 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Sensitivity in LLMs: A Tiered Evaluation of Contextual Bias via Behavioral Profiling and Mechanistic Interpretability
May 04, 2026Large language models (LLMs) are increasingly deployed in settings that require nuanced ethical reasoning, yet existing bias evaluations treat model outputs as simply "biased" or "unbiased." This binary framing misses the gradual, context-sensitive way bias actually emerges. We address this gap in two stages: behavioral profiling and mechanistic validation. In the behavioral stage, we introduce the Moral Sensitivity Index (MSI), a metric that quantifies the probability of biased output across a graduated, seven-tier stress test ranging from abstract numerical problems to scenarios rooted in historical and socioeconomic injustice. Evaluating four leading models (Claude 3.5, Qwen 3.5, Llama 3, and Gemini 1.5), we identify distinct behavioral signatures shaped by alignment design: for instance, Gemini 1.5 reaches 72.7% MSI by Tier 5 under socioeconomic framing, while Claude exhibits sharp suppression consistent with identity-based safety training. We then verify these behavioral patterns mechanistically. We select criminal-bias scenarios, which produced the highest MSI scores across models, as probes and apply logit lens, attention analysis, activation patching, and semantic probing to a controlled set of six models spanning three capability tiers: small language models (SLMs), instruction-tuned base models, and reasoning-distilled variants. Circuit-level analysis reveals a U-curve of bias: SLMs exhibit strong criminal bias; scaling to instruction-tuned models eliminates it; reasoning distillation reintroduces bias to SLM-like levels despite identical parameter counts, suggesting distillation compresses reasoning traces in ways that reactivate shallow statistical associations. Critically, the socially loaded cues that drive high MSI scores activate the same bias-driving circuits identified mechanistically, providing cross-stage validation.
Mechanistic Steering of LLMs Reveals Layer-wise Feature Vulnerabilities in Adversarial Settings
Apr 25, 2026Large language models (LLMs) can still be jailbroken into producing harmful outputs despite safety alignment. Existing attacks show this vulnerability, but not the internal mechanisms that cause it. This study asks whether jailbreak success is driven by identifiable internal features rather than prompts alone. We propose a three-stage pipeline for Gemma-2-2B using the BeaverTails dataset. First, we extract concept-aligned tokens from adversarial responses via subspace similarity. Second, we apply three feature-grouping strategies (cluster, hierarchical-linkage, and single-token-driven) to identify SAE feature subgroups for the aligned tokens across all 26 model layers. Third, we steer the model by amplifying the top features from each identified subgroup and measure the change in harmfulness score using a standardized LLM-judge scoring protocol. In all three approaches, the features in the layers [16-25] were relatively more vulnerable to steering. All three methods confirmed that mid to later layer feature subgroups are more responsible for unsafe outputs. These results provide evidence that the jailbreak vulnerability in Gemma-2-2B is localized to feature subgroups of mid to later layers, suggesting that targeted feature-level interventions may offer a more principled path to adversarial robustness than current prompt-level defenses.
Experiments or Outcomes? Probing Scientific Feasibility in Large Language Models
Apr 20, 2026Scientific feasibility assessment asks whether a claim is consistent with established knowledge and whether experimental evidence could support or refute it. We frame feasibility assessment as a diagnostic reasoning task in which, given a hypothesis, a model predicts feasible or infeasible and justifies its decision. We evaluate large language models (LLMs) under controlled knowledge conditions (hypothesis-only, with experiments, with outcomes, or both) and probe robustness by progressively removing portions of the experimental and/or outcome context. Across multiple LLMs and two datasets, providing outcome evidence is generally more reliable than providing experiment descriptions. Outcomes tend to improve accuracy beyond what internal knowledge alone provides, whereas experimental text can be brittle and may degrade performance when the context is incomplete. These findings clarify when experimental evidence benefits LLM-based feasibility assessment and when it introduces fragility.
IMRNNs: An Efficient Method for Interpretable Dense Retrieval via Embedding Modulation
Jan 27, 2026Interpretability in black-box dense retrievers remains a central challenge in Retrieval-Augmented Generation (RAG). Understanding how queries and documents semantically interact is critical for diagnosing retrieval behavior and improving model design. However, existing dense retrievers rely on static embeddings for both queries and documents, which obscures this bidirectional relationship. Post-hoc approaches such as re-rankers are computationally expensive, add inference latency, and still fail to reveal the underlying semantic alignment. To address these limitations, we propose Interpretable Modular Retrieval Neural Networks (IMRNNs), a lightweight framework that augments any dense retriever with dynamic, bidirectional modulation at inference time. IMRNNs employ two independent adapters: one conditions document embeddings on the current query, while the other refines the query embedding using corpus-level feedback from initially retrieved documents. This iterative modulation process enables the model to adapt representations dynamically and expose interpretable semantic dependencies between queries and documents. Empirically, IMRNNs not only enhance interpretability but also improve retrieval effectiveness. Across seven benchmark datasets, applying our method to standard dense retrievers yields average gains of +6.35% nDCG, +7.14% recall, and +7.04% MRR over state-of-the-art baselines. These results demonstrate that incorporating interpretability-driven modulation can both explain and enhance retrieval in RAG systems.
