 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide Effects of Erasing Concepts from Diffusion Models
Aug 20, 2025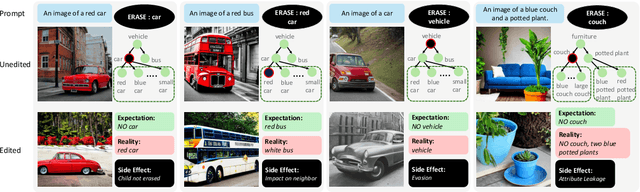
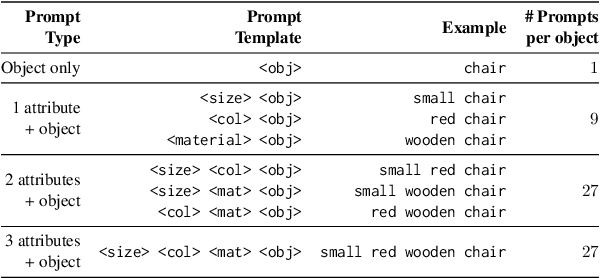
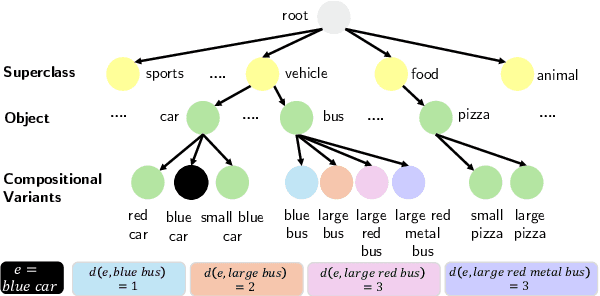

Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of Concept Erasure Techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired ``target'' concepts specified by the user, while preserving the ability to synthesize high-quality images of the remaining concepts. In this work, we demonstrate that CETs can be easily circumvented and present several side effects of concept erasure. For a comprehensive measurement of the robustness of CETs, we present Side Effect Evaluation (\see), an evaluation benchmark that consists of hierarchical and compositional prompts that describe objects and their attributes. This dataset and our automated evaluation pipeline quantify side effects of CETs across three aspects: impact on neighboring concepts, evasion of targets, and attribute leakage. Our experiments reveal that CETs can be circumvented by using superclass-subclass hierarchy and semantically similar prompts, such as compositional variants of the target. We show that CETs suffer from attribute leakage and counterintuitive phenomena of attention concentration or dispersal. We release our dataset, code, and evaluation tools to aid future work on robust concept erasure.
Improving Shift Invariance in Convolutional Neural Networks with Translation Invariant Polyphase Sampling
Apr 11, 2024Downsampling operators break the shift invariance of convolutional neural networks (CNNs) and this affects the robustness of features learned by CNNs when dealing with even small pixel-level shift. Through a large-scale correlation analysis framework, we study shift invariance of CNNs by inspecting existing downsampling operators in terms of their maximum-sampling bias (MSB), and find that MSB is negatively correlated with shift invariance. Based on this crucial insight, we propose a learnable pooling operator called Translation Invariant Polyphase Sampling (TIPS) and two regularizations on the intermediate feature maps of TIPS to reduce MSB and learn translation-invariant representations. TIPS can be integrated into any CNN and can be trained end-to-end with marginal computational overhead. Our experiments demonstrate that TIPS results in consistent performance gains in terms of accuracy, shift consistency, and shift fidelity on multiple benchmarks for image classification and semantic segmentation compared to previous methods and also leads to improvements in adversarial and distributional robustness. TIPS results in the lowest MSB compared to all previous methods, thus explaining our strong empirical results.
