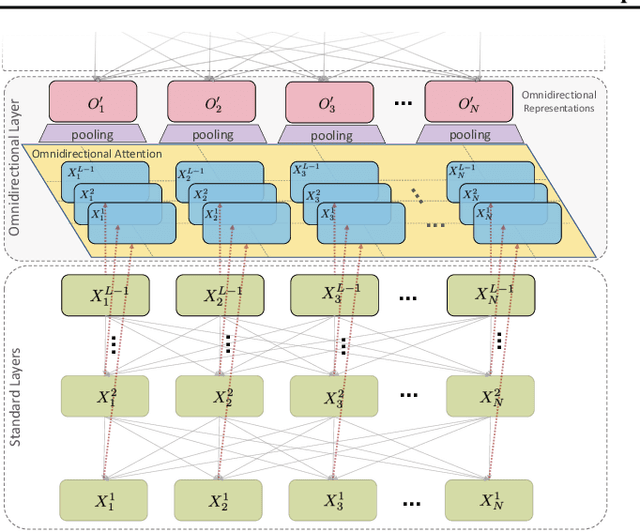

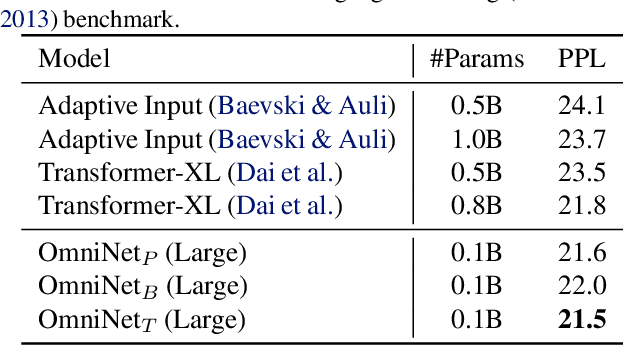
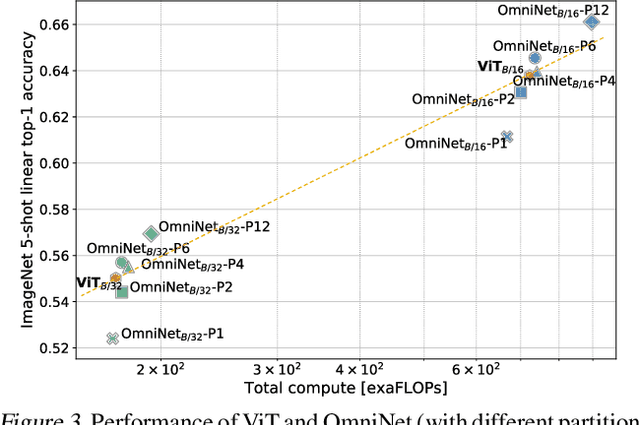
This paper proposes Omnidirectional Representations from Transformers (OmniNet). In OmniNet, instead of maintaining a strictly horizontal receptive field, each token is allowed to attend to all tokens in the entire network. This process can also be interpreted as a form of extreme or intensive attention mechanism that has the receptive field of the entire width and depth of the network. To this end, the omnidirectional attention is learned via a meta-learner, which is essentially another self-attention based model. In order to mitigate the computationally expensive costs of full receptive field attention, we leverage efficient self-attention models such as kernel-based (Choromanski et al.), low-rank attention (Wang et al.) and/or Big Bird (Zaheer et al.) as the meta-learner. Extensive experiments are conducted on autoregressive language modeling (LM1B, C4), Machine Translation, Long Range Arena (LRA), and Image Recognition. The experiments show that OmniNet achieves considerable improvements across these tasks, including achieving state-of-the-art performance on LM1B, WMT'14 En-De/En-Fr, and Long Range Arena. Moreover, using omnidirectional representation in Vision Transformers leads to significant improvements on image recognition tasks on both few-shot learning and fine-tuning setups.