Beyond Memorization: Testing LLM Reasoning on Unseen Theory of Computation Tasks
Jan 19, 2026Large language models (LLMs) have demonstrated strong performance on formal language tasks, yet whether this reflects genuine symbolic reasoning or pattern matching on familiar constructions remains unclear. We introduce a benchmark for deterministic finite automata (DFA) construction from regular languages, comprising factual knowledge questions, seen construction problems from public sources, and two types of unseen problems: hand-crafted instances with multiple interacting constraints and systematically generated problems via Arden's theorem. Models achieve perfect accuracy on factual questions and 84-90% on seen tasks. However, accuracy drops sharply on unseen problems (by 30-64%), with failures stemming from systematic misinterpretation of language constraints, incorrect handling of Kleene-star semantics, and a failure to preserve global consistency. We evaluate a three-stage hint protocol that enables correction of shallow errors but does not reliably resolve globally inconsistent or structurally flawed automata. Our analysis across multiple prompting strategies (direct, Chain-of-Thought, Tree-of-Thought) reveals that errors persist regardless of prompting approach, exposing a fundamental gap between LLMs' ability to generate syntactically plausible DFAs and their capacity for semantically correct formal reasoning.
Neurosymbolic Retrievers for Retrieval-augmented Generation
Jan 08, 2026Retrieval Augmented Generation (RAG) has made significant strides in overcoming key limitations of large language models, such as hallucination, lack of contextual grounding, and issues with transparency. However, traditional RAG systems consist of three interconnected neural components - the retriever, re-ranker, and generator - whose internal reasoning processes remain opaque. This lack of transparency complicates interpretability, hinders debugging efforts, and erodes trust, especially in high-stakes domains where clear decision-making is essential. To address these challenges, we introduce the concept of Neurosymbolic RAG, which integrates symbolic reasoning using a knowledge graph with neural retrieval techniques. This new framework aims to answer two primary questions: (a) Can retrievers provide a clear and interpretable basis for document selection? (b) Can symbolic knowledge enhance the clarity of the retrieval process? We propose three methods to improve this integration. First is MAR (Knowledge Modulation Aligned Retrieval) that employs modulation networks to refine query embeddings using interpretable symbolic features, thereby making document matching more explicit. Second, KG-Path RAG enhances queries by traversing knowledge graphs to improve overall retrieval quality and interpretability. Lastly, Process Knowledge-infused RAG utilizes domain-specific tools to reorder retrieved content based on validated workflows. Preliminary results from mental health risk assessment tasks indicate that this neurosymbolic approach enhances both transparency and overall performance
SymLoc: Symbolic Localization of Hallucination across HaluEval and TruthfulQA
Nov 18, 2025



LLMs still struggle with hallucination, especially when confronted with symbolic triggers like modifiers, negation, numbers, exceptions, and named entities. Yet, we lack a clear understanding of where these symbolic hallucinations originate, making it crucial to systematically handle such triggers and localize the emergence of hallucination inside the model. While prior work explored localization using statistical techniques like LSC and activation variance analysis, these methods treat all tokens equally and overlook the role symbolic linguistic knowledge plays in triggering hallucinations. So far, no approach has investigated how symbolic elements specifically drive hallucination failures across model layers, nor has symbolic linguistic knowledge been used as the foundation for a localization framework. We propose the first symbolic localization framework that leverages symbolic linguistic and semantic knowledge to meaningfully trace the development of hallucinations across all model layers. By focusing on how models process symbolic triggers, we analyze five models using HaluEval and TruthfulQA. Our symbolic knowledge approach reveals that attention variance for these linguistic elements explodes to critical instability in early layers (2-4), with negation triggering catastrophic variance levels, demonstrating that symbolic semantic processing breaks down from the very beginning. Through the lens of symbolic linguistic knowledge, despite larger model sizes, hallucination rates remain consistently high (78.3%-83.7% across Gemma variants), with steep attention drops for symbolic semantic triggers throughout deeper layers. Our findings demonstrate that hallucination is fundamentally a symbolic linguistic processing failure, not a general generation problem, revealing that symbolic semantic knowledge provides the key to understanding and localizing hallucination mechanisms in LLMs.