SeeBel: Seeing is Believing
Dec 18, 2023Semantic Segmentation is a significant research field in Computer Vision. Despite being a widely studied subject area, many visualization tools do not exist that capture segmentation quality and dataset statistics such as a class imbalance in the same view. While the significance of discovering and introspecting the correlation between dataset statistics and AI model performance for dense prediction computer vision tasks such as semantic segmentation is well established in the computer vision literature, to the best of our knowledge, no visualization tools have been proposed to view and analyze the aforementioned tasks. Our project aims to bridge this gap by proposing three visualizations that enable users to compare dataset statistics and AI performance for segmenting all images, a single image in the dataset, explore the AI model's attention on image regions once trained and browse the quality of masks predicted by AI for any selected (by user) number of objects under the same tool. Our project tries to further increase the interpretability of the trained AI model for segmentation by visualizing its image attention weights. For visualization, we use Scatterplot and Heatmap to encode correlation and features, respectively. We further propose to conduct surveys on real users to study the efficacy of our visualization tool in computer vision and AI domain. The full system can be accessed at https://github.com/dipta007/SeeBel
RFC-Net: Learning High Resolution Global Features for Medical Image Segmentation on a Computational Budget
Feb 13, 2023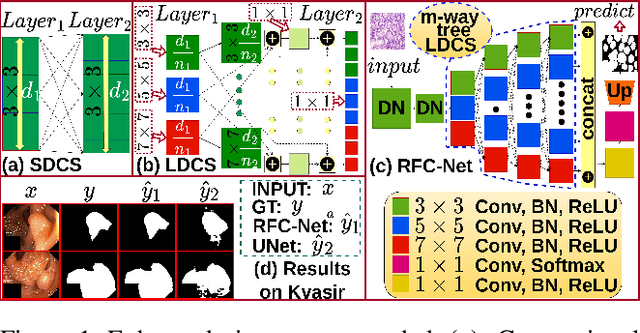

Learning High-Resolution representations is essential for semantic segmentation. Convolutional neural network (CNN)architectures with downstream and upstream propagation flow are popular for segmentation in medical diagnosis. However, due to performing spatial downsampling and upsampling in multiple stages, information loss is inexorable. On the contrary, connecting layers densely on high spatial resolution is computationally expensive. In this work, we devise a Loose Dense Connection Strategy to connect neurons in subsequent layers with reduced parameters. On top of that, using a m-way Tree structure for feature propagation we propose Receptive Field Chain Network (RFC-Net) that learns high resolution global features on a compressed computational space. Our experiments demonstrates that RFC-Net achieves state-of-the-art performance on Kvasir and CVC-ClinicDB benchmarks for Polyp segmentation.
Mitigating domain shift in AI-based tuberculosis screening with unsupervised domain adaptation
Nov 09, 2021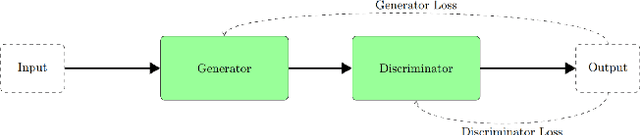
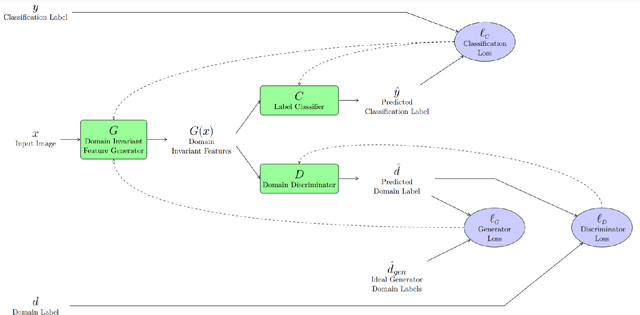
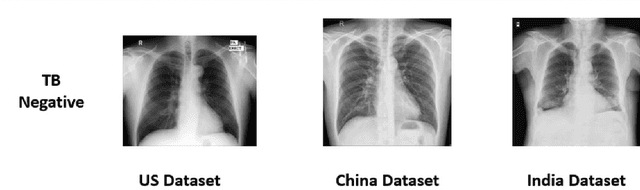
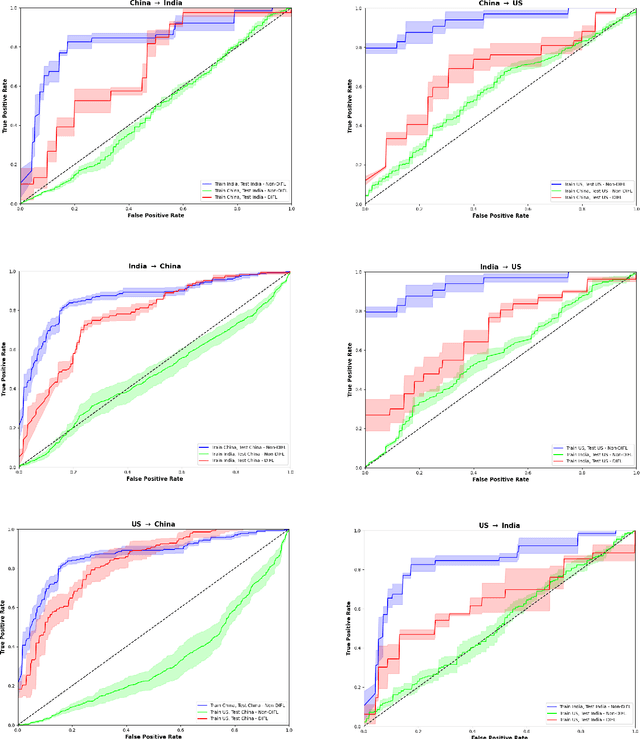
We demonstrate that Domain Invariant Feature Learning (DIFL) can improve the out-of-domain generalizability of a deep learning Tuberculosis screening algorithm. It is well known that state of the art deep learning algorithms often have difficulty generalizing to unseen data distributions due to "domain shift". In the context of medical imaging, this could lead to unintended biases such as the inability to generalize from one patient population to another. We analyze the performance of a ResNet-50 classifier for the purposes of Tuberculosis screening using the four most popular public datasets with geographically diverse sources of imagery. We show that without domain adaptation, ResNet-50 has difficulty in generalizing between imaging distributions from a number of public Tuberculosis screening datasets with imagery from geographically distributed regions. However, with the incorporation of DIFL, the out-of-domain performance is greatly enhanced. Analysis criteria includes a comparison of accuracy, sensitivity, specificity and AUC over both the baseline, as well as the DIFL enhanced algorithms. We conclude that DIFL improves generalizability of Tuberculosis screening while maintaining acceptable accuracy over the source domain imagery when applied across a variety of public datasets.
Optic-Net: A Novel Convolutional Neural Network for Diagnosis of Retinal Diseases from Optical Tomography Images
Oct 13, 2019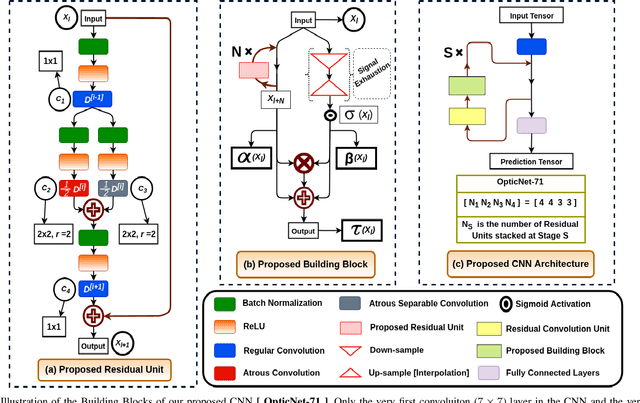
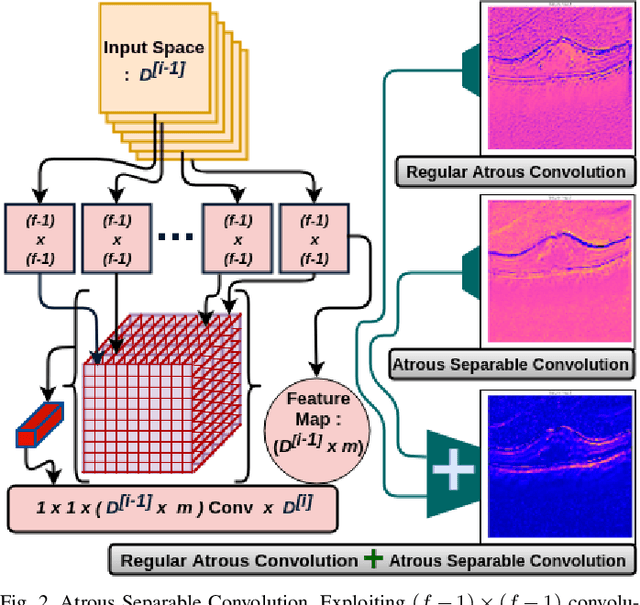
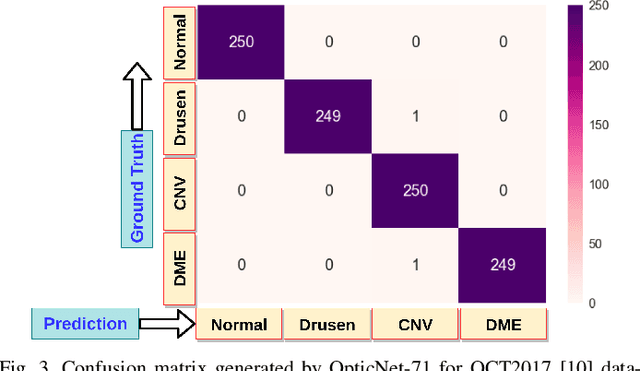
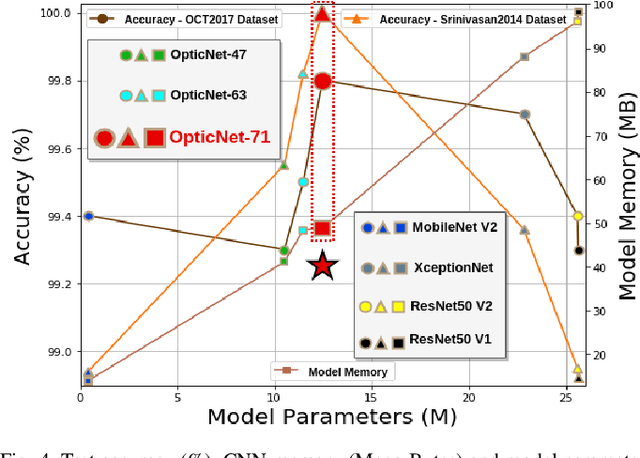
Diagnosing different retinal diseases from Spectral Domain Optical Coherence Tomography (SD-OCT) images is a challenging task. Different automated approaches such as image processing, machine learning and deep learning algorithms have been used for early detection and diagnosis of retinal diseases. Unfortunately, these are prone to error and computational inefficiency, which requires further intervention from human experts. In this paper, we propose a novel convolution neural network architecture to successfully distinguish between different degeneration of retinal layers and their underlying causes. The proposed novel architecture outperforms other classification models while addressing the issue of gradient explosion. Our approach reaches near perfect accuracy of 99.8% and 100% for two separately available Retinal SD-OCT data-set respectively. Additionally, our architecture predicts retinal diseases in real time while outperforming human diagnosticians.
Total Recall: Understanding Traffic Signs using Deep Hierarchical Convolutional Neural Networks
Oct 26, 2018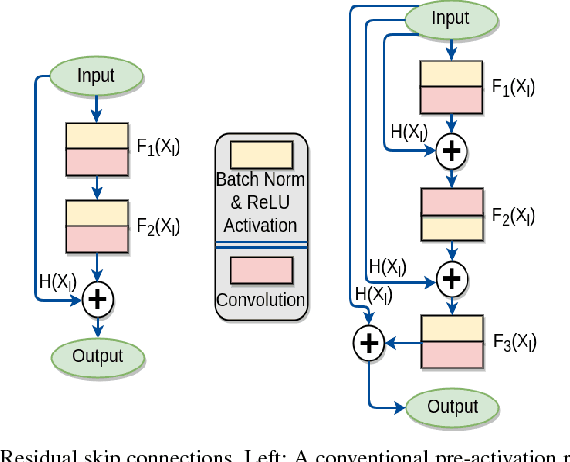
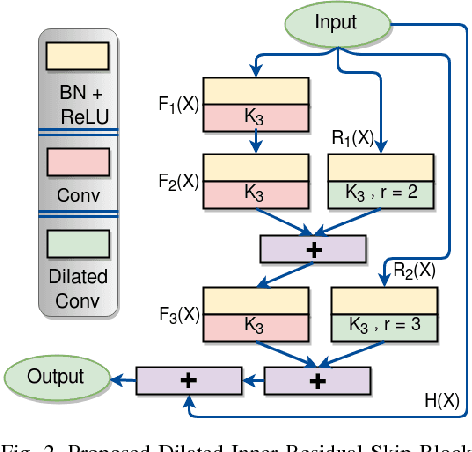
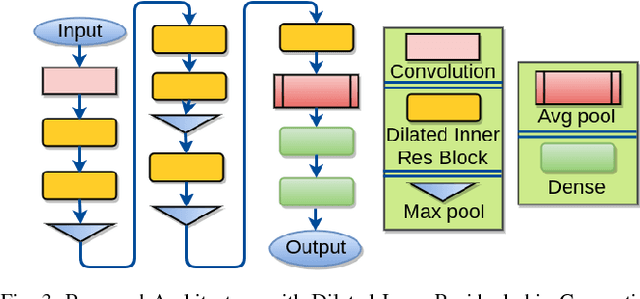

Recognizing Traffic Signs using intelligent systems can drastically reduce the number of accidents happening world-wide. With the arrival of Self-driving cars it has become a staple challenge to solve the automatic recognition of Traffic and Hand-held signs in the major streets. Various machine learning techniques like Random Forest, SVM as well as deep learning models has been proposed for classifying traffic signs. Though they reach state-of-the-art performance on a particular data-set, but fall short of tackling multiple Traffic Sign Recognition benchmarks. In this paper, we propose a novel and one-for-all architecture that aces multiple benchmarks with better overall score than the state-of-the-art architectures. Our model is made of residual convolutional blocks with hierarchical dilated skip connections joined in steps. With this we score 99.33% Accuracy in German sign recognition benchmark and 99.17% Accuracy in Belgian traffic sign classification benchmark. Moreover, we propose a newly devised dilated residual learning representation technique which is very low in both memory and computational complexity.