Side Effects of Erasing Concepts from Diffusion Models
Aug 20, 2025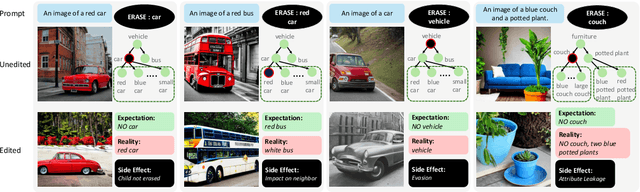
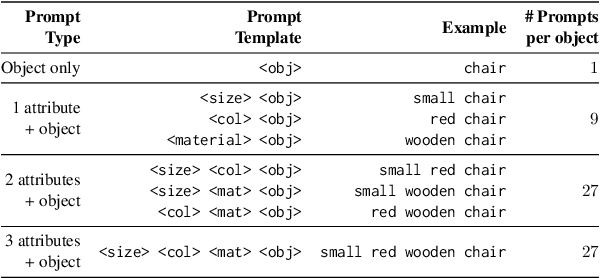
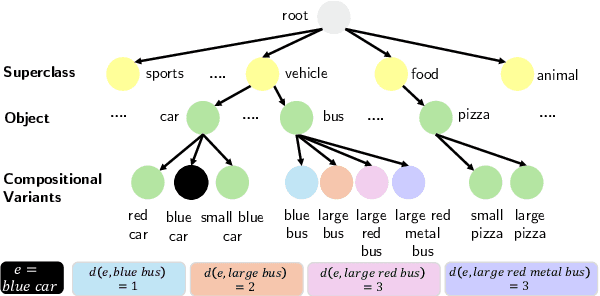

Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of Concept Erasure Techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired ``target'' concepts specified by the user, while preserving the ability to synthesize high-quality images of the remaining concepts. In this work, we demonstrate that CETs can be easily circumvented and present several side effects of concept erasure. For a comprehensive measurement of the robustness of CETs, we present Side Effect Evaluation (\see), an evaluation benchmark that consists of hierarchical and compositional prompts that describe objects and their attributes. This dataset and our automated evaluation pipeline quantify side effects of CETs across three aspects: impact on neighboring concepts, evasion of targets, and attribute leakage. Our experiments reveal that CETs can be circumvented by using superclass-subclass hierarchy and semantically similar prompts, such as compositional variants of the target. We show that CETs suffer from attribute leakage and counterintuitive phenomena of attention concentration or dispersal. We release our dataset, code, and evaluation tools to aid future work on robust concept erasure.
If Pigs Could Fly... Can LLMs Logically Reason Through Counterfactuals?
May 28, 2025Large Language Models (LLMs) demonstrate impressive reasoning capabilities in familiar contexts, but struggle when the context conflicts with their parametric knowledge. To investigate this phenomenon, we introduce CounterLogic, a dataset containing 1,800 examples across 9 logical schemas, explicitly designed to evaluate logical reasoning through counterfactual (hypothetical knowledge-conflicting) scenarios. Our systematic evaluation of 11 LLMs across 6 different datasets reveals a consistent performance degradation, with accuracies dropping by 27% on average when reasoning through counterfactual information. We propose Self-Segregate, a prompting method enabling metacognitive awareness (explicitly identifying knowledge conflicts) before reasoning. Our method dramatically narrows the average performance gaps from 27% to just 11%, while significantly increasing the overall accuracy (+7.5%). We discuss the implications of these findings and draw parallels to human cognitive processes, particularly on how humans disambiguate conflicting information during reasoning tasks. Our findings offer practical insights for understanding and enhancing LLMs reasoning capabilities in real-world applications, especially where models must logically reason independently of their factual knowledge.
Ranking Free RAG: Replacing Re-ranking with Selection in RAG for Sensitive Domains
May 21, 2025Traditional Retrieval-Augmented Generation (RAG) pipelines rely on similarity-based retrieval and re-ranking, which depend on heuristics such as top-k, and lack explainability, interpretability, and robustness against adversarial content. To address this gap, we propose a novel method METEORA that replaces re-ranking in RAG with a rationale-driven selection approach. METEORA operates in two stages. First, a general-purpose LLM is preference-tuned to generate rationales conditioned on the input query using direct preference optimization. These rationales guide the evidence chunk selection engine, which selects relevant chunks in three stages: pairing individual rationales with corresponding retrieved chunks for local relevance, global selection with elbow detection for adaptive cutoff, and context expansion via neighboring chunks. This process eliminates the need for top-k heuristics. The rationales are also used for consistency check using a Verifier LLM to detect and filter poisoned or misleading content for safe generation. The framework provides explainable and interpretable evidence flow by using rationales consistently across both selection and verification. Our evaluation across six datasets spanning legal, financial, and academic research domains shows that METEORA improves generation accuracy by 33.34% while using approximately 50% fewer chunks than state-of-the-art re-ranking methods. In adversarial settings, METEORA significantly improves the F1 score from 0.10 to 0.44 over the state-of-the-art perplexity-based defense baseline, demonstrating strong resilience to poisoning attacks. Code available at: https://anonymous.4open.science/r/METEORA-DC46/README